







系统环境:
-
Redis 版本:6.0.8
-
Docker 版本:19.03.12
-
系统版本:CoreOS 7.8
-
内核版本:5.8.5-1.el7.elrepo.x86_64
一、什么是 Redis 集群模式
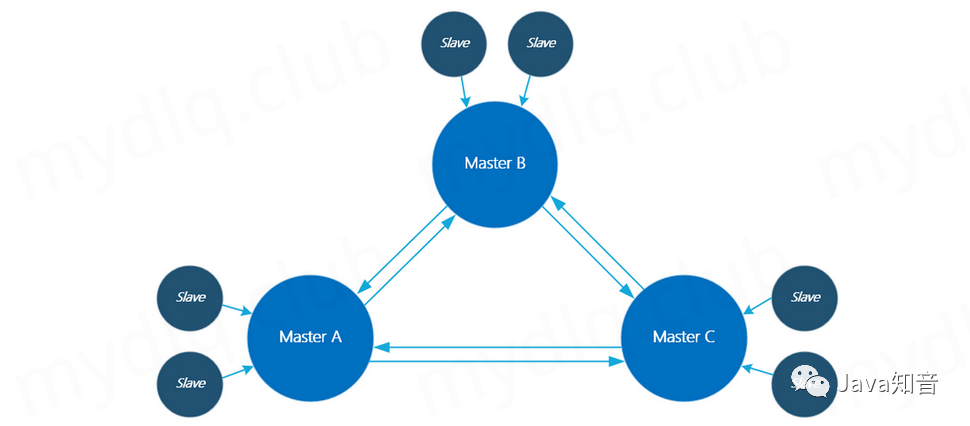
在 Redis 3.0 版本后正式推出 Redis 集群模式,该模式是 Redis 的分布式的解决方案,是一个提供在多个 Redis 节点间共享数据的程序集,且 Redis 集群是去中心化的,它的每个 Master 节点都可以进行读写数据,每个节点都拥有平等的关系,每个节点都保持各自的数据和整个集群的状态。
Redis 集群设计的主要目的是让 Redis 数据存储能够线性扩展,通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下其可以继续处理命令。但是,如果发生较大故障(例如,大多数主站不可用时)时集群会停止运行,即 redis 集群不能保证数据的强一致性。
二、为什么需要 Redis 集群
-
高可用性: Redis 在集群模式下每个 Master 都是主从复制模式,其 Master 节点上的数据会实时同步到 Slave 节点上,当 Master 节点不可用时,其对应的 Slave 节点身份会更改为 Master 节点,保证集群的可用性。
-
数据横向扩展: Redis 是一个内存数据库,所有数据都存在内存中,在单节点中所在服务器能给与的内存是有一定限制。当数据量达到一定程度后,内存将不足以支撑这么多的数据存储,这时候需要将数据进行分片存储,而 Redis 集群模式就是将数据分片存储,非常方便横向扩展。
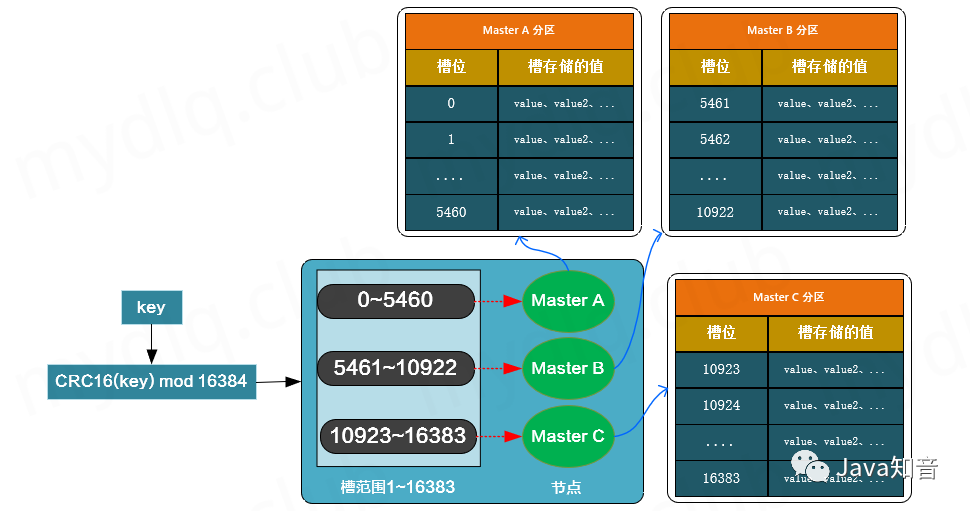
三、Redis 集群的数据分片
Redis 集群没有使用一致性 Hash, 而是引入了”哈希槽”的概念。Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
举个例子,比如当前集群有3个节点,那么:
-
节点 A 包含 0 到 5460 号哈希槽;
-
节点 B 包含 5461 到 10922 号哈希槽;
-
节点 C 包含 10923 到 16383 号哈希槽;
这种结构很容易”添加”或者”删除”节点. 比如如果我想新添加个节点 D,我需要从节点 A, B, C 中得部分槽转移到节点 D 上, 如果我想移除节点 A,则需要将 A 中的槽移到 B 和 C 节点上,然后将没有任何槽的 A 节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
Redis 支持多个 key 操作,只要这些 key 在一个单个命令中执行(或者一个事务,或者 Lua 脚本执行),那么它们就属于相同的 Hash 槽。你也可以用 hash tags 命令强制多个 key 都在相同的 hash 槽中。
四、Redis 集群的主从复制
集群中的主从模型
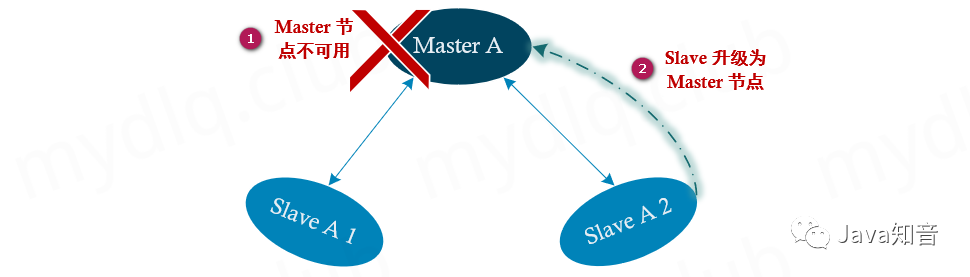
在 Redis 集群模式下,为了防止集群部分节点因宕机等情况造成不可用,故而 Redis 集群使用了主从复制模式。在该模式下要求 Redis 集群至少要存在六个节点,其中三个节点为主节点,能够对外提供读写。还有三个节点为从节点,会同步其对应的主节点的数据。当某个主节点出现问题不可用时,Redis 将通过选举算法从主节点对应的从节点中选择一个节点(主节点存在多个从节点的情况下),将其更改为一个新的主节点,且能够对外提供服务。
例如,在存在 A,B,C 三个主节点和其对应的 (A1、A2),(B1、B2),(C1、C2) 六个从节点,共九个节点中,如果节点 A 节点挂掉,那么其对应的从节点 A1、A2 节点将通过选举算法,选择其中一个节点提升为主节点,以确保集群能够正常服务。不过当 A1、A2 两个从节点或者或者半数以上主节点不可用时,那么集群也是不可用的。
在部署 Redis 集群模式时,至少需要六个节点组成集群才能保证集群的可用性。
主从复制的相关概念
(1)、全量复制与增量复制
在 Redis 主从复制中,分为”全量复制”和”增量复制”两种数据同步方式:
-
全量复制: 用于初次复制或其它无法进行部分复制的情况,将主节点中的所有数据都发送给从节点。当数据量过大的时候,会造成很大的网络开销。
-
增量复制: 用于处理在主从复制中因网络闪退等原因造成数据丢失场景,当从节点再次连上主节点,如果条件允许,主节点会补发丢失数据给从节点,因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。但需要注意,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制。
(2)、记录复制位置的偏移量
-
参与复制的主从节点都会维护自身复制偏移量,主节点在处理完写入命令操作后,会把命令的字节长度做累加记录,可以使用
info replication命令查询master_repl_offset偏移量信息。 -
从节点每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量。
-
从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量,可以使用
info replication命令查询slave_repl_offset偏移量信息。
(3)、复制积压缓冲区
-
复制积压缓冲区(backlog)是保存在主节点上的一个固定长度的队列,默认大小为 1MB,当主节点有连接的从节点时被创建,这时主节点响应写命令时,不但会把命令发给从节点,还会写入复制积压缓冲区,作为写命令的备份。
-
除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(offset) 。由于复制积压缓冲区定长且先进先出,所以它保存的是主节
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









