







背景介绍
因为python中有eval()方法,可以很方便的将一些字符串类型与字典等数据结构之间进行转换, 所以公司的数据处理同事在保存一些特殊数据时就直接将字典的字符串保存在数据库中。
在程序中读取该字段,再使用eval()将其转成字典进行处理。 由于这样比较方便,节省了解析的成本,所以广泛被公司内部采用。
后来,随着公司业务发展,这类型的字段长度也随之变长,由原先的几十上百字节到现在的百万字节(跨度很大,既定事实),发现处理程序的处理速度也降了下来,经过一系列的性能
定位发现,eval方法在转换大长度的字符串时耗时严重。
分析算法
使用相同的数据结构,对比eval与json转字符串转字典方面的性能。
#coding:utf8
import sys,json
from time import time
a = {}
for i in range(int(sys.argv[1])):
a[i+1914246144] = (24, 31620, 3.874021, 870569, 700552)
#转成字符串
dict_str = repr(a)
t1 = time()
d = eval(dict_str)
t2 = time()
print "eval cost time is %f." % (t2 -t1)
#转成json类型的字符串
dict_json = json.dumps(a)
t1 = time()
d = json.loads(dict_json)
t2 = time()
print "json cost time is %f." % (t2 -t1)测试结果:
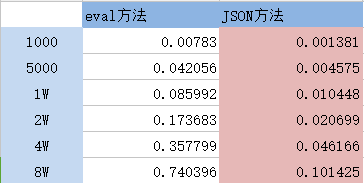
注:第一列代表字典的items数量,后面的单位为秒。
根据以上可看出:
在长字符串转换字典方面,eval比json的方法,慢7~9倍左右。
另外,根据笔者查询资料,eval一般是执行字符串类型的python语句使用,而且也会有一些风险,应该尽量避免滥用,有跟我类似苦恼的朋友,希望看完本篇介绍能有点小小的收获吧。
一般外部数据输入的格式,尽量使用通用的数据格式,如 xml、json等,方便语言扩展,妙处多多。















 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









