







日常工作中, 后端常用的中间件有这么几种: 数据库/缓存/消息队列/搜索引擎, 这几种中间件在典型架构中的组合使用方式如下:

Arch
这几种中间件的常用实现有: MySQL/Redis/RocketMQ or Kafka/ElasticSearch, 那么通过每一种中间件的学习,我们经常有这种感觉: 这些东西有很多相似的地方,原理很相似,通过抽象总结, 我梳理了以下的通用中间件模型:
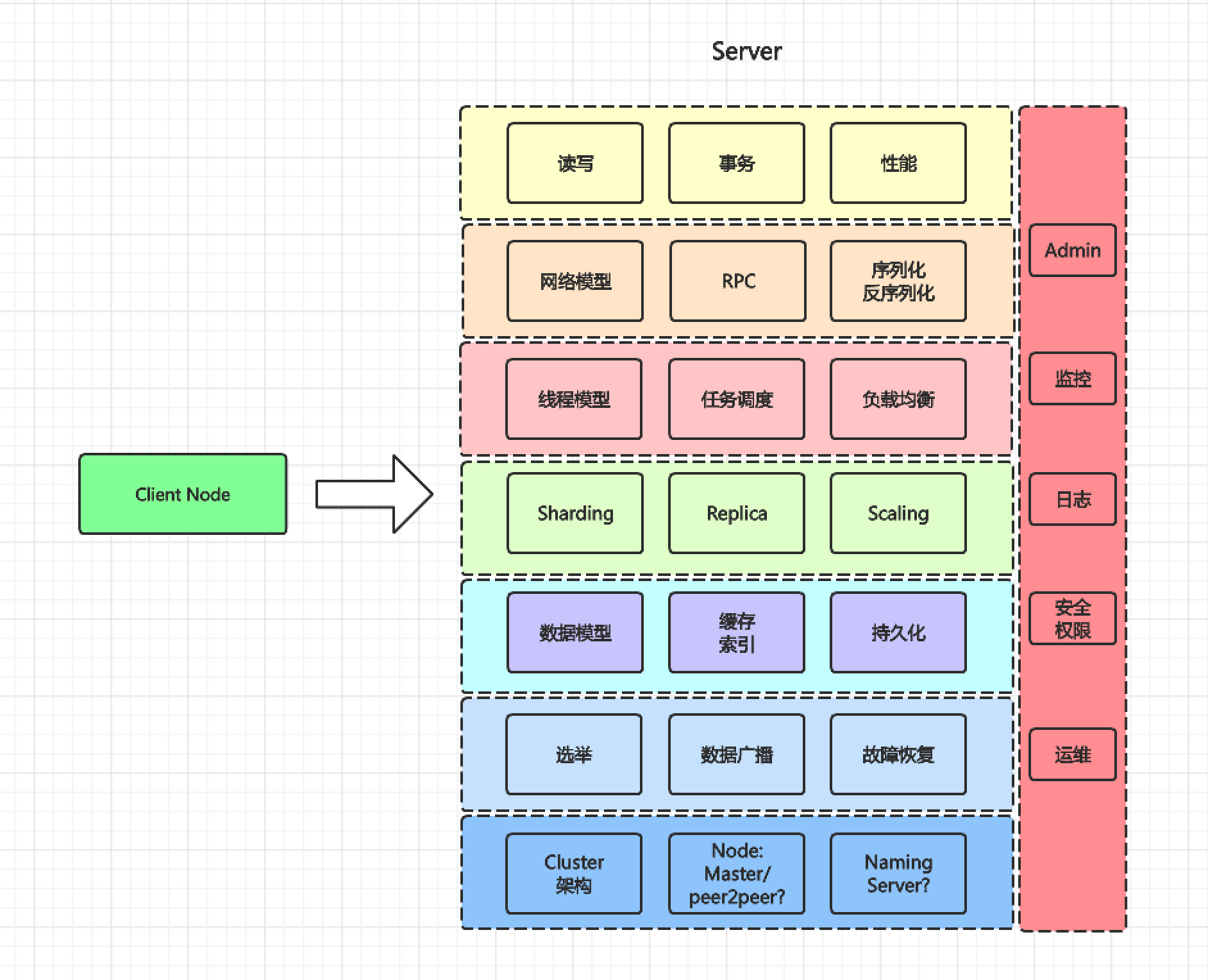
跳出来,在极大的尺度上考虑,中间件层可以抽象为一个全局的分布式存储系统, 在理想的系统里,
大量用户带来的流量带来数据,通过全局的存储系统增删查改; 然而现实是----不存在这种系统,因为不同的场景对数据的要求不一样: 有的读频繁,有的是写频繁等等等等, 不同的场景诞生出不同的中间件,但从全局的抽象层面,他们的共性如图所示:
- 客户端连接 ;
- 流量的读写场景,读写比例是怎样的? 是否需要事务支持? 对性能吞吐要求如何?
- 客户端连接服务端需要网络模型支持,如RPC框架, 以及序列化/反序列化;-->一般是IO多路复用;
- 网络模型建立连接后,任务如何分发,如何分发到不同的worker或数据node?
- 数据的分片? 副本? 如何扩展,扩展后如何重新分配数据?
- 技术的数据模型? 数据结构是B+树还是LSM树? 是否用到了缓存/索引? 是否持久化, --> 底层本质: 复制状态机,WAL;
- 如果模型是主从模型的话,节点如何选举出master? 写数据时如何同步到所有节点(数据广播)?master节点,普通节点挂了如何恢复? --> 这块一般涉及到分布式共识算法,如Paxos,Raft,Zab等;
- cluster集群架构是Master-Slav模式还是Peer 2Peer 模式? 是否有NamingServer协调? -->一般自己实现NamingServer或者使用分布式协调基础中间件Zookeeper;
纵向: 中间件是否有管理端?如何监控和运维?安全和权限管理?
在这之上, 考虑在高性能/高可用/高扩展不同维度的要求下,模型如何应对.
以上是中间件模型的通用抽象,可以从全局指导学习和实践.















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









