






一、首先对自己所写项目熟悉,包含项目搭建流程、所用技术。
二、几种熟悉的设计模式?具体实现原理?
答:①单例模式
实现原理:单例模式最重要的是确保对象只有一个。
简单来说,保证一个类在内存中的对象就一个。
实现方式
饿汉式:一开始就创建好实例,每次调用直接返回,经典的“拿空间换时间”。
懒汉式:延迟加载,第一次调用的时候才加载,然后返回,以后的每次的调用就直接返回。经典“拿时间换空间”,多线程环境下要注意解决线程安全的问题。
登记式:对一组单例模式进行的维护,主要是在数量上的扩展,通过线程安全的map把单例存进去,这样在调用时,先判断该单例是否已经创建,是的话直接返回,不是的话创建一个登记到map中,再返回。
三、spring常用注解?
答:
@Component:泛指各种组件
@Controller、@Service、@Repository都可以称为@Component。
@Controller:控制层
@Service:业务层
@Repository:数据访问层
(2)@Bean
导入第三方包里面的注解
(3)@Import
@Import(要导入到容器中的组件);
四、vue的生命周期?
答:Vue实例从创建到销毁的过程,就是生命周期。
钩子函数:
1、beforeCreate 在实例初始化之后,数据观测(data observer) 和 event/watcher 事件配置之前被调用。
2、created 实例已经创建完成之后被调用。调用数据,调用方法,调用异步函数。
3、beforeMount 在挂载开始之前被调用:相关的 render 函数(模板)首次被调用。
4、mounted el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用该钩子。
5、beforeUpdate 数据更新时调用,发生在虚拟 DOM 重新渲染和打补丁之前。
6、updated 由于数据更改导致的虚拟 DOM 重新渲染和打补丁,在这之后会调用该钩子。
7、beforeDestroy 实例销毁之前调用。在这一步,实例仍然完全可用。
8、destroyed Vue 实例销毁后调用。调用后,Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。 该钩子在服务器端渲染期间不被调用。
五、列举几种算法?
答:1.冒泡排序,
2.快速排序
3.选择排序
4.插入排序
5.希尔排序
6.归并排序
六、mybatis中SQL的写法?
答:1. if 语句 (简单的条件判断)
2.choose (when,otherwise) ,相当于java 语⾔中的 switch ,与 jstl 中的choose 很类似.
3.trim (对包含的内容加上 prefix,或者 suffix 等,前缀,后缀)
4.where (主要是⽤来简化sql语句中where条件判断的,能智能的处理 and or ,不必担⼼多余导致语法误)
5.set (主要⽤于更新时)
6.foreach (在实现 mybatis in 语句查询时特别有⽤)
七、spring 的 IOC 有什么作用?
答:控制反转, 不需要程序员来创建对象了,交给Spring框架来管理对象(从初始化…销毁).程序员可以直接从 Spring框架中获取Bean的对象。
八、数据结构有哪些?
答:
List(接口)
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下 >标)来访问List中的元素,这类似于Java的数组。
Vector
基于数组(Array)的List,其实就是封装了数组所不具备的一些功能方便我们使用,所以它难易避免数组的限制,同时性能也不可能超越数组。所以,在可能的情况下,我们要多运用数组。另外很重要的一点就是Vector是线程同步的(sychronized)的,这也是Vector和ArrayList 的一个的重要区别。
ArrayList
同Vector一样是一个基于数组上的链表,但是不同的是ArrayList不是同步的。所以在性能上要比Vector好一些,但是当运行到多线程环境中时,可需要自己在管理线程的同步问题。
LinkedList
LinkedList不同于前面两种List,它不是基于数组的,所以不受数组性能的限制。
它每一个节点(Node)都包含两方面的内容:
1.节点本身的数据(data);
2.下一个节点的信息(nextNode)。
所以当对LinkedList做添加,删除动作的时候就不用像基于数组的ArrayList一样,必须进行大量的数据移动。只要更改nextNode的相关信息就可以实现了,这是LinkedList的优势。
List总结
所有的List中只能容纳单个不同类型的对象组成的表,而不是Key-Value键值对。
例如:[ tom,1,c ]
所有的List中可以有相同的元素,例如Vector中可以有 [ tom,koo,too,koo ]
所有的List中可以有null元素,例如[ tom,null,1 ]
基于Array的List(Vector,ArrayList)适合查询,而LinkedList 适合添加,删除操作
Set(接口)
Set是不包含重复元素的Collection
HashSet
虽然Set同List都实现了Collection接口,但是他们的实现方式却大不一样。List基本上都是以Array为基础。但是Set则是在 HashMap的基础上来实现的,这个就是Set和List的根本区别。HashSet的存储方式是把HashMap中的Key作为Set的对应存储项。看看 HashSet的add(Object obj)方法的实现就可以一目了然了。
LinkedHashSet
HashSet的一个子类,一个链表。
SortedSet
有序的Set,通过SortedMap来实现的。
Map(接口)
Map 是一种把键对象和值对象进行关联的容器,而一个值对象又可以是一个Map,依次类推,这样就可形成一个多级映射。对于键对象来说,像Set一样,一个 Map容器中的键对象不允许重复,这是为了保持查找结果的一致性;如果有两个键对象一样,那你想得到那个键对象所对应的值对象时就有问题了,可能你得到的并不是你想的那个值对象,结果会造成混乱,所以键的唯一性很重要,也是符合集合的性质的。当然在使用过程中,某个键所对应的值对象可能会发生变化,这时会按照最后一次修改的值对象与键对应。对于值对象则没有唯一性的要求,你可以将任意多个键都映射到一个值对象上,这不会发生任何问题(不过对你的使用却可能会造成不便,你不知道你得到的到底是那一个键所对应的值对象)。
HashMap
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了不同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。另外,HashMap是非线程安全的,也就是说在多线程的环境下,可能会存在问题,而Hashtable是线程安全的。
TreeMap
TreeMap则是对键按序存放,
HashTable
(1)Hashtable 是一个散列表,它存储的内容是键值对(key-value)映射。
(2)Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
(3)Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。
几个常用类的区别
1.ArrayList: 元素单个,效率高,多用于查询
2.Vector: 元素单个,线程安全,多用于查询
3.LinkedList:元素单个,多用于插入和删除
4.HashMap: 元素成对,元素可为空
5.HashTable: 元素成对,线程安全,元素不可为空
Vector、ArrayList和LinkedList
大多数情况下,从性能上来说ArrayList最好,但是当集合内的元素需要频繁插入、删除时LinkedList会有比较好的表现,但是它们三个性能都比不上数组,另外Vector是线程同步的。所以:
如果能用数组的时候(元素类型固定,数组长度固定),请尽量使用数组来代替List;
如果没有频繁的删除插入操作,又不用考虑多线程问题,优先选择ArrayList;
如果在多线程条件下使用,可以考虑Vector;
如果需要频繁地删除插入,LinkedList就有了用武之地;
如果你什么都不知道,用ArrayList没错。
栈
栈是只能在某一端插入和删除的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
队列
一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
数组
在程序设计中,为了处理方便, 把具有相同类型的若干变量按有序的形式组织起来。这些按序排列的同类数据元素的集合称为数组。在C语言中, 数组属于构造数据类型。一个数组可以分解为多个数组元素,这些数组元素可以是基本数据类型或是构造类型。因此按数组元素的类型不同,数组又可分为数值数组、字符数组、指针数组、结构数组等各种类别。
链表
一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:
一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
树
树是包含n(n>0)个结点的有穷集合K,且在K中定义了一个关系N,N满足 以下条件:
(1)有且仅有一个结点 k0,他对于关系N来说没有前驱,称K0为树的根结点。简称为根(root)
(2)除K0外,k中的每个结点,对于关系N来说有且仅有一个前驱。
(3)K中各结点,对关系N来说可以有m个后继(m>=0)。
堆
在计算机科学中,堆是一种特殊的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。
散列表
若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数(Hash function),按这个思想建立的表为散列表。
九、常用的SQL优化?
答:
1.查询SQL尽量不要使用select *,而是具体字段。
2.避免在where子句中使用or来连接条件。(使用or可能会使索引失效,从而全表扫描)
3.使用varchar代替char。(
-
varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间
-
char按声明大小存储,不足补空格
-
其次对于查询来说,在一个相对较小的字段内搜索,效率更高
)
4.尽量使用数值替代字符串类型。
5.查询尽量避免返回大量数据。.
6.复合索引最左特性。
十、nginx怎么实现负载均衡?
答:只需在nginx配置中指明参数即可。负载均衡也是 Nginx常用的一个功能,当一台服务器的单位时间内的访问量越大时,服务器压力就越大,大到超过自身承受能力时,服务器就会崩溃。为了避免服务器崩溃,让用户有更好的体验,我们通过负载均衡的方式来分担服务器压力。我们可以建立很多很多服务器,组成一个服务器集群,当用户访问网站时,先访问一个中间服务器,在让这个中间服务器在服务器集群中选择一个压力较小的服务器,然后将该访问请求引入该服务器。如此以来,用户的每次访问,都会保证服务器集群中的每个服务器压力趋于平衡,分担了服务器压力,避免了服务器崩溃的情况。负载均衡配置一般都需要同时配置反向代理,通过反向代理跳转到负载 均衡。
十一、单点登录的实现原理?
答:指在多系统应用群中登录一个系统,便可在其他所有系统中得到授权而无需再次登录,只有认证中心能接受用户的用户名密码等安全信息,其他系统不提供登录入口,只接受认证中心的间接授权。间接授权通过令牌实现,sso认证中心验证用户的用户名密码没问题,创建授权令牌,在接下来的跳转过程中,授权令牌作为参数发送给各个子系统,子系统拿到令牌,即得到了授权,可以借此创建局部会话,局部会话登录方式与单系统的登录方式相同。这个过程,也就是单点登录的原理。
十二、springcloud组件的作用和实现?
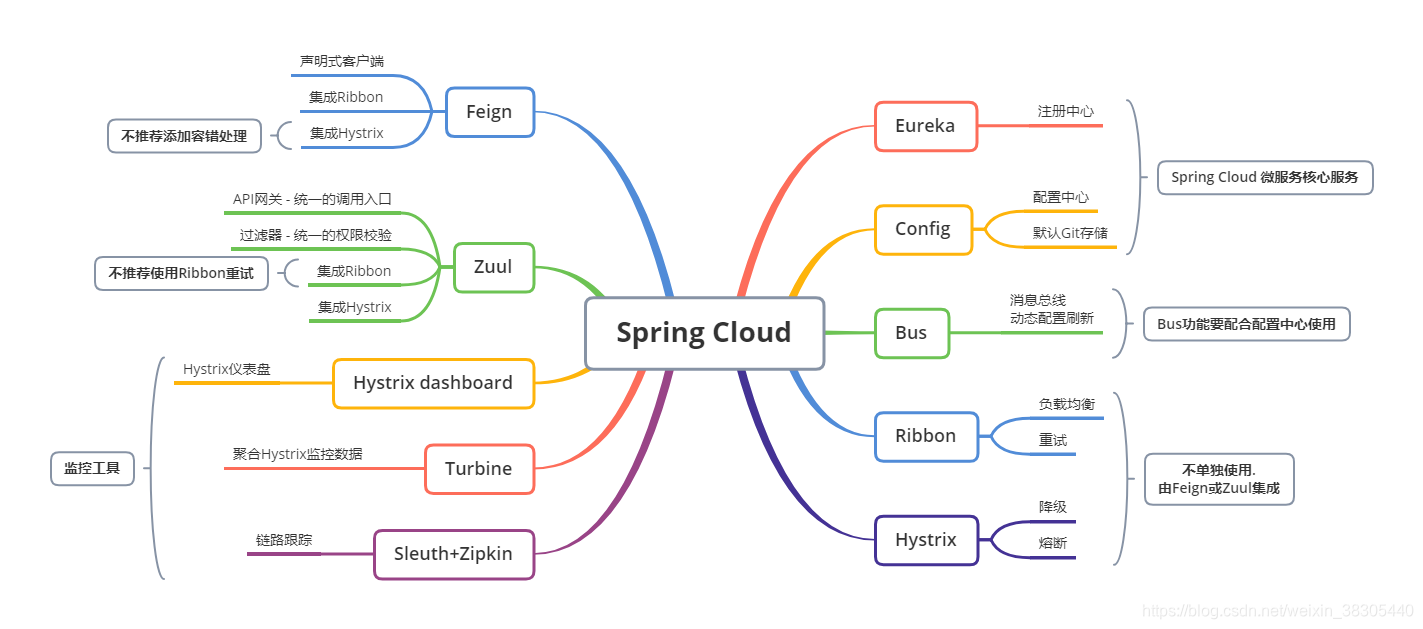
答:核心组件:Eureka、Ribbon、Feign、Hystrix、Zuul。
1. Eureka 是微服务架构中的注册中心,专门负责服务的注册与发现。
心跳间隔时间,默认 30 秒,最后一次心跳后,间隔多久认定微服务不可用,默认90。
eureka 的自我保护状态:心跳失败的比例,在15分钟内是否超过85%,如果出现了超过的情况,Eureka Server会将当前的实例注册信息保护起来,同时提示一个警告,一旦进入保护模式,Eureka Server将会尝试保护其服务注册表中的信息,不再删除服务注册表中的数据。也就是不会注销任何微服务
2. Feign 的一个关键机制就是使用了动态代理。
-
首先,如果你对某个接口定义了 @FeignClient 注解,Feign 就会针对这个接口创建一个动态代理。
-
接着你要是调用那个接口,本质就是会调用 Feign 创建的动态代理,这是核心中的核心。
-
Feign的动态代理会根据你在接口上的 @RequestMapping 等注解,来动态构造出你要请求的服务的地址。
-
最后针对这个地址,发起请求、解析响应。
3. Ribbon 的作用是负载均衡,均匀的把请求分发到各个机器上。
- Ribbon 是和 Feign 以及 Eureka 紧密协作,完成工作的,具体如下:
-
首先 Ribbon 会从 Eureka Client 里获取到对应的服务注册表,也就知道了所有的服务都部署在了哪些机器上,在监听哪些端口号。
-
然后 Ribbon 就可以使用默认的 Round Robin 算法,从中选择一台机器。
-
Feign 就会针对这台机器,构造并发起请求。
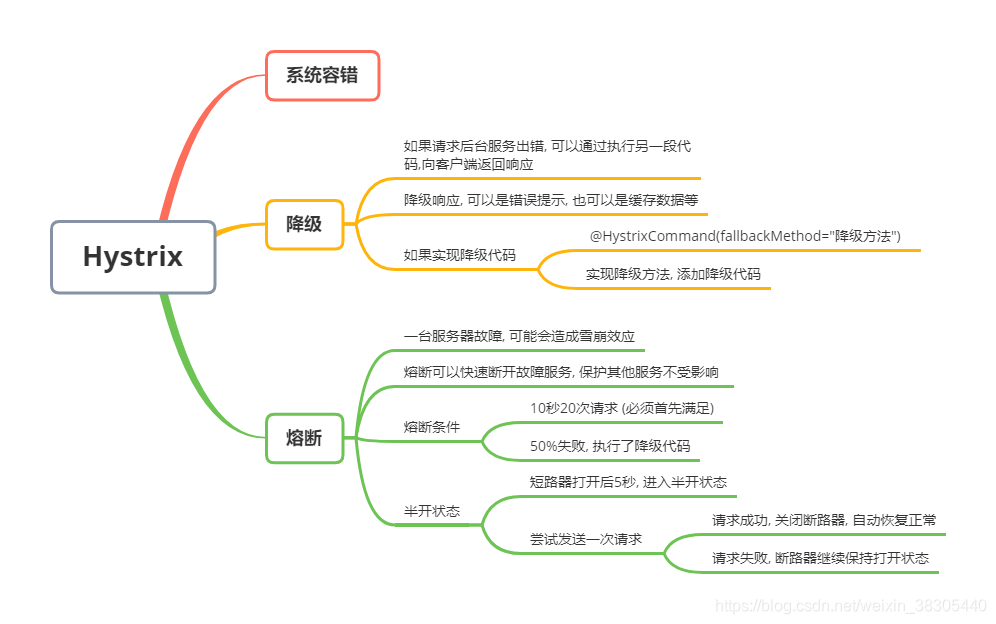
4. Hystrix 是隔离、熔断以及降级的一个框架。
5. Zuul 也就是微服务网关,这个组件是负责网络路由的。做统一的降级、限流、认证授权、安全。
Spring Cloud 核心组件,在微服务架构中,分别扮演的角色:
-
Eureka:各个服务启动时,Eureka Client 都会将服务注册到 Eureka Server,并且 Eureka Client 还可以反过来从 Eureka Server 拉取注册表,从而知道其他服务在哪里。
-
Ribbon:服务间发起请求的时候,基于 Ribbon 做负载均衡,从一个服务的多台机器中选择一台。
-
Feign:基于 Feign 的动态代理机制,根据注解和选择的机器,拼接请求 URL 地址,发起请求。
-
Hystrix:发起请求是通过 Hystrix 的线程池来走的,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题。
-
Zuul:如果前端、移动端要调用后端系统,统一从 Zuul 网关进入,由 Zuul 网关转发请求给对应的服务。
十三、Docker 的基本指令?
答:
docker version查看docker版本docker info查看docker详细信息docker --help查看docker命令
docker images查看docker镜像
docker ps列出当前所有正在运行的容器docker ps -a列出所有的容器
docker start 容器ID或容器名称启动容器docker restart 容器ID或容器名称重新启动容器docker stop容器ID或容器名称停止容器
docker rm 容器ID或容器名称删除容器docker rm -f 容器ID或容器名称强制删除容器
docker exec 容器ID进到容器内
十四、Linux 的基本指令?
答:
ls 列出当前工作目录下的所有文件/文件夹的名称
pwd 指令打印当前工作目录
cd 指令用于切换当前的工作目录的
mkdir 指令创建目录
cp 指令复制文件/文件夹到指定的位置
mv 指令移动文档到新的位置
rm 指令移除/删除文档
-f:force,强制删除,不提示是否删除
vim 指令 文件的路径
十五、Git 指令?
git add .
git pull 本地与服务器端同步
git push (远程仓库名) (分支名) 将本地分支推送到服务器上去。
git push origin master 将本地项目给提交到服务器中
git clone 克隆版本库
git commit 提交
git log 显示提交日志
十六、sleep()和 wait() 的区别?
答:
类的不同:sleep() 来自 Thread,wait() 来自 Object。
释放锁:sleep() 不释放锁;wait() 释放锁。
用法不同:sleep() 时间到会自动恢复;wait() 可以使用 notify()/notifyAll()直接唤醒。
十七、notify()和 notifyAll()有什么区别?
答:notifyAll()会唤醒所有的线程,notify()之后唤醒一个线程。notifyAll() 调用后,会将全部线程由等待池移到锁池,然后参与锁的竞争,竞争成功则继续执行,如果不成功则留在锁池等待锁被释放后再次参与竞争。而 notify()只会唤醒一个线程,具体唤醒哪一个线程由虚拟机控制。
十八、spring是什么?怎么理解aop和di?
答:Spring是一个开源的轻量级的Java开发框架。 简化应用程序的开发。 Spring提出了一种思想:就是由spring来负责控制对象的生命周期和对象间的关系。
AOP:意思是面向切面编程,提供从另一个角度来考虑程序结构以完善面向对象编程(相对于OOP),即可以通过在编译期间、装载期间或运行期间实现在不修改源代码的情况下给程序动态添加功能的一种技术。
DI:Dependency Injection 依赖注入
理解: 将依赖的属性注入到对象的过程,即为依赖注入。
依赖注入的方式有两种,一种是set方法注入,还用一种是构造方法注入,这两种方式,Spring都支持。
我们要实现IOC设计必须要有DI技术的支持。
十九、string,stringbuilder,stringbuffer的区别,以及应用场景?
答:String 和 StringBuffer、StringBuilder 的区别在于 String 声明的是不可变的对象,每次操作都会生成新的 String 对象,然后将指针指向新的 String 对象,
而 StringBuffer、StringBuilder 可以在原有对象的基础上进行操作,所以在经常改变字符串内容的情况下最好不要使用 String。
StringBuffer 和 StringBuilder 最大的区别在于,StringBuffer 是线程安全的,而 StringBuilder 是非线程安全的,但 StringBuilder 的性能却高于 StringBuffer,所以在单线程环境下推荐使用StringBuilder,多线程环境下推荐使用 StringBuffer。
二十、hashmap 的实现原理?
答:HashMap 基于 Hash 算法实现的,我们通过 put(key,value)存储,get(key)来获取。当传入 key 时,HashMap 会根据 key. hashCode() 计算出 hash 值,根据 hash 值将 value 保存在 bucket 里。当计算出的 hash 值相同时,我们称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的value。当 hash 冲突的个数比较少时,使用链表否则使用红黑树。
二十一、jsp 的内置对象?
答:
jsp的9个内置对象和4个作用域:
request 请求对象 类型 javax.servlet.ServletRequest 作用域 Request
response 响应对象 类型 javax.servlet.SrvletResponse 作用域 Page
pageContext 页面上下文对象 类型 javax.servlet.jsp.PageContext 作用域 Page
session 会话对象 类型 javax.servlet.http.HttpSession 作用域 Session
application 应用程序对象 类型 javax.servlet.ServletContext 作用域 Application
out 输出对象 类型 javax.servlet.jsp.JspWriter 作用域 Page
config 配置对象 类型 javax.servlet.ServletConfig 作用域 Page
page 页面对象 类型 javax.lang.Object 作用域 Page
exception 例外对象 类型 javax.lang.Throwable 作用域 page
二十二、dom元素操作对象?
答:
- getElementsByTagName 标签名称,得到数组
- getElementsByName name属性,得到数组
- getElementsByClassName class属性,得到数组
- getElementById id属性,单个值
--获取对象: window.document
--调用方法:
getElementById("元素的id的属性的值")--返回1个元素
getElementsByName("元素的name属性的值")--返回多个元素(用数组)
getElementsByClassName("元素的class属性的值")--返回多个元素(用数组)
getElementsByTagName("元素的标签名的值")--返回多个元素(用数组)
write()--向文档写 HTML 表达式 或 JavaScript 代码
title--返回网页的标题
id--设置或返回元素的id
innerHTML--设置或返回元素的内容















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









