







 本文详细介绍了Python中的各种基础数据类型,包括变量的概念、数字、字符串、列表、元组、字典和集合等,以及这些数据类型的常见操作方法。
本文详细介绍了Python中的各种基础数据类型,包括变量的概念、数字、字符串、列表、元组、字典和集合等,以及这些数据类型的常见操作方法。
变量
python中以数据为主体,不同的数据存储在不同的地址空间中,而变量名只是地址空间的一个标签,通过这个标签可以访问到这个内存,从而拿到内存中存储的数据。并不是说会为该变量分配一个固定的地址空间,而对变量赋值就是向该地址空间中添加不同的数据。如:
#ecoding:utf-8
a=123
b=123
print(id(a))
print(id(b))
a=345
print(id(a))三次输出的结果如下;
140710290416624
140710290416624
140710290448232
从中可以看出前两次是相同的,这是因为a ,b都是同一个内存块(该内存块中存储的是123)的标签,因为345与123存储在不同的内存块中,所以最后一个结果与前面不同。
由于变量的标签特性,可以看出python中变量与java中的有如下不同:
1,定义变量时不需要指定变量类型。它只是一块内存的一个标签,该内存段中存储的值早已注定,所以不需要用变量来确定该内存段中应该存储什么类型的数据。
2,同一个变量,可以赋值为不同的类型。赋值不同的类型时,变量只不过为不同内存块的标签而已。
数字
数字可以分为整型(int),长整型(long),浮点型(float)与复数型(complex)。
在数学中,用i来表示复数,但在python中用j表示复数。如:
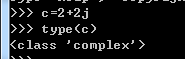
例子中的c就是一个实部与虚部都为2的复数,它的类型为complex。
字符串
支持单引号、双引号以及三重引号而已。 单引号与双引号没有啥区别,三重引号可以将字符串中的特殊格式保留下来(比如换行等)。
字符串可以看成一个字符数组,可以通过下标的形式取出某一个字符或某一范围内的子串。
a='abcdefg'
print(a[2])
print(a[1:5])第一个输出的为c,第二个输出的为bcde。其中第二个a[1:5]表示从a[1]取到a[4],截取a中的一个子串。
a[m:n]:表示获取下标为[m,n)的子串。其中m,n可为负数,-1表示字符串的最后一个字符。
a[m:n:step]:表示获取下标为[m,n)的子串,但每一步的步长为step,步长为正则取值方向为从左往右,步长为负负则从右往左。m,n,step都可以为负数。以上面例子为例,a[1:5:2]的输出结果为bd,b的下标为1,走2步后就是d,d再走一个步长就超出了5的范围,所以不再输出。
对于单双引号的选择:字符串内部有单引号时则最外面使用双引号;字符串内部有双引号时,则最外面使用单引号;如果单双引号都有,则使用三引号。
转义与raw字符串
字符串的转义与java中类似,都是以\开头。\n表示换行,\t表示制表符等。例如
>>> print("\aaaa")
aaa如果想输出\aaaa,则需要对第一个\进行转义:print("\\aaaa")。
如果一个字符串中需要转义的太多,可以使用r(raw的缩写)开头,则字符串就会按原文输出,不会进行转义。如下:
>>> print("fadfas\nfdasf")
fadfas
fdasf
>>> print(r"fadfas\nfdasf")
fadfas\nfdasf通过r表示字符串内中都是原始字符串,不需要进行转义。
常用方法
capitalize:将字符串首字母转换为大写。
replace:替换指定的内容。可以指定替换的个数。replace(old,new,count)基本的count指的就是将几个old替换成new。也可以不传入count,则所有的old都被替换成new。
split:切割字符串。可指定切割次数。 S.split(sep=None, maxsplit=-1)。
strip:移除字符串开头和结尾处指定的字符。默认时移除空白字符(换行,制表符,空格等),也可自己指定。
s = ' abcdefxxxf\t'
print('---'+s.strip()+"--") # ---abcdefxxxf-- 移除两端的空白字符
s1 = '\rfdafa\n'
print('---'+s1.strip()+"--") # ---fdafa--
s1 = 'xxxxxfdafayyyyay'
print('---'+s1.strip('xya')+"--") # ---fdaf--从前两个可以看出,移除了空白字符。从后一个可以看出,移除了指定的字符——将要移除的字符组成字符串。
序列
字符串,元组,列表都是序列。每一个序列都具有如下操作:
1,通过下标获取指定位置的元素。
2,通过a[m:n:step]形式获取序列的子序列。
常用的操作序列的方法有:
len():获取序列的长度。如a='abc',则len(a)返回3。
+:将两个序列拼接。
*:表示将序列重复多少次。如a='abc',则a*5值为abcabcabcabcabc
in:判断某一个元素是否在序列中。比如a='abc',则'cab' in a*5返回的结果就是True。
not in:与in相反,判断某个元素不在序列中。
max(),min():返回序列中最大值和最小值。
cmp():比较两个序列是否相等。返回0表示相等,返回值大于0第一个参数大于第二个参数,否则小于。
元组(tuple)
用()进行定义,元素之间用逗号隔开,并且元素的类型可以不相同,元组的值不可改变。
空元组就是一个空括号,一个元素的元组,元素后面也必须跟逗号。如:
a=() # 空元组 如果取a[0]则报IndexError: tuple index out of range
b=(1,) # 只有一个元素的元组,必须加最后面的逗号
c=(2,'abs') # 多个元素的元组
print(b[0]) # 输出1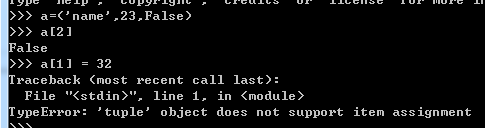
可以将元组进行拆分,将元组的元素值分别赋值给不同的变量。如:
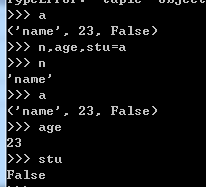
其中a,age,stu=a就是将元组a进行拆分,使其各个元素分别赋值给a,age,stu。
与之类似,可以按元组的方式对多个变量进行赋值。如:
a,b,c=1,'ab',True列表(list)
用[]表示列表,并且列表的元素是可以修改的。
1,定义一个元素时,可以不加元素后面的逗号。
2,列表可变。可以通过下标对列表中的某个位置上的元素进行修改。如下:
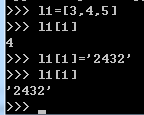
对l1[1]进行修改,但l1的位置并不变化 ,可以通过id()进行查看。
3,也可以对列表进行拆解,与元组类似。
常用方法
append():向列表中追加一个元素,该元素的下标为列表最后一个下标加1 。直接用列表变量调用该方法即可。
remove():删除列表中指定的元素。如果有多个,则删除第一个出现的。直接用列表变量进行调用。
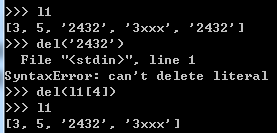
del():删除列表指定位置处的元素。它不同于remove(),它是系统方法,不需要用列表变量进行调用,直接调用即可。而且它删除的是下标指定的元素,并不一定是第一个出现的元素。如下:
字典(dict)
唯一一个映射类型,类似于HashMap,可变。用{}进行创建,字典是无序的,Key值按其hash值进行排列。如下:
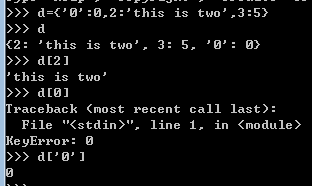
第一行创建一个字典,不同的键值对之间用逗号隔开,键值用冒号相连。第二行输出字典,可以发现元素的顺序与输入时的顺序不一样;第三行通过key值获取对应的value值,d[2]中的2指的是Key值,而不是下标;d[0]就会报错,因为d中没有key值为0的value;第四行是正确的,因为有key值为字符串0。
由于字典的key值是不可变的,所以字典的key值不能为list,但可以是基本数据类型,string,元组等。如
m = {'a':12,324:'string'}
m[('tuple')] = ('this','is','tuple')
m[('list')] = ['from','list']
m[['list']] = ['from','list'] # TypeError: unhashable type: 'list'
for x,y in m.items():
print x,y第四句会报错,因为第四句定义的key值是list,而list是可变的。
字典的value值可以是方法名,如:
def add(a1,a2,*b,**c): # **表示c是一个字典
print(a1+a2)
def less(a1,a2,*b,**c):
print(a1-a2)
def multiply(a1,a2,*b,**c): # **表示c是一个字典
print(a1*a2)
def division(a1,a2,*b,**c):
print(a1/a2)
operator = {"+":add,"-":less,"*":multiply,"/":division}
print(operator["+"])
operator["*"](5,3) # 15常用方法
其对应的类为dict,可以通过help(dict)查看所有的方法以及注释。
keys():获取字典中的所有key值。
values():获取字典中的所有value值。
items():以列表形式返回字典的key,value值。
xx in dict:判断字典dict中是否有key值为xx的键值对。
for xx in dict: :遍历字典的key值。要注意的是dict后面一定有一个冒号,它表示一个代码块开始。如:
>>> for k in dict:
dict[key]=value:如果字典中没有该key,则向该字典中添加该键值对;如果有该key,则修改该Key对应的value。
del:同列表中一样,用于删除字典的元素。如:del(dict[key])则删除字典中键值为key的键值对。key值指的是dict中的键,有可能是字符串,有可能是数字等;del dict则会删除整个字典dict。
pop():删除字典中指定key的键值对,并将对应的value返回。是字典内容的方法,因此需要使用字典变量调用。如dict.pop(key)。
clear():清空整个字典的内容,但不删除字典本身,只是将它变成一个空字典。del dict后,dict就变成了一个未定义的变量,而dict.clear()后dict还是一个变量,只是没有内容。
get(key,defaultValue):获取key对应的value,如果该key不存在就返回defaultValue——该值可以不定义。它与dict[key]的区别在于,get()方法在key不存在的时候也不会保错,但dict[key]会。
set
与java中的set集合一样,无序,元素不重复。可以对set集合做数学上的交集,并集运行。如下:
s = set((1,3,2)) # 创建一个set,set()方法需要的是一个iterable
s2 = set([2,4,5])
print s|s2 # 1,2,3,4,5 取并集
print s&s2 # 2 取交集由于set要保证所有元素的唯一性,所以set中的元素必须是不可变的。如:
s = set((1,23))
s.add((2,5,7))
for x in s:
print x # 依次输出1,(2,5,7),23。如果将add中的元组改为list,则会报错(TypeError: unhashable type: 'list')。因为list是可变的。
常用方法
add():向set集合中添加一个元素,如果元素存在则不进行任何操作。
remove():从set集合中移除掉一个元素。
pop():移除第一个元素。
union(set1,set2,…):取set并集,并将结果以一个新set返回。
difference(…):取差集,并将结果以一个新set返回。如:
s = set((1,3,2))
s1 = set((3,4,5))
s2 = set((8,2,10))
print s.difference(s1,s2) # 1 s-s1-s2后的元素只有1
比较
list:有序可重复
set:无序不可重复
dict:键值对形式
空值
python中空值用None表示。

















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









