






最快的方法:目录快速跳转——最快的方法
1.转换脚本的链接:点我
使用命令git clone https://github.com/ssaru/convert2Yolo.git克隆到本地
创建环境conda create -n test2 python=3.8; pip install pillow
2.创建coco.txt文件
将以下内容写入coco.txt文件中
person
bicycle
car
motorbike
aeroplane
bus
train
truck
boat
traffic light
fire hydrant
stop sign
parking meter
bench
bird
cat
dog
horse
sheep
cow
elephant
bear
zebra
giraffe
backpack
umbrella
handbag
tie
suitcase
frisbee
skis
snowboard
sports ball
kite
baseball bat
baseball glove
skateboard
surfboard
tennis racket
bottle
wine glass
cup
fork
knife
spoon
bowl
banana
apple
sandwich
orange
broccoli
carrot
hot dog
pizza
donut
cake
chair
sofa
pottedplant
bed
diningtable
toilet
tvmonitor
laptop
mouse
remote
keyboard
cell phone
microwave
oven
toaster
sink
refrigerator
book
clock
vase
scissors
teddy bear
hair drier
toothbrush
motorcycle
potted plant
dining table
tv
couch
airplane
并将coco.txt改为coco.names
3.在convert2yolo文件夹中创建YOLO文件夹
4.执行脚本
python example.py --datasets COCO --img_path ./val2017/ --label ./annotations/instances_val2017.json --convert_output_path ./YOLO/ --img_type ".jpg" --manifest_path ./ --cls_list_file ./coco.names
5.执行结果和生成文件

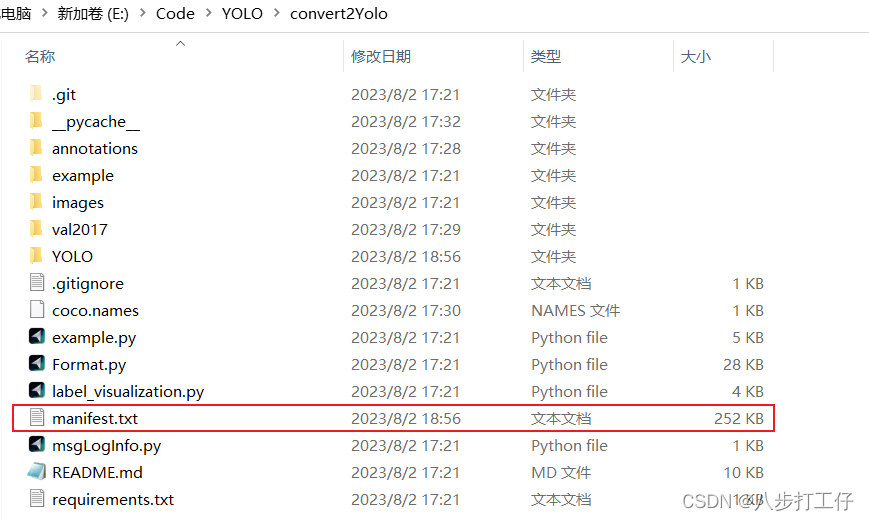
这个过程出现的问题
在YOLO文件夹中生成的标签文件数量为4952个,少于val2017中的5000张图片!!!
最快的方法
参考这位知乎大佬的文章:跳转知乎
code: coco2yolo.py
源码地址
import os
import json
from tqdm import tqdm
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--json_path', default='./instances_val2017.json',type=str, help="input: coco format(json)")
parser.add_argument('--save_path', default='./labels', type=str, help="specify where to save the output dir of labels")
arg = parser.parse_args()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
if __name__ == '__main__':
json_file = arg.json_path # COCO Object Instance 类型的标注
ana_txt_save_path = arg.save_path # 保存的路径
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
id_map = {} # coco数据集的id不连续!重新映射一下再输出!
for i, category in enumerate(data['categories']):
id_map[category['id']] = i
# 通过事先建表来降低时间复杂度
max_id = 0
for img in data['images']:
max_id = max(max_id, img['id'])
# 注意这里不能写作 [[]]*(max_id+1),否则列表内的空列表共享地址
img_ann_dict = [[] for i in range(max_id+1)]
for i, ann in enumerate(data['annotations']):
img_ann_dict[ann['image_id']].append(i)
for img in tqdm(data['images']):
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head + ".txt" # 对应的txt名字,与jpg一致
f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')
'''for ann in data['annotations']:
if ann['image_id'] == img_id:
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))'''
# 这里可以直接查表而无需重复遍历
for ann_id in img_ann_dict[img_id]:
ann = data['annotations'][ann_id]
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))
f_txt.close()
执行脚本:
python coco2yolo.py --json_path ./annotations/instances_val2017.json
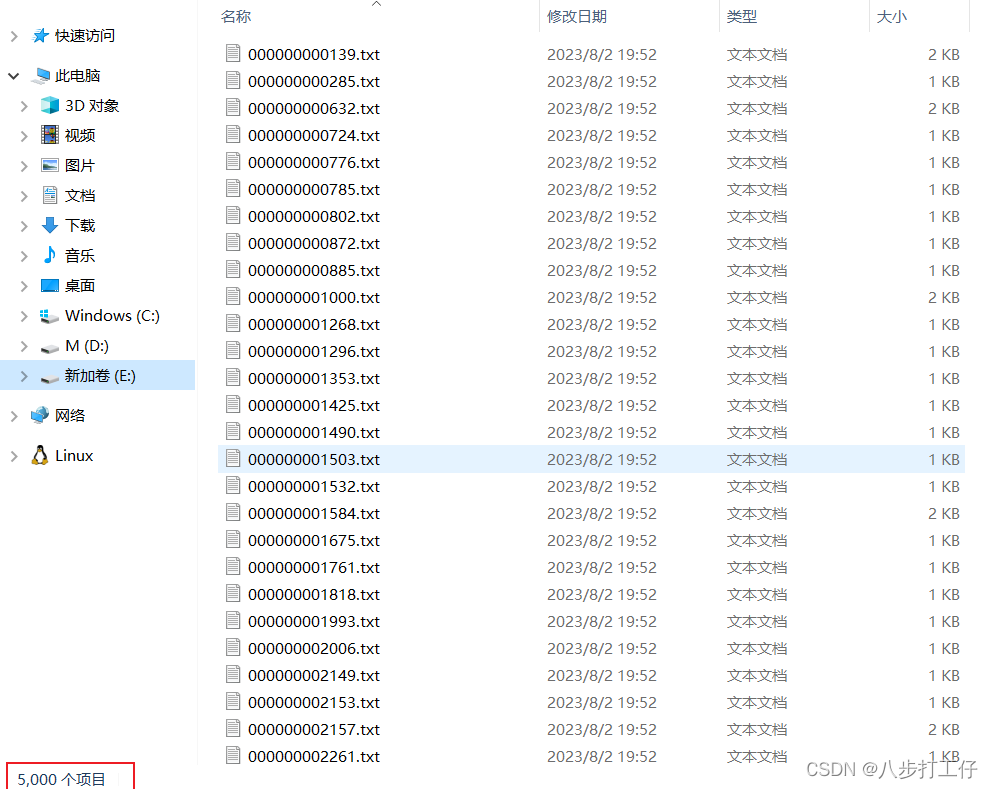
至此,生成的标签文件数和图片数目一致
github上这份源码没试过:点我跳转,但看着可行,先搁这,反正不亏[手动狗头]















 3113
3113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









