






一、什么是布隆过滤器
1、简介
布隆过滤器是一个很长的二进制向量和一系列随机映射函数。可以用于检索一个元素是否在一个集合中。。理解为SET集合。
布隆过滤器其内部维护了一个全为 0 的 bit 数组,需要说明的是,布隆过滤器有一个误判的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间多少。(关于误判后面会讲到)
布隆过滤器的优点:
- 时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
- 保密性强,布隆过滤器不存储元素本身
- 存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
布隆过滤器的缺点:
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
2、使用场景
1. 数据去重:
- 场景描述: 在一些需要对大量数据进行去重的场景,例如用户提交表单、数据同步等,布隆过滤器可以迅速判断某个数据是否已存在,避免重复插入。
- 应用实例: 在用户提交表单时,使用布隆过滤器判断该用户是否已经提交过相同的数据,从而防止重复提交。
2. 缓存穿透问题的解决:
- 场景描述:当缓存中不存在某个数据,而用户频繁查询该数据时,可能导致缓存穿透问题。布隆过滤器可以在缓存层之前迅速过滤掉不存在的数据,减轻数据库的压力。
- 应用实例: 在缓存中存储热门商品的ID列表,并使用布隆过滤器判断某个商品ID是否存在于列表中,从而决定是否查询数据库获取数据。
3. 爬虫数据去重:
- 场景描述: 在爬虫应用中,避免重复抓取相同的数据是一项关键任务。布隆过滤器可以帮助爬虫快速判断某个URL是否已经被抓取过。
- 应用实例: 在爬虫系统中,使用布隆过滤器存储已抓取的URL,以避免重复请求同一URL。
4. 安全黑名单:
- 场景描述: 在需要防范恶意攻击或恶意请求的场景中,布隆过滤器可以用于快速判断某个IP地址或请求是否在黑名单中。
- 应用实例: 在Web应用中,使用布隆过滤器维护一份IP黑名单,快速拦截恶意请求。
5. URL访问记录:
- 场景描述: 对于某些需要记录用户访问记录的应用,布隆过滤器可以用于判断某个URL是否已经被记录,避免重复记录。
- 应用实例: 在网站访问日志记录中,使用布隆过滤器判断某个URL是否已经被记录,防止访问记录过于庞大。
6. 缓存预热:
- 场景描述: 在系统启动时,通过布隆过滤器判断某些热门数据是否在缓存中,可以加速系统的启动过程。
- 应用实例: 在SpringBoot应用启动时,使用布隆过滤器判断热门商品的ID是否在缓存中,并提前加载到缓存中,减少冷启动时的缓存穿透问题。
3、布隆过滤器的原理
3.1 数据结构
以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。
- 一个大型位数组(二进制数组):

- 多个无偏hash函数:无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。
3.2 增加元素
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 将计算得到的数组索引下标位置数据修改为1
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1.
如图所示:
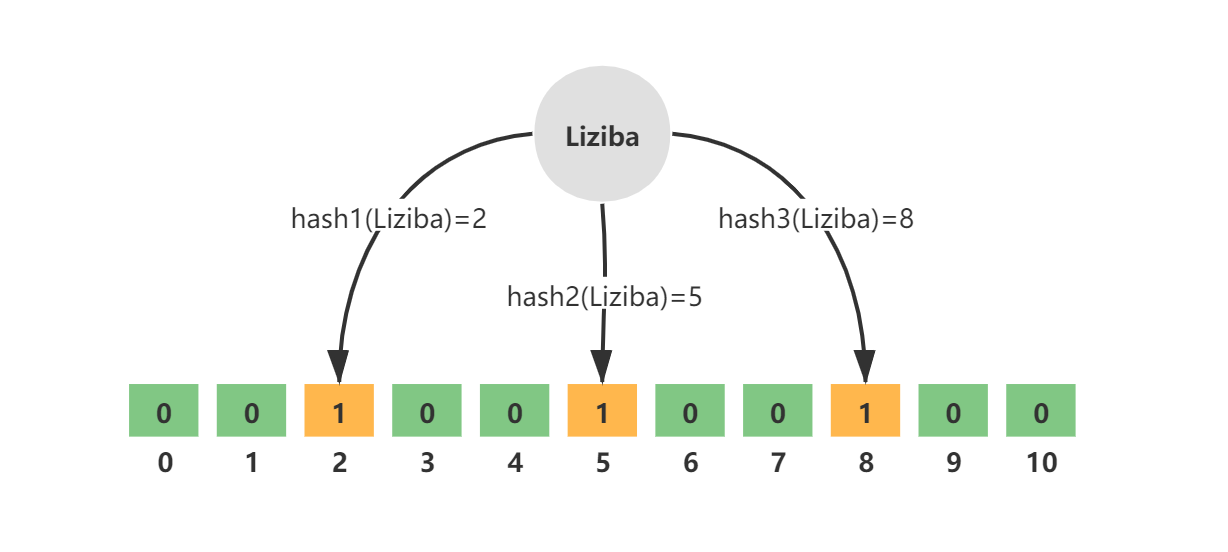
3.3 查询元素
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
4、关于误判
假设,根据误判率,我们生成一个 10 位的 bit 数组,以及 2 个 hash 函数 f1 和 f2,如下图所示:生成的数组的位数 和 hash 函数的数量。这里我们不用去关心如何生成的,因为有数学论文进行验证。
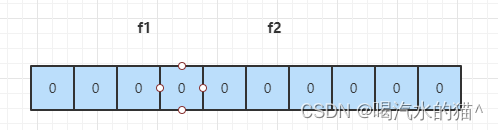
然后我们输入一个集合,集合中包含 N1 和 N2,我们通过计算 f1(N1) = 2,f2(N1) = 5,则将数组下标为 2 和下标为 5 的位置设置成 1,就得到了下图。
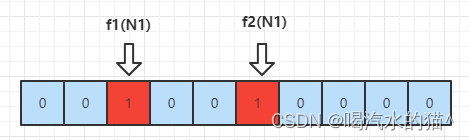
同理,我们再次进行计算 N2的值, f1(N2) = 3,f2(N2) = 6。得到如下所示的图
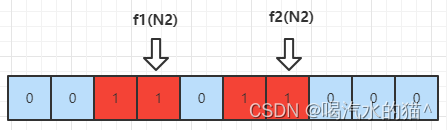
这个时候,假设我们有第三个数 N3 过来了,需要判断 N3 是否在集合 [N1,N2] 中,需要做的操作就是,使用 f1 和 f2 计算出数组中的地址
- 若值恰巧都位于上图的红色位置,我们认为 N3在集合 [N1,N2] 中
-若值有一个不位于上图的红色部分,我们认为N3不在集合 [N1,N2] 中
这就是布隆过滤器的计算原理。
二、使用
在 Java 中使用布隆过滤器,首先需要引入依赖,布隆过滤器拥有 Google 提供的一个开箱即用的组件,来帮助实现布隆过滤器。其实布隆过滤器的核心思想其实并不难,难的是在于如何设计随机映射函数,到底映射几次,二进制向量设置多少比较合适。
1、添加依赖
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
</dependencies>
2、测试
private static int size = 1000000;//预计要插入多少数据
private static double fpp = 0.01;//期望的误判率
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
//插入数据
for (int i = 0; i < 1000000; i++) {
bloomFilter.put(i);
}
int count = 0;
for (int i = 1000000; i < 2000000; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "误判了");
}
}
System.out.println("总共的误判数:" + count);
}
代码分析
上面的代码中,我们创建了一个布隆过滤器,其中有两个重要的参数,分别是我们要预计插入的数据和我们所期望的误判率,误判率率不能为 0 。
我们首先向布隆过滤器中插入 0 ~ 100万 条数据,然后在用 100万 ~ 200万的数据进行测试
最后输出结果,查看一下误判率
1999501误判了
1999567误判了
1999640误判了
1999697误判了
1999827误判了
1999942误判了
总共的误判数:10314
现在有 100万 不存在的数据,误判了 10314 次,通过计算可以得出误判率
10314 / 1000000 = 0.010314
和之前定义的误判率为 0.01 相差无几,这也说明了布隆过滤器在处理 Redis 缓存穿透问题上,也具有比较好的表现。
3、 springboot集成
创建布隆过滤器 Bean
在SpringBoot的Java配置类中,创建布隆过滤器的Bean,并注入相关配置。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class BloomFilterConfig {
private static int size = 1000000;//预计要插入多少数据
private static double fpp = 0.01;//期望的误判率
@Bean
public BloomFilter<String> bloomFilter() {
return BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), size , fpp );
}
}
使用布隆过滤器
在你的服务类或控制器中,注入布隆过滤器的Bean,并使用它进行元素的判重。
package fun.bo.controller;
import com.google.common.hash.BloomFilter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
@RequestMapping("/bloom-filter")
public class BloomFilterController {
@Resource
private BloomFilter<String> bloomFilter;
@GetMapping("/add/{value}")
public String addToBloomFilter(@PathVariable String value) {
bloomFilter.put(value);
return "Added to Bloom Filter: " + value;
}
@GetMapping("/contains/{value}")
public String checkBloomFilter(@PathVariable String value) {
boolean contains = bloomFilter.mightContain(value);
return "Bloom Filter contains " + value + ": " + contains;
}
}
这样,你就成功地将布隆过滤器整合到了SpringBoot项目中。请注意,具体的整合步骤可能会因使用的布隆过滤器库而有所不同,上述步骤仅供参考。在实际项目中,你还可以根据具体需求调整配置和使用方式。


















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











