







| Minimum Threshold | 0 | 1022 | 1/4 x queue size |
| Maximum Threshold | 1 | 1023 | 1/2 x queue size |
| Inverse Mark Probability | 1 | 255 | 10 |
| EWMA Filter Weight | 1 | 12 | 9 |
这些参数的含义在后续章节中将会详细解释。这些参数按照其指定给丢弃器模块API的格式,对应于思科*在其RED实现中所使用的格式。最小和最大阈值参数以数据包数量的形式提供给丢弃器模块。标记概率参数以逆值指定,例如,标记概率参数值为10对应于标记概率为1/10(即,10个数据包中将丢弃1个)。EWMA滤波器权重参数以逆对数值指定,例如,滤波器权重参数值为9对应于滤波器权重为1/29。
21.3.2 入队操作
在图21.9中所示的示例中,q(实际队列大小)是输入值,avg(平均队列大小)和count(自上次丢弃以来的数据包数量)是运行时值,decision是输出值,其余数值为配置参数。
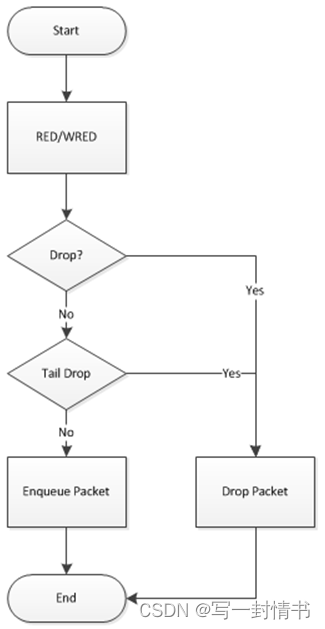
图 21.8:通过滴管的流量
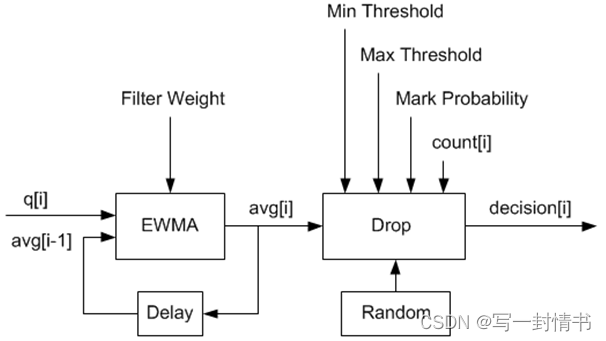
图 21.9:通过 Dropper 的数据流示例
EWMA滤波器微块
EWMA滤波器微块的目的是对队列大小值进行滤波,以平滑“突发”流量所导致的瞬态变化。输出值为平均队列大小,从而更稳定地反映了队列当前的拥塞水平。
EWMA滤波器具有一个配置参数,即滤波器权重,它决定了平均队列大小输出对实际队列大小变化的快慢响应。滤波器权重值越高,平均队列大小对实际队列大小的变化响应就越快。
队列非空时的平均队列大小计算
EWMA滤波器的定义如下方程所示:
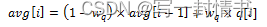
其中:
- avg = 平均队列大小
- wq = 滤波器权重
- q = 实际队列大小
- R = 固定整数,表示除法的位移量
队列为空时的平均队列大小计算
当队列为空时,EWMA滤波器不会读取时间戳,而是假定入队操作会相当定期地发生。当队列变为空时,需要进行特殊处理,因为队列可能短时间或长时间为空。队列变为空时,平均队列大小应该逐渐衰减到零,而不是突然降为零或停留在上次计算的值上。当在空队列上入队一个数据包时,平均队列大小使用以下公式计算:
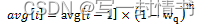
其中:
- m = 在队列为空时可能发生的入队操作数
在dropper模块中,m被定义为:
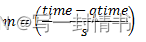
其中:
- time = 当前时间
- qtime = 队列变为空的时间
- s = 在该队列上连续入队操作之间的典型时间
时间参考以字节为单位,其中每个字节表示物理接口在传输介质上发送一个字节所需的时间(参见"内部时间参考"部分)。参数s在dropper模块中被定义为一个常数,其值为:s=2^22。这对应于在具有64K个叶节点的层次结构中,每个叶节点传输一个64字节数据包到传输介质上所需的时间,并代表了最坏情况。对于规模较小的调度器层次结构,可能需要减小参数s,在red头文件源文件(rte_red.h)中定义为:
#define RTE_RED_S
由于时间参考是以字节为单位的,因此端口速度被包含在表达式time-qtime中。dropper无需配置实际端口速度,它会自动适应低速和高速链路。
实现
采用数值方法来计算方程2中出现的(1-wq)^m因子。这个方法基于以下恒等式:
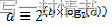
这使我们能够表达如下:
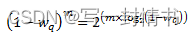
在dropper模块中,使用查找表来为dropper模块支持的每个wq值计算log2(1-wq)。然后,可以通过将表值乘以m并进行位移操作来获得(1-wq)m因子。为了避免乘法中的溢出,值m和查找表值都限制在16位。查找表的总大小为56字节。一旦使用这种方法获得了(1-wq)m因子,就可以从方程2中计算出平均队列大小。
替代方法
考虑了其他计算在队列为空时(方程2)计算平均队列大小所需的因子(1-wq)^m的方法。这些方法包括:
- 浮点数计算
- 使用小查找表(512B)和最多16次乘法的定点数计算(这是FreeBSD* ALTQ RED实现中使用的方法)
- 使用小查找表(512B)和16个SSE乘法的定点数计算(FreeBSD* ALTQ RED实现的SSE优化版本)
- 大查找表(76 KB)
最终选择的方法(在上面的“实现”部分中描述)在运行时性能和内存需求方面优于所有这些方法,并且在精度上也达到了与浮点数计算相当的水平。表17列出了这些替代方法相对于dropper使用的方法的性能。可以看到,浮点数实现性能最差。
表21.17:替代方法的相对性能
| Method | Relative Performance |
|---|---|
| Current dropper method (see Dropper) | 100% |
| Fixed-point method with small (512B) look-up table | 148% |
| SSE method with small (512B) look-up table | 114% |
| Large (76KB) look-up table | 118% |
| Floating-point | 595% |
注意:
在这种情况下,由于性能是以在特定条件下执行操作所花费的时间来表示的,任何超过100%的相对性能值都比参考方法运行得更慢。
丢弃决策模块
丢弃决策模块:
- 比较平均队列大小与最小和最大阈值
- 计算丢包概率
- 随机决定是否对到达的数据包进行入队或丢弃
丢包概率的计算分为两个阶段。首先根据平均队列大小、最小和最大阈值以及标记概率计算初始丢包概率。然后,从初始丢包概率计算实际丢包概率。实际丢包概率考虑了计数的运行时值,因此随着自上次丢包以来到达队列的数据包越来越多,实际丢包概率也会增加。
初始数据包丢包概率
初始丢包概率使用以下方程计算:
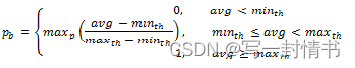
其中:
- maxp = 标记概率
- avg = 平均队列大小
- minth = 最小阈值
- maxth = 最大阈值
方程3中使用平均队列大小计算数据包丢失概率的过程如图21.10所示。如果平均队列大小低于最小阈值,则将到达的数据包入队。如果平均队列大小达到或超过最大阈值,则将到达的数据包丢弃。如果平均队列大小介于最小和最大阈值之间,则计算丢包概率以确定是否应将数据包入队或丢弃。
实际丢包概率
如果平均队列大小介于最小和最大阈值之间,则实际丢包概率由以下方程计算:
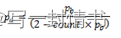
其中:
- Pb = 初始丢包概率(来自方程3)
- count = 自上次丢包以来到达的数据包数量
方程4中的常数2是与参考文档给出的丢包概率公式唯一的偏差,参考文档中使用了值1。需要注意的是,从计算得到的pa可能为负值或大于1。如果是这种情况,则应该使用值1。
图21.11显示了初始和实际丢包概率。实际丢包概率分别使用了参考文档中给出的公式(蓝色曲线)和dropper模块中实现的公式(红色曲线)。与用户指定的标记概率配置参数相比,参考文档中的公式导致了明显更高的丢包率。与参考文档的偏差只是一个设计决策,其他RED实现(例如FreeBSD* ALTQ RED)也做出了类似的选择。

图 21.10:给定 RED 配置的数据包丢弃概率
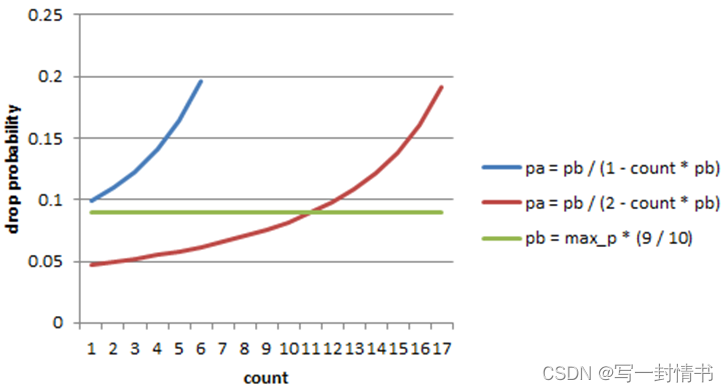
图 21.11:使用 a 计算的初始掉落概率 (pb)、实际掉落概率 (pa)
因子 1(蓝色曲线)和因子 2(红色曲线)
21.3.3 队列为空操作
记录数据包队列变为空的时间,并将其保存到RED运行时数据中,以便EWMA过滤器块在下一次入队操作时计算平均队列大小。通过API通知dropper模块队列已经变为空是调用应用程序的责任。
21.3.4 源文件位置
DPDK dropper的源文件位于:
- DPDK/lib/librte_sched/rte_red.h
- DPDK/lib/librte_sched/rte_red.c
21.3.5 与DPDK QoS调度器的集成
DPDK QoS调度器中的RED功能默认情况下是禁用的。要启用它,请使用DPDK配置参数:
CONFIG_RTE_SCHED_RED=y
必须将此参数设置为y。该参数位于DPDK/config目录中的构建配置文件中,例如,DPDK/config/common_linuxapp。在初始化过程中,RED配置参数在传递给调度器的rte_sched_port_params结构中的rte_red_params结构中进行指定。RED参数分别针对四个流量类别和三种数据包颜色(绿色、黄色和红色)进行指定,允许调度器实现加权随机早期检测(WRED)。
21.3.6 与DPDK QoS调度器示例应用程序的集成
DPDK QoS调度器应用程序在启动时读取一个配置文件。配置文件包括一个包含RED参数的部分。这些参数的格式在“配置”中有描述。下面是一个示例RED配置。在此示例中,队列大小为64个数据包。
注意:为了正确运行,应该在相同流量类别(tc)中的每种数据包颜色(绿色、黄色、红色)中使用相同的EWMA过滤器权重参数(wred weight)。
; RED params per traffic class and color (Green / Yellow / Red)
[red]
tc 0 wred min = 28 22 16
tc 0 wred max = 32 32 32
tc 0 wred inv prob = 10 10 10
tc 0 wred weight = 9 9 9
tc 1 wred min = 28 22 16
tc 1 wred max = 32 32 32
tc 1 wred inv prob = 10 10 10
tc 1 wred weight = 9 9 9
tc 2 wred min = 28 22 16
tc 2 wred max = 32 32 32
tc 2 wred inv prob = 10 10 10
tc 2 wred weight = 9 9 9
tc 3 wred min = 28 22 16
tc 3 wred max = 32 32 32
tc 3 wred inv prob = 10 10 10
tc 3 wred weight = 9 9 9
通过此配置文件,适用于绿色、黄色和红色数据包的 RED 配置
流量类别 0 的情况如表 18 所示。
表 21.18:与 RED 配置相对应的 RED 配置文件
| Parameter Name | Green | Yellow | Red |
|---|---|---|---|
| Minimum Threshold | 28 | 22 | 16 |
| Maximum Threshold | 32 | 32 | 32 |
| Mark Probability | 10 | 10 | 10 |
| EWMA Filter Weight | 9 | 9 | 9 |
21.3.7 应用程序编程接口(API)
Enqueue API
enqueue API 的语法如下:
int rte\_red\_enqueue(const struct rte\_red\_config \*red_cfg,
struct rte\_red \*red,
const unsigned q,
const uint64\_t time)
传递给 enqueue API 的参数包括配置数据、运行时数据、数据包队列的当前大小(以数据包为单位)以及表示当前时间的值。时间参考以字节为单位,其中一个字节表示物理接口在传输介质上发送一个字节所需的时间持续。(请参阅内部时间参考部分)。为了性能考虑,丢弃器重用调度器的时间戳。
Empty API
empty API 的语法如下:
void rte\_red\_mark\_queue\_empty(struct rte\_red \*red, const uint64\_t time)
传递给 empty API 的参数包括运行时数据和以字节表示的当前时间。
21.4 交通计量
交通计量组件实现了由 IETF RFC 2697 和 2698 定义的单速率三色标记器(srTCM)和双速率三色标记器(trTCM)算法。这些算法根据预先为每个流量流定义的允许量来测量传入数据包流。因此,每个传入的数据包根据其所属流的监测消耗被标记为绿色、黄色或红色。
21.4.1 功能概述
srTCM 算法为每个流量流定义了两个令牌桶,这两个桶共享相同的令牌更新速率:
• 承诺(C)桶:以承诺信息速率(CIR)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









