







目录

一、Broker
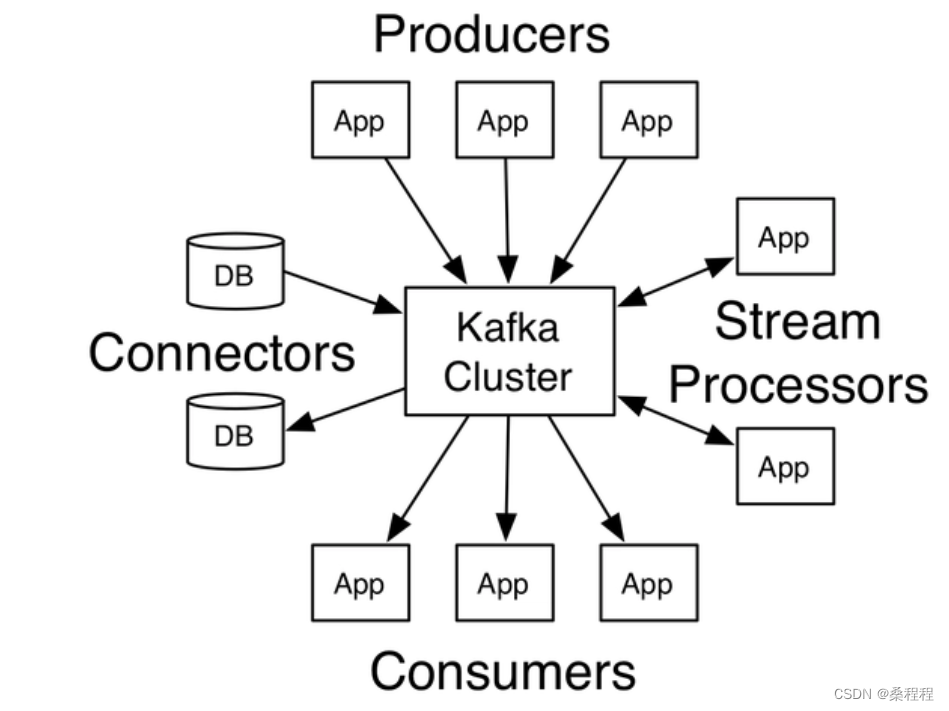
Kafka是一个分布式的、高吞吐量的消息队列系统,它由LinkedIn开发并开源。Kafka的核心组件之一是Broker,它是Kafka集群中的一个节点,负责存储和处理消息。下面是关于Kafka Broker的介绍:
-
消息存储:Kafka Broker负责持久化存储消息。它使用一个可配置的持久化日志来存储消息,每个主题(Topic)对应一个或多个分区(Partition),每个分区包含多条消息的有序序列。分区中的每条消息都有一个唯一的偏移量(Offset),可以通过这个偏移量来读取和定位消息。
-
消息处理:Kafka Broker处理消息的流程是多线程的。它使用一个或多个消费者线程(Consumer Thread)来从订阅的主题分区中读取消息,并将消息发送给订阅者。同时,Kafka Broker还使用一个或多个生产者线程(Producer Thread)来接收来自生产者的消息,并将消息写入相应的分区中。
-
主从复制:Kafka Broker支持主从复制机制,即每个分区都可以有多个副本。其中,一个副本被指定为主副本(Leader),其他副本为从副本(Follower)。主副本负责接收生产者的消息,并进行消息的复制和分发,从副本则负责复制主副本的消息。这种副本复制机制保证了数据的高可用性和容错性。
-
一致性和持久性:Kafka Broker采用了分布式事务日志的设计思路。它使用持久化日志来存储消息,保证消息的持久性和可靠性。同时,Kafka Broker使用ZooKeeper来协调和管理集群中的各个Broker节点,保证集群的一致性和高可用性。
-
扩展性:Kafka Broker具有良好的可扩展性。可以通过增加Broker节点、分区数量和副本数量来水平扩展Kafka集群的吞吐量和容量。
总之,Kafka Broker是Kafka消息队列系统中的核心组件之一。它负责存储和处理消息,具有高吞吐量、可扩展性、高可用性和持久性等特点,为分布式系统中的数据流处理提供了可靠的基础。
二、ZooKeeper
ZooKeeper是一个开源的分布式协调服务框架,它由Apache提供并广泛应用于分布式系统中。在Kafka中,ZooKeeper作为其重要的组件之一,主要用于管理和协调Kafka集群的各个Broker节点,提供了以下功能:
1.集群协调:ZooKeeper负责管理Kafka集群中各个Broker节点的状态和配置信息。每个Broker在启动时会注册到ZooKeeper,并定时向ZooKeeper发送心跳以保持连接。ZooKeeper通过监控Broker的心跳信息,可以检测到Broker节点的上线和下线,并及时通知其他Broker节点。这样,当集群中有节点故障或新增节点时,集群可以自动调整和重新分配分区,保持集群的可用性和负载均衡。11
2.元数据管理:Kafka使用ZooKeeper来存储和管理元数据,包括主题(Topic)、分区(Partition)和副本(Replica)等信息。ZooKeeper提供了一个分布式的命名空间,可以将Kafka的元数据结构化地存储在ZooKeeper的节点中,并提供读写操作接口。通过ZooKeeper,客户端可以动态地获取和更新元数据信息,实现Kafka的高效元数据管理。
3.选举机制:在Kafka集群中,每个分区都有一个主副本(Leader)和零个或多个从副本(Follower)。ZooKeeper通过提供选举机制来选举主副本。当主副本故障或下线时,副本会通过选举机制选举一个新的主副本,确保消息的可靠复制和分发。
4.分布式锁:ZooKeeper提供了分布式锁的实现,可以用于实现Kafka中的各种同步操作。例如,在进行分区重新分配或副本调整时,可以使用ZooKeeper的分布式锁来保证操作的原子性和一致性。
5.高可用性:ZooKeeper本身是一个高可用的分布式系统。它采用了多个节点的复制机制,将数据和状态复制到多个节点,实现数据的容错和持久性。当ZooKeeper节点发生故障时,其他节点可以接替其工作,保证了系统的高可用性。
总之,在Kafka中,ZooKeeper扮演着重要的角色,提供了集群管理、元数据管理、选举机制、分布式锁和高可用性等功能。通过与ZooKeeper的协作,可以实现Kafka集群的高效、可靠和可扩展的运行。
三、Producers
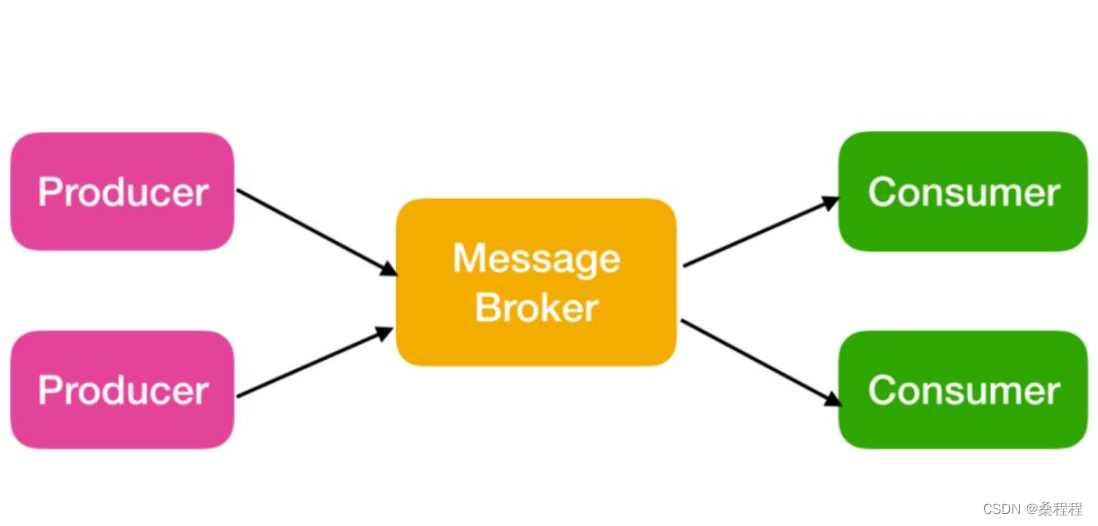
Kafka的Producers是Kafka消息系统中的一部分,用于将数据发布到Kafka集群中的主题(Topic)。Producers负责将数据以消息的形式发送给Kafka,供后续的数据消费者或者其他处理流程使用。
使用Kafka的Producers实现高效、可靠的数据流传输。以下是Producers的几个关键特性:
-
分布式发布:Producers可以将数据发布到Kafka集群中的多个分区,实现数据的分布式存储和处理。这种分布式的发布方式可以有效地提高的处理能力和吞吐量。
-
异步发布:Producers采用异步的方式将数据发送给Kafka,可以实现更高的发布速度。Producers将消息缓存起来,然后以批量的方式发送给Kafka,从而减少了网络开销和资源消耗。
- 可靠性保证:Producers提供了可靠的消息传输机制,确保数据不会丢失。在消息发送过程中,Producers会等待Kafka的确认响应,以确保消息已经被成功写入Kafka的分区中。如果消息发送失败,Producers会自动进行试,直到消息成功写入为止。
分区选择:Producers可以选择将消息发布到Kafka集群中的特定分区,也可以选择让Kafka自动分配分区。分区选择的灵活性使得Producers可以根据业务需求进行数据的定制化处理。
的来说,Kafka的Producers提供了高效、可靠的数据发布机制,为数据流处理提供了强大的基础。通过合理地使用Producers,可以实现实时的数据处理、日志收集、消息队列等诸多应用场景。

四、Consumers
Kafka的Consumers是Kafka消息系统中的一部分,用于从Kafka集群中的主题(Topic)中消费数据。Consumers负责订阅所需的主题,并从相应的分区(Partition)中获取消息进行处理。以下是Kafka的Consumers的几个关键特性:
-
分布式消费:Kafka的Consumers可以以分布式的方式从Kafka集群中的多个分区同时消费数据。这种分布式消费的方式可以实现高吞吐量和并行处理的能力。
-
消费位置管理:Consumers可以自主管理消费的位置。它可以跟踪已消费的消息的偏移量(Offset),并在下次消费时从上一次的位置继续消费。这种机制确保了数据的连续性和顺序性。
-
消费者组:Kafka支持将多个Consumers组织成一个消费者组(Consumer Group)。每个消费者组中的消费者只会消费主题中的一部分分区,以实现负载均衡和水平扩展。当有新的消费者加入或离开消费者组时,Kafka会自动重新分配分区。
-
可靠性保证:Kafka的Consumers提供了可靠的消息传输机制。Consumers可以定期向Kafka发送确认请求,以确保已成功消费数据。如果消费过程中出现错误或中断,Consumers可以重新从上一次的偏移量处继续消费,确保数据不会丢失。
总的来说,Kafka的Consumers提供了强大的数据消费能力,可以实现实时数据处理、日志订阅、消息队列等多种应用场景。通过合理地使用Consumers,可以构建高效可靠的数据处理系统。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











