







 本文详细解读了Hive SQL的Select查询语句,包括语法树、基础查询、高阶查询技巧(如ORDER BY、CLUSTER BY、DISTRIBUTE BY/SORT BY)、UNION操作、子查询和公用表表达式。还介绍了JOIN连接查询的规则及各种连接类型,以及优化策略。
本文详细解读了Hive SQL的Select查询语句,包括语法树、基础查询、高阶查询技巧(如ORDER BY、CLUSTER BY、DISTRIBUTE BY/SORT BY)、UNION操作、子查询和公用表表达式。还介绍了JOIN连接查询的规则及各种连接类型,以及优化策略。
1 DQL-Select查询数据
1.1 语法树
[WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
1.2 基础查询
-
ALL | DISTINCT选项指定是否应返回重复的行,默认值为ALL
注意:select distinct county,state 表示多个字段整体去重
-
where子句中禁止使用聚合函数:Where用于确定结果集,而聚合函数使用前提为结果集已确定,由此可以看出where先执行,group by后执行
-
分区裁剪:where子句或join中的on子句如果存在分区字段的过滤,则仅访问查询符合条件的分区,裁剪掉没必要访问的分区
-
group by 用于结合聚合函数,查询结果选择的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段,避免歧义
-
having子句,用以解决where无法使用聚合的问题,因为他在group by后执行,结果集已确定,所以having子句可以使用聚合函数
-
limit子句用于约束SELECT语句返回的行数,第一个参数偏移量从0开始
总结:执行顺序:from>where>group(含聚合)>having>order>select
提示:聚合语句要比having子句优先执行(这就是使用having的原因),而where子句在查询过程中执行优先级别优先于聚合语句(sum,min,max,avg,count)。
1.3 高阶查询
-
ORDER BY col_name [ASC|DESC] [NULLS FIRST|LAST]
1)对输出结果进行全局排序,底层只有一个reducetask执行
2)全局排序结果输出行数太多,排序时间过长,建议少使用order by或者搭配limit使用
-
CLUSTER BY col_name
1)set mapreduce.job.reduces =N;开启N个reducetask如果不手动设置,则Hive根据数据大小在编译期间自动分为随机组
2)使用hash散列根据分组字段对结果集分组,同样根据该字段来组内排序(只能正序)
3)CLUSTER BY因无法满足根据一字段分组,再根据另一字段排序,引出DISTRIBUTE BY 和SORT BY
-
DISTRIBUTE BY +SORT BY
1)DISTRIBUTE BY负责分,SORT BY负责分组内排序
2)分组和排序可以是不同的字段
3)CLUSTER BY=DISTRIBUTE BY +SORT BY(字段一样)
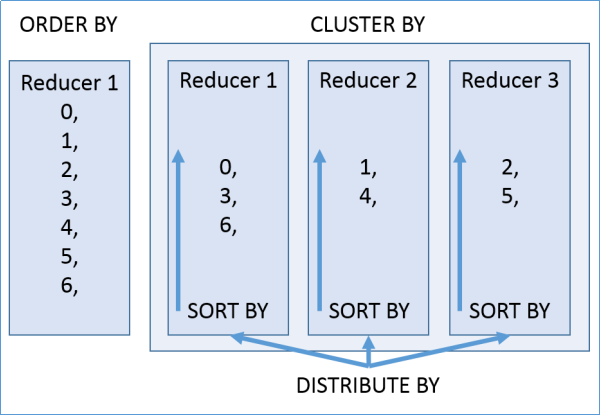
总结:
- group by 分组,将组内数据聚合为一行,且只能select分组字段和聚合结果,后接order by就只能对分组字段或聚合结果排序
- order by,只开启一个reduceTask,全局排序
- cluster by,开启reducetask个数=组数,分组但不聚合,组内只能升序,同一字段分且排序,该分组是按字段的哈希方法分组,比较随机,并不是分组字段的每个value各为一组
- distribute by+sort by,在不让reduce task个数冲突前提下,可以实现分和排序字段不同
- cluster by和distribute by+sort by多用于随机采样,分桶表join,ORC文件索引
1.4 UNION联合查询
select_statement UNION [ALL | DISTINCT] select_statement UNION [ALL | DISTINCT] select_statement ...
1)使用DISTINCT关键字与只使用UNION默认值效果一样,都会删除重复行
2)每个select_statement返回的列的数量和名称必须相同
3)如果想对单个select使用子句需要使用子查询,对整体使用子句则放在整体最后,如下
-- 针对单个select使用子句过滤或限制
SELECT sno,sname FROM (select sno,sname from student_local LIMIT 2) subq1
UNION
SELECT sno,sname FROM (select sno,sname from student_hdfs LIMIT 3) subq2;
-- 针对整体使用子句
select sno,sname from student_local
UNION
select sno,sname from student_hdfs
order by sno desc;
1.5 Subqueries子查询
-
from子句中子查询
1)必须给子查询一个名称
2)子查询返回结果中的列在外部查询中可用
-
where子句中子查询
分为不相关子查询和相关子查询
-- 不相关子查询,相当于IN、NOT IN,子查询只能选择一个列。 -- (1)执行子查询,其结果不被显示,而是传递给外部查询,作为外部查询的条件使用。 -- (2)执行外部查询,并显示整个结果。(子查询不需要起别名) SELECT * FROM student_hdfs WHERE student_hdfs.num IN (select num from student_local limit 2); -- 相关子查询,指EXISTS和NOT EXISTS子查询 -- 子查询的WHERE子句中支持对父查询的引用 SELECT A FROM T1 WHERE EXISTS (SELECT B FROM T2 WHERE T1.X = T2.Y);
1.6 公用表
- 公用表表达式(CTE)是一个临时结果集
- 从WITH子句中指定的简单查询派生而来的,该查询紧接在SELECT或INSERT关键字之前
-- 选择语句中的CTE
with q1 as (select sno,sname,sage from student where sno = 95002)
select *
from q1;
-- from风格
with q1 as (select sno,sname,sage from student where sno = 95002)
from q1
select *;
-- chaining CTEs 链式
with q1 as ( select * from student where sno = 95002),
q2 as ( select sno,sname,sage from q1)
select * from (select sno from q2) a;
-- union案例
with q1 as (select * from student where sno = 95002),
q2 as (select * from student where sno = 95004)
select * from q1 union all select * from q2;
--视图,CTAS和插入语句中的CTE
-- insert
create table s1 like student;
with q1 as ( select * from student where sno = 95002)
from q1
insert overwrite table s1
select *;
select * from s1;
-- ctas
create table s2 as
with q1 as ( select * from student where sno = 95002)
select * from q1;
-- view
create view v1 as
with q1 as ( select * from student where sno = 95002)
select * from q1;
select * from v1;
2 join连接查询
2.1 规则树
join_table:
table_reference [INNER] JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)
table_reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )
join_condition:
ON expression
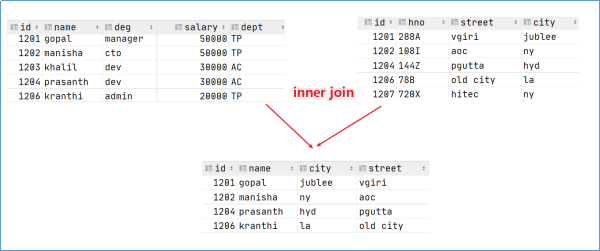
2.2 inner join
- 内连接inner join,inner可省略
- 隐式连接,from子句连接以逗号分隔的表列表
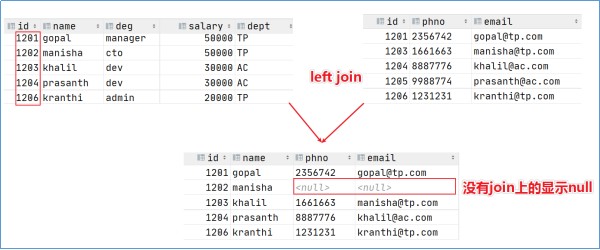
2.3 left join
- 左外连接left outer join,outer可省略
- 左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回
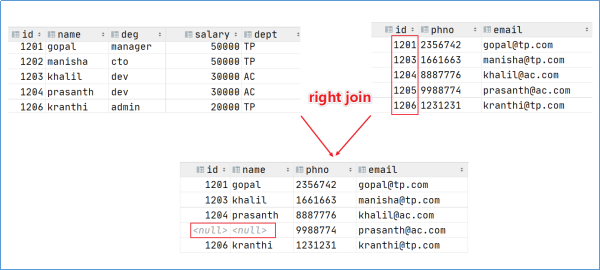
- right join同理
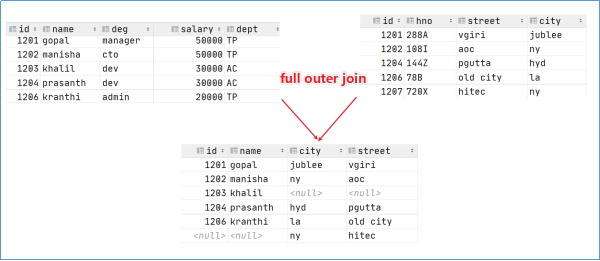
2.4 full outer join
- full outer join 全外连接/外连接,outer可省略
- 包含左、右两个表的全部行,不管另外一边的表中是否存在与它们匹配的行
2.5 left semi join
-
左半开连接,满足连接条件的情况下只返回左边表的记录
-
等价于inner join之后只返回左表的记录,只是比inner更高效
-
select * from employee e left semi join employee_address e_addr on e.id=e.addr.id
等价于
select e.* from employee e inner join employee_address e_addr on e.id=e_addr.id;
2.6 cross join
交叉连接crossjoin,就是无条件的inner join,后面可以跟where子句进行过滤,或者on条件过滤
2.7 注意事项
- on子句中允许使用复杂的连接表达式(and,<>)
- 同一查询中可以连接2个以上的表
- 多表连接时,如果每个表在联接子句中使用相同的列,则Hive将多个表上的联接转换为单个MR作业
- 多表连接,join时的最后一个表会通过reducer流式传输,并在其中缓冲之前的其他表,因此,将大表放置在最后有助于减少reducer阶段缓存数据所需要的内存
- 在join的时候,可以通过语法STREAMTABLE提示指定要流式传输的表。如果省略STREAMTABLE提示,则Hive将流式传输最右边的表。
- join在WHERE条件之前进行
- 如果除一个要连接的表之外的所有表都很小,则可以将其作为仅map作业执行(mr的mapjoin)

















 3610
3610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









