







* 关于浏览器渲染页面的机制介绍*
**本文讲述了浏览器如何对一个html文件进行解析,最终呈献给用户的过程。
其中的各种是自己的理解,并不代表正确性,但是也大差不差了。
本文并不深入讲解各解析器内部的运行机制。**
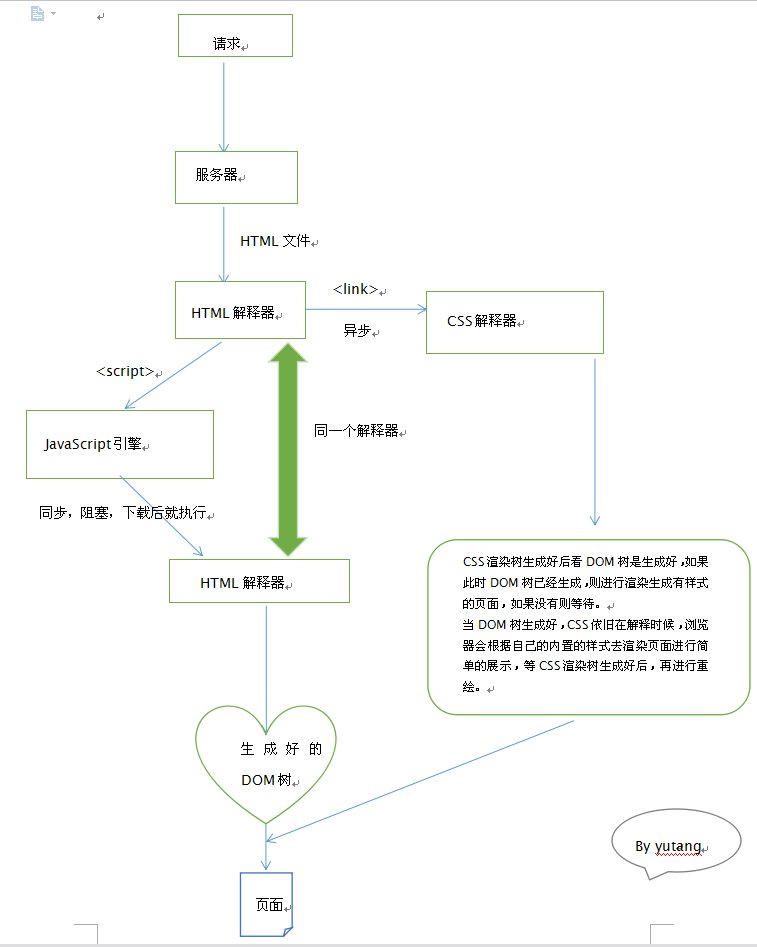
首先我们先简单的介绍一下,浏览器内部关于渲染页面的三大解析器:

其中布局不需要关注。
- HTML解释器是用来解析html文件,同时生存DOM树。
- CSS解释器是用来解析css样式文件,生成样式树。
- JavaScript引擎是用来对js脚本进行解析。
我们从如下的代码里面来详细讲述一下浏览器解析页面的过程。
<!DOCTYPE HTML>
<html>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<link rel="stylesheet" type="text/css" href="page1.css">
<link rel="stylesheet" type="text/css" href="page2.css">
<title>MY NAME IS YU TANG</title>
<body>
<div></div>
<script type="text/javascript" src="jquery-1.12.1.min.js"></script>
<script type="text/javascript" src="page.js"></script>
</body>
</html>当你向服务器进行请求的时候,服务器将会给你返回你请求地址下的html文件,假设如上。
根据一开始文件头的描述,html文件将会给HTML解释器进行处理。
HTML解释器接收到文件后将会顺序依次往下对html文件进行解析。
当遇到<link>元素的时候,此时浏览器将按照元素内部给出的href向服务器进行请求以下载css文件,
此时它不会停下来等到css文件下载好再进行解析而是发出请求后就直接继续向下进行解析,即css的下载是
异步的。
(注:当css文件下载好以后,下载好的css文件将被发送到CSS解释器进行解析。
由于考虑到css中有如下的规则:在相同权重的状态下,后面的样式会覆盖前面的样式。
即如上图中:page1.css与page2.css一前一后,page1.css文件较大。
但是CSS解释器不会进行解析,而是在等待page1下载完成并解析后才会对page2进行解析。)
HTML解释器继续向下按html文件生成dom树。
其中image的加载也是异步的。
当遇到<script>的时候,HTML解释器向服务器发出请求,下载相应的js文件,此时不同于css,js文件的下
载与执行是同步的,阻塞的。即html解析器将会停止解析而是等待js文件下载并执行完毕才会继续往下解
析。
当js文件下载好后,JavaScript引擎将会直接对js脚步进行执行。
完成好html的解析后,页面随即就将被展现,如果此时css渲染树也已经生成好了,浏览器将会对DOM树与渲
染树进行整合生成理想的界面展示出来,如果css渲染树还未完成,浏览器将直接展示内置样式的页面,等到
CSS渲染树生成好,浏览器将重新渲染页面展示最后的效果。这就是为什么有的网站首先看到的是简单的html
页面,之后会突然变绚丽的原因。
(注:根据这样的原理可以进行如下的猜想:浏览器展示什么样的页面主要是去看DOM树是否生成,当DOM树
已经生成但是CSS解释器还没有完成解析的时候,浏览器将会按照内部的样式去布局页面然后展现,等到CSS
解释器完成了在进行重新渲染。页面是否可以展示的标志是DOM树是否生成好。)
总结起来如下图所示:















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









