







 本文详细解析了ThreadPoolExecutor的工作原理,包括参数配置、队列类型、线程工厂、拒绝策略及内部处理流程,帮助理解线程池在不同场景下的应用。
本文详细解析了ThreadPoolExecutor的工作原理,包括参数配置、队列类型、线程工厂、拒绝策略及内部处理流程,帮助理解线程池在不同场景下的应用。
ThreadPoolExecutor分析
源码简单分析
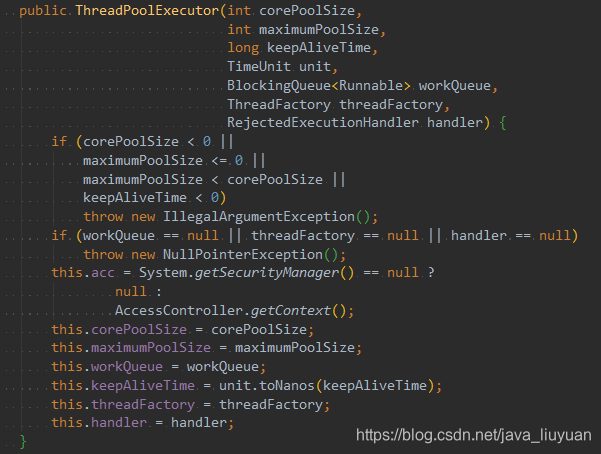
参数说明
corePoolSize:核心线程数;
maximumPoolSize:最大线程数,即线程池中允许存在的最大线程数;
keepAliveTime:线程存活时间,对于超过核心线程数的线程,当线程处理空闲状态下,且维持时间达到keepAliveTime时,线程将被销毁;
unit:keepAliveTime的时间单位
workQueue:工作队列,用于存在待执行的线程任务;
threadFactory:创建线程的工厂,用于标记区分不同线程池所创建出来的线程;
handler:当到达线程数上限或工作队列已满时的拒绝处理逻辑;
具体实现
1. 自定义队列
BlockingQueue<Runnable> q = new LinkedBlockingQueue<>(2048);
BlockingQueue<Runnable> q = new ArrayBlockingQueue<>(10);
LinkedBlockingQueue是一个阻塞队列,内部由两个ReentrantLock来实现出入队列的线程安全,由各自的Condition对象的await和signal来实现等待和唤醒功能。它和ArrayBlockingQueue的不同点在于:
- 队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
- 数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
- 由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
- 两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
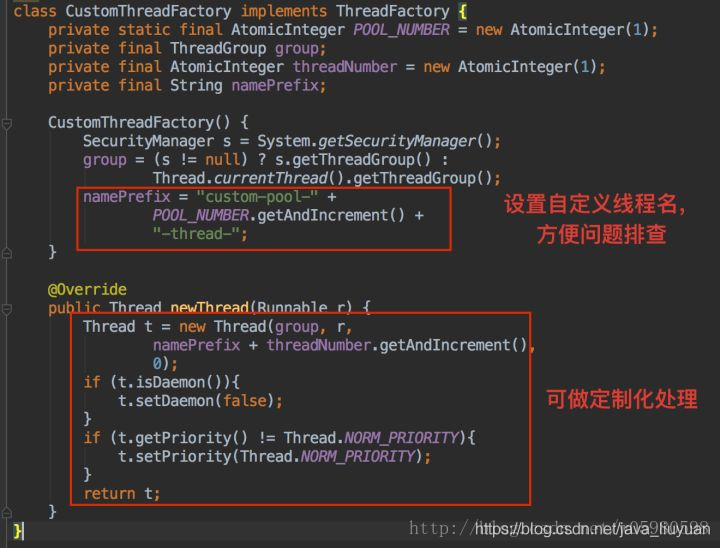
2. 自定义threadFactory。除了可以自定义创建的线程名称,方便问题排查,在newThread(Runnable r)创建线程的方法中,还可以进行定制化设置,如为线程设置特定上下文等。
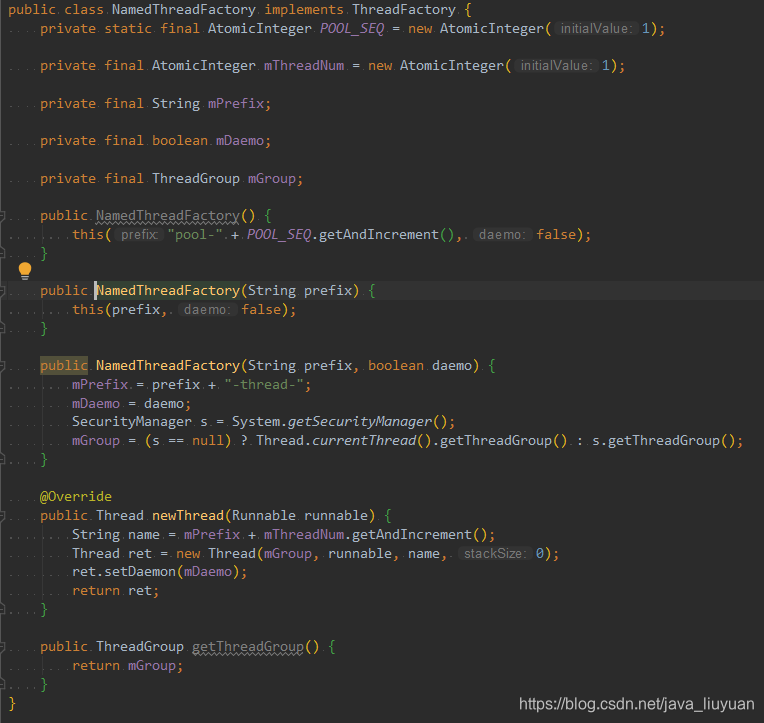
或者:
3. 自定义RejectedExecutionHandler。记录异常信息,选择不同处理逻辑,有交由当前线程执行任务,有直接抛出异常,再或者等待后继续添加任务等。
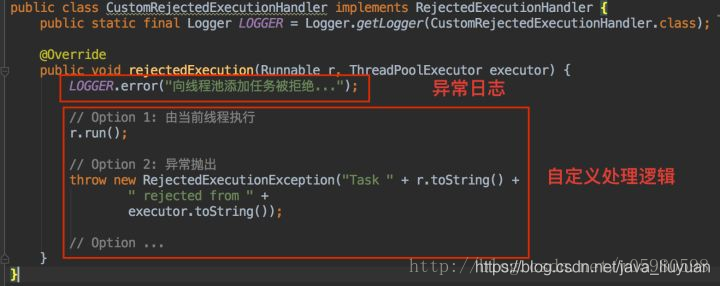
1)AbortPolicy
AbortPolicy
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
A handler for rejected tasks that throws a {@code RejectedExecutionException}.
这是线程池默认的拒绝策略,在任务不能再提交的时候,抛出异常,及时反馈程序运行状态。如果是比较关键的业务,推荐使用此拒绝策略,这样子在系统不能承载更大的并发量的时候,能够及时的通过异常发现。
(2)DiscardPolicy
ThreadPoolExecutor.DiscardPolicy:丢弃任务,但是不抛出异常。如果线程队列已满,则后续提交的任务都会被丢弃,且是静默丢弃。
A handler for rejected tasks that silently discards therejected task.
使用此策略,可能会使我们无法发现系统的异常状态。建议是一些无关紧要的业务采用此策略。例如,本人的博客网站统计阅读量就是采用的这种拒绝策略。
(3)DiscardOldestPolicy
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新提交被拒绝的任务。
A handler for rejected tasks that discards the oldest unhandled request and then retries {@code execute}, unless the executor is shut down, in which case the task is discarded.
此拒绝策略,是一种喜新厌旧的拒绝策略。是否要采用此种拒绝策略,还得根据实际业务是否允许丢弃老任务来认真衡量。
(4)CallerRunsPolicy
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
A handler for rejected tasks that runs the rejected task directly in the calling thread of the {@code execute} method, unless the executor has been shut down, in which case the task is discarded.
如果任务被拒绝了,则由调用线程(提交任务的线程)直接执行此任务
4. 创建自定义线程池
 或者
或者

5. 线程池内在处理逻辑
我们通过一些例子,来观察一下其内部的处理逻辑。基于上述具体代码,我们已经创建了一个核心线程数4,最大线程数8,线程存活时间10s,工作队列最大容量为10的一个线程池。
- 初始化线程池:未添加线程任务
- 这时,线程池中不会创建任何线程,存活线程为0,工作队列为0.
- 未达核心线程数:添加4个线程任务
- 由于当前存活线程数 <= 核心线程数,所以会创建新的线程。即存活线程为4,工作队列为0.
- 核心线程数已满:添加第5个线程任务
- 若当前线程池中存在空闲线程,则交由该线程处理。即存活线程为4,工作队列为0.
- 若当前所有线程处理运行状态,加入工作队列。即存活线程为4,工作队列为1.(注意:此时工作队列中的任务不会被执行,直到有线程空闲后,才能被处理)
- 工作队列未满:假设添加的任务都是耗时操作(短时间不会结束),再添加9个耗时任务
- 即存活线程为4,工作队列为10.
- 工作队列已满 & 未达最大线程数:再添加4个任务
- 当工作队列已满,且不存在空闲线程,此时会创建额外线程来处理当前任务。此时存活线程为8,工作队列为10.
- 工作队列已满 & 且最大线程数已满:再添加1个任务
- 触发RejectedExecutionHandler,将当前任务交由自己设置的执行句柄进行处理。此时存活线程为8,工作队列为10.
- 当任务执行完后,没有新增的任务,临时扩充的线程(大于核心线程数的)将在10s(keepAliveTime)后被销毁。
总结
最后,我们在使用线程池的时候,需要根据使用场景来自行选择。通过corePoolSize和maximumPoolSize的搭配,存活时间的选择,以及改变队列的实现方式,如:选择延迟队列,来实现定时任务的功能。并发包Executors中提供的一些方法确实好用,但我们仍需有保留地去使用,这样在项目中就不会挖太多的坑。
扩展
对于一些耗时的IO任务,盲目选择线程池往往不是最佳方案。通过异步+单线程轮询,上层再配合上一个固定的线程池,效果可能更好。类似与Reactor模型中selector轮询处理。
- 原文链接:java线程池的正确打开方式
- 参考文档: 谈谈LinkedBlockingQueue


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









