






核心思想:把64-bit分别划分成多段,分开来标示机器、时间、某一并发序列等,从而使每台机器及同一机器生成的ID都是互不相同。
PS:这种结构是雪花算法提出者Twitter的分法,但实际上这种算法使用可以很灵活,根据自身业务的并发情况、机器分布、使用年限等,可以自由地重新决定各部分的位数,从而增加或减少某部分的量级。比如:百度的UidGenerator、美团的Leaf等,都是基于雪花算法做一些适合自身业务的变化。
- Twitter的snowflake算法
核心思想是:采用bigint(64bit)作为id生成类型,并将所占的64bit 划分成多段。
其结构如下:
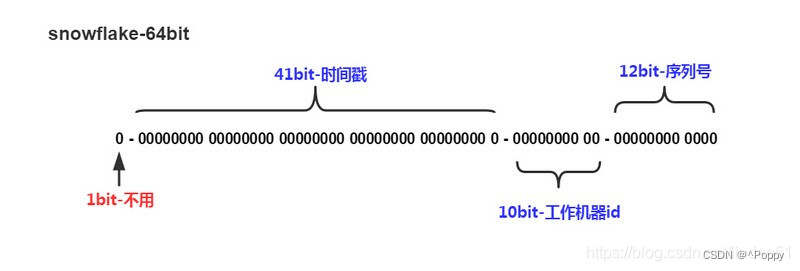
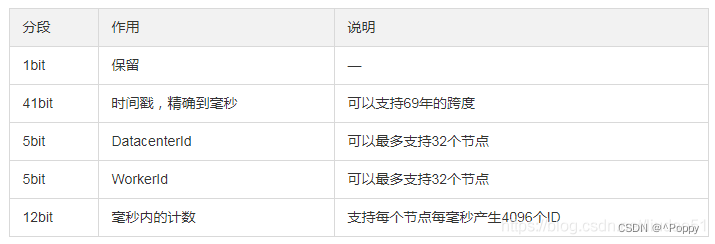
说明:
①1位标识:由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
②41位时间截(毫秒级):需要注意的是,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)得到的值,这里的开始时间截,一般是指我们的id生成器开始使用的时间截,由我们的程序来指定。41位的毫秒时间截,可以使用69年(即T =(1L << 41)/(1000 * 60 * 60 * 24 * 365)= 69)。
③10位的数据机器位:包括5位数据中心标识Id(datacenterId)、5位机器标识Id(workerId),最多可以部署1024个节点(即1 << 10 = 1024)。超过这个数量,生成的ID就有可能会冲突。
④12位序列:毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号(即1 << 12 = 4096)。
PS:全部结构标识(1+41+10+12=64)加起来刚好64位,刚好凑成一个Long型。
优点:
①整体上按照时间按时间趋势递增,后续插入索引树的时候性能较好。
②整个分布式系统内不会产生ID碰撞(由数据中心标识ID、机器标识ID作区分)
③本地生成,且不依赖数据库(或第三方组件),没有网络消耗,所以效率高(每秒能够产生26万ID左右)。
缺点:
①由于雪花算法是强依赖于时间的,在分布式环境下,如果发生时钟回拨,很可能会引起ID重复、ID乱序、服务会处于不可用状态等问题。
解决方案有:
a. 将ID生成交给少量服务器,并关闭时钟同步。
b. 直接报错,交给上层业务处理。
c. 如果回拨时间较短,在耗时要求内,比如5ms,那么等待回拨时长后再进行生成。
d. 如果回拨时间很长,那么无法等待,可以匀出少量位(1~2位)作为回拨位,一旦时钟回拨,将回拨位加1,可得到不一样的ID,2位回拨位允许标记3次时钟回拨,基本够使用。如果超出了,可以再选择抛出异常。















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









