







参考
base64编码踩坑之身份证号模糊查询
mysql中Base64编码与解码
使用场景
微信小程序需要将用户昵称存储到数据库中,但由于昵称中存在emoji表情。mysql需要修改编码格式(库,表,字段)才可以存储,嫌麻烦并不想在数据库已经建好的基础上再修改编码。所以就用Base64编码后存储,需要用的时候从数据库查询出来再进行解码。
final Base64.Decoder decoder = Base64.getDecoder();
final Base64.Encoder encoder = Base64.getEncoder();
/**
* 对前台传过来的带有emoji的昵称进行编码
* @param emoji
* @return String
* @throws UnsupportedEncodingException
*/
public String emoji2String(String emoji) throws UnsupportedEncodingException{
byte[] emojiByte = emoji.getBytes("UTF-8");
return encoder.encodeToString(emojiByte);
}
/**
* 将数据库查询出来的微信昵称进行解码成含有emoji的形式
* @param String
* @return emoji
*/
public String string2Emoji(String str) throws IllegalArgumentException{
return new String(decoder.decode(str));
}
挖坑
有个应用场景是需要对昵称进行模糊查询。要查询的对象是汉字,数据库中存的是编码后的字符串。
不能直接进行模糊查询。就有了以下的实验。
// 测试编码
@Test
public void emoji2StringTest(){
//String emoji = "🍋";
//String emoji = "🎰🚣🛀🎫🏆⚽⚾🏀🏈🏉";
//String emoji = "哈哈🍋";
//String emoji = "お金持ち";
//String emoji = "お金持ち🍋啊哈哈哈哈哈哈啊啊🍋啊啊啊啊啊啊啊🍋集聚地撒花饭店烧烤老🍋妇女都是积分ID管理费可爱";
//String emoji = "12345678901234567890123456789012";
String[] arr = {"最美一家人","不美一家人","最丑一家人","最美二家人","最美一国人","最美一家猪","最美","一家人"," "," 美一家人","最 一家人","最美 家人","最美一 人","最美一家 "};
for(String emoji : arr){
try {
String result = emojiTranslate.emoji2String(emoji);
System.out.println("编码结果:"+result);
} catch (UnsupportedEncodingException e) {
System.out.println("编码失败");
e.printStackTrace();
}
}
}
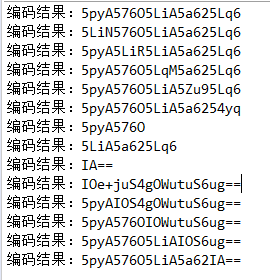
测试结果如上,乍看是有规律的。但是这个规律的明显程度还不足以让我去研究。何况测试还没加上emoji。所以,换个思路,科学求助。
填坑
参照最开始的链接里所讲的内容(可以点击查看详细,里面还有Base64的编码原理),使用mysql支持base64编码/解码的聚合函数,版本至少是5.6。
解码
SELECT * FROM familytab WHERE FROM_BASE64(familyName) LIKE '%🏀🏈🏉%';
编码
SELECT * FROM familytab WHERE TO_BASE64(familyName) LIKE '%一家人%';














 990
990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









