



一. 动态规划定义和基础应用
动态规划定义:动态规划简称DP,是一种求解多阶段决策过程最优化问题的方法。在动态规划中,通过把原问题分解为相对简单的子问题,先求解子问题,再由子问题的解而得到原问题的解。
我们以斐波那契数列问题来举例:
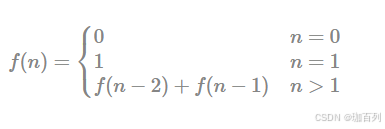 斐波那契数列的示意如图。
斐波那契数列的示意如图。
要点:我们用一个数组(这里假设为dp[])来存储斐波那契数列的所有值,这样在运算的时候就不用反复的计算已经计算过的内容。
class Solution(object):
def fib(self, n):
if n == 0:
return 0
if n == 1:
return 1
dp = [0 for _ in range(0,n+1)]
dp[0]=0
dp[1]=1
for i in range(2,n+1):
dp[i] = dp[i-1]+dp[i-2]
return dp[n]如上代码。
我们把每次算出来的数列的值存储起来,在计算后续的值要使用这个已经算过的值的时候,可以直接用这个已经算出来的值,从而减少了重复计算。
这种使用缓存(缓存方法包括:哈希表,集合,数组等等)保存计算结果,从而避免问题重复计算的方法,就是动态规划算法。
动态规划的特征
- 最优子结构性质
- 重叠子问题性质
- 无后效性
1. 对于最优子结构:
定义:指的是一个问题的最优解包含其子问题的最优解
2. 对于重叠子问题:
定义:指的是在求解子问题的过程中,有大量的子问题史重复的,一个子问题在下一阶段的决策中可能会被多次用到。
注:如果有大量的重复的子问题,止血药求解一次,然后用表格存储下来,以后使用时直接拿来用就可以了,避免了重复求解。
2. 对于无后效性:
定义:也就是一旦一个子问题的求解结果确定以后,就不会再被修改。
注:对于有后效性的问题,需要先将其转化为/逆向求解来消除后效性,再用动态规划求解
动态规划的基本思路:
将解决问题的过程按照一定的顺序分解为若干的小步骤(可以按照时间顺序,空间顺序等等顺序)。
然后按照顺序给每一个小步骤做出决策,这个决策决定了本阶段的效益,同时也决定了下一阶段的初始状态。
这样依次做完所有决策,就得到了一整个问题的决策序列。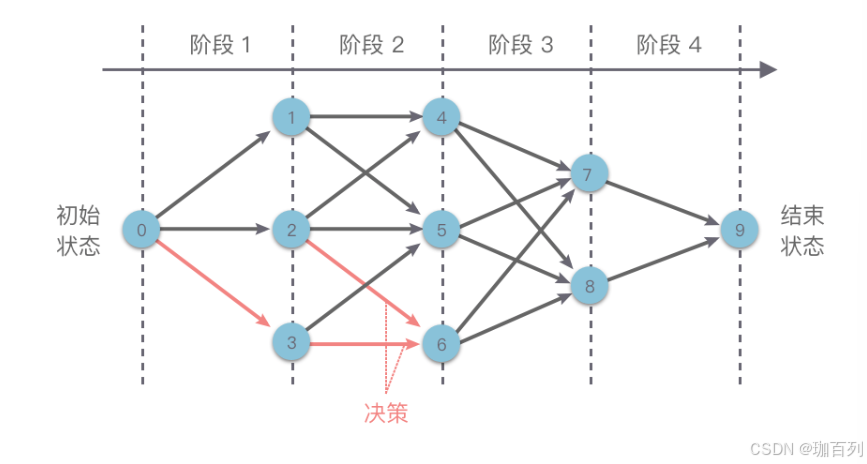
这种前后关联,具有链状结构的多阶段进行决策的问题也叫“多阶段决策问题”。
用动态规划解决问题的基本思路如下:
例如:爬楼梯问题:. - 力扣(LeetCode)
class Solution(object):
def climbStairs(self, n):
dp = [0 for i in range(n+1)]
dp[0] = 1
dp[1] = 1
for i in range(2,n+1):
dp[i] = dp[i-1]+dp[i-2]
return dp[n]
如上代码,对于最主要的dp[i] = dp[i-1] +dp[i-2]:
因为每一次跨步有1步和2步两种情况,所以当我们总共要爬上i阶台阶时,我们上一步行动可能是从第i-1阶开始跨了1步,也可能从第i-2阶开始跨了2步,所以第i阶的爬台阶的方法时两者的和。也就是dp[i] = dp[i-1] +dp[i-2]。
又例如:路径总数问题(不同路径问题):
class Solution(object):
def uniquePaths(self, m, n):
dp =[[0 for _ in range(n)] for _ in range(m)]
dp[0][0] = 1
for i in range(m):
dp[i][0] = 1
for i in range(n):
dp[0][i] = 1
for i in range(1,m):
for j in range(1,n):
dp[i][j] = dp[i][j-1] + dp[i-1][j]
return dp[m-1][n-1]如上代码:

要计算从起点到终点的路径数,我们可以从终点开始分解;要到达终点dp[m][n],一定会从dp[m-1][n]或者dp[m][n-1]迈一步,也就是说对于路径数dp,我们有:dp[i][j]=dp[i-1][j]+dp[i][j-1];
对于初始值dp[0][0] = 1(即特殊的原地踏步),dp[m][0] = 1,dp[0][n] = 1;即第一行/第一列的位置只有一种路径可走,即向下直接走/向右直接走。
假设是个m*n的棋盘,最终状态为:dp[m-1][n-1];
二. 记忆化搜索
记忆化搜索的定义:是一种通过存储已经遍历过的状态信息,从而避免对同一状态重复遍历的搜索算法。
适合记忆化搜索的场景:
1. 问题的状态转移方程比较复杂,递推关系不是很明确
2. 问题适合转化为递归形式,并且递归深度不会太深
记忆化搜索的解题步骤:
例如:第N个泰波那契数
class Solution(object):
def tribonacci(self, n):
memo = [0 for _ in range(n+1)]
return self.result(n, memo)
def result(self, n, memo):
if n == 2 or n == 1:
return 1
if n == 0:
return 0
if memo[n] != 0:
return memo[n]
memo[n] = self.result(n-1, memo) + self.result(n-2, memo) + self.result(n-3, memo)
return memo[n]如上代码:我们建立一个列表memo,存储我们已经计算过的数字,当n=0,1,2时,我们直接返回相应的结果,同时也作为递归的结束条件;当n>2时,我们首先判断memo[n]是否已经被计算过,如果被计算过,我们就不用再重复地算一次,直接返回结果就可以了;若memo[n]没有被计算过,我们就需要使用相应的状态转移方程进行计算。
(详细结果如上)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









