







其实任何简单的问题,只要规模大了都会成为一个问题,就如中国人口多,很多小问题都会变成大问题一样。但处理这种海量数据的方法无非就是分治和”人海”战术。使用人海战术的前提是问题的划分能够支持这种人海战术,其手段无非是切割(纵向,横向)和负载均衡。纵向分隔主要是按业务(功能)来分,也就是所谓面向服务架构,横向分隔方式比较多,主要依赖于所处理的对象属性,比如时间属性或者特定业务数据属性划分(比如铁路客票的车次(每个车次的操作基本上是独立的));负载均衡则可以是镜像(部署)分布(同样的功能部署几份)和计算分布(一个问题分几个子问题在不同的机器上运行,然后合并结果)。当然,这些手段是可以综合利用的,最终可以做成多流水线分布式计算模式。另一方面,在海里数据面前,通用的数据处理方式会很困难,高效的方法基本都是有业务针对性和数据针对性的。
1)海量数据处理的基本思想:分治(这种思想在日常生活中无处不在,蚂蚁都知道,一次运不完,分多次运)
2)海量数据处理的基本手段:切割和负载均衡(切割是降低规模,负载均衡是人海战术,人多力量大,同样,机器多也计算能力强)
3)海量数据处理的可靠性保障:多存几份(再好的机器也会坏,鸡蛋不要放在一个篮子里)
4)海量数据处理的最高境界:多流水线并行作业(很多工厂都这样干,用在计算机也没问题)
5)海量数据处理的最好方法:没有最好,只有适合(什么都想做好,基本等于什么都做不好)
....
至于高并发处理,最好的解决办法是针对特定的需求采用特定的方法,基本的方法包括加锁,排队等等。另外一个关键就是要尽量简化事务和减少事务。
有这种意识,只要去想,总能解决,没必要把这些技术搞得很神,从技术上来讲,海量数据处理所涉及的思想和算法都不是很难。
PS:这些天很多人都在鄙视铁路网上售票系统,也有很多人在为其出主意,我觉得没必要,真的,这些思想和技术不是很难的,至少我都能想到,做网上售票的这般兄弟姐妹也一定可以想到,至于为什么是这个结果,他们也只是“被”没技术。铁路是讲政治的地方,何苦皇帝不急太监急呢?
数据划分补充:如果按时间划分,2种情况,分数据库(早期很多企业级级业务系统,特别是财务系统都是这样做),分表(这种一般只针对特定业务表来进行)。按时间划分的时候需要注意单笔业务跨时间段得问题(很多软件都是在通过关帐开账把这种数据转到新的时间段里)。
2012-1-11:补充数据划分,按特定属性划分,用得最多的是按数据归属来划分,比如原来的帐套,现在云计算下的多租赁用户ID(企业用户ID),这种方式可以在三种级别上(表级,数据库(Oracle分用户)级,物理级(多数据库实例))实现,注意点缓存的话,利用负载均衡,可以无限扩展。这种基于现有数据库的模式,可靠性保证只能用数据库本身来实现,虽然用软件也可以实现同一份数据多地方存储,但比较复杂。另外,利用数据库的链接也可以实现纵向分库存放,而且对应用透明,但这种方式维护起来比较麻烦,很多时候也没有必要。(Oralce和SQLServer都可以,而且不同库之间还可以Join,看起来很方便,但不建议,业务紧密联系的还是要放在一起,不同库之间还是不要采用链接上Join,直接在内存中参照还快些)
上面都是说,等过两天有时间,我把我做的架构demo放出来,当然正式版是不能放的(也还没有),那也是公司的版权。
补充两个图:
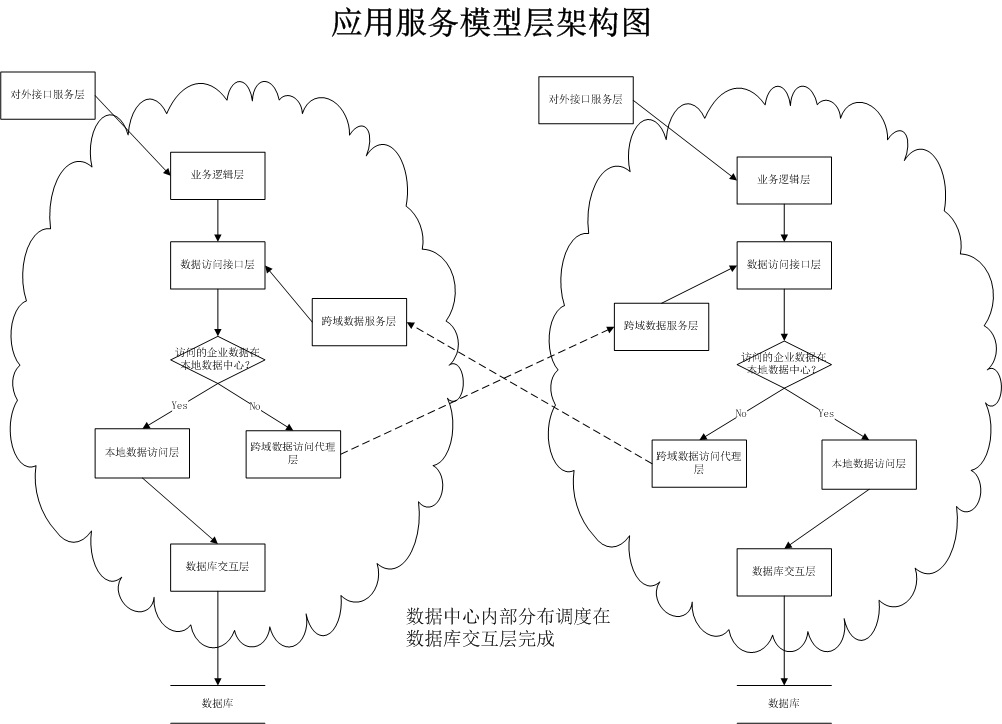
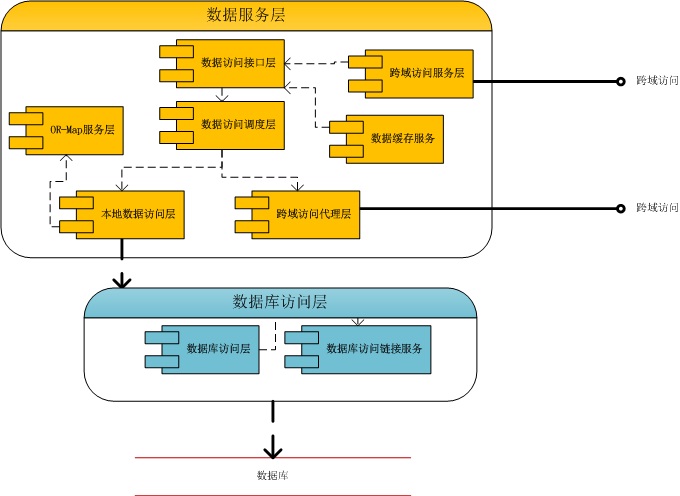
只需要通过配置文件在数据访问调度层和数据库访问层做好动态处理,就可以实现数据中心内部分数据库存放和跨数据中心进行数据访问的功能。
更多信息请查看 java进阶网 http://www.javady.com/index.php/category/thread















 6166
6166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









