






前言
在衡量数据完整性,有个指标就是要统计表的行数。在监控集群的资源使用情况,需要统计表的占用空间。
在观察集群是否有很多小文件,需要统计占用空间/文件个数,可以做一个大致判断。
下面提供了俩个版本,第一个版本构思简单粗暴,效率低。第二个版本,懂数据库人才会想到的,嘿嘿~
第一版本:
- 统计统计行数:
方法:select count(1) from table,
上述方法存在的问题:这个东西一定是要走mr的,如果表非常大的情况下,eg:在千亿级别的数据表(200T),600node*5%的资源,需要跑俩个小时。
2. 统计占用空间:
方法:hadoop fs -du hdfs://username/hive/warehouse/库名/${table_each}_${year_each} |awk ' { SUM += $1 } END { print SUM/(1024*1024*1024) }
问题:需要desc formatted 表名,查找对应的存储地址,在用awk 进行累加,太繁琐了,不惧美观
第二个版本
分为俩个步骤,统计的信息一步到位:
1. 先进行hive表统计信息的收集,这个一般花费,几十秒的时间
方法:anaylze table ${table_each} partition(y='${year_each}',m='${month_each}',d) compute statistics
PS:这边需要注意的地方是,每次收集的分区尽量少点,hive这个功能不稳定,一次性收集的分区较大有可能会失败。大表不建议采用下面的写法 anaylze table ${table_each} partition(y='${year_each}',m,d) compute statistics"。查看是否失败也可以借助下面的sql工具
2.写sql统计工具。下面是通用工具,同学可以直接套用。
SELECT tbl_name,sum(case when param_key='numRows' then param_value else 0 end) 'rownum',
sum(case when param_key='numRows' then 1 else 0 end) 'part_num' ,
sum(case when param_key='totalSize' then param_value else 0 end)/1024/1024/1024 'totalSize',
sum(case when param_key='numFiles' then param_value else 0 end) 'numFiles'
FROM hive_meta.PARTITIONS pt
inner join PARTITION_PARAMS ptp on pt.PART_ID=ptp.PART_ID
inner join hive_meta.TBLS tbl on pt.TBL_ID= tbl.TBL_ID
where tbl_name in ('表名') and owner='虚拟用户'
group by tbl_name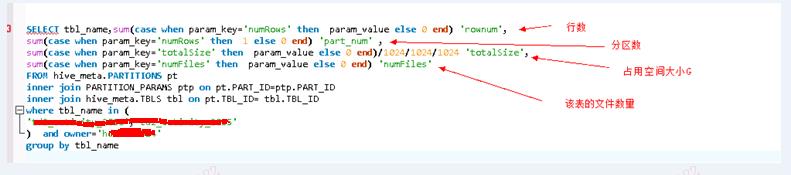
反思
在传统的RDMBS,对数据库的元信息,是做得相当完善。围绕这个元信息,可以构建一个监控系统,完整监控数据库级别,表级别,索引,表类型,表空间,段,区,块,段的设计或者参数配置的合理性。随着hive的发展这块也越来越完善了,而且也越来越多借鉴传统关系数据库的实现。故,温故知新,深入一个领域,可以打开一个宽阔的世界!















 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









