






1,索引 在数据库里也可以叫作‘键’ 主键,唯一,普通索引。存储引擎可以通过索引来快速查到记录的一种数据结构,当表中的数据量越来越大的时候,索引的作用越发的重要
2,考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
3,索引分类
mysql 支持多种存储引擎 每个存储引擎使用的索引各不相同 大概有b+tree ,全文索引,hash索引
4,b-tree 和 b+tree区别
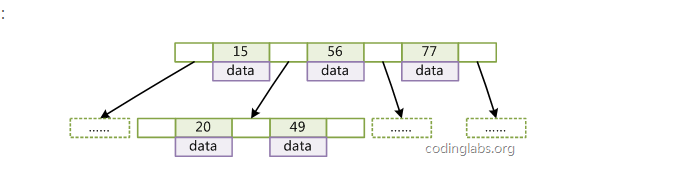
btree:平衡搜索多叉树 非叶子和叶子节点存储key 已经data

b+tree 和b-tree区别在于:b+tree 非叶子节点只存储key 叶子节点才存储data
如上图所示 浅蓝色区域我们称之为磁盘块 ,每个磁盘块包含几个数据项(深蓝色)和指针(黄色) 如:磁盘块1包含 17 35数据项 还有p1 p2 p3三个指针 p1表示小于17的磁盘块 p2 表示大于17小于35的磁盘块 p3表示大于35的 真实的数据存储在叶子节点 3 ,5,9,10,13,15,非叶子节点不存数真实数据
查找过程:
如上图所示,如果要想查找数据项29 那么首先会先将磁盘块1加载到内存中,此时发生一次I/O,在内存中通过二分法迅速找到29在17和35之间,锁定磁盘块1的指针p2(内存查询时间非常短的相对于磁盘查询可忽略不计)通过磁盘块1中的p2指针的磁盘地址将磁盘块3由磁盘加载到内存中 发生第二次IO29在26和30之间 锁定p2指针,通过该指针将磁盘块8加载到内存中 发生第三次IO,内存中二分法查到到29 查询over 总共三次io 3层的b+tree可以存储几百万的数据量,上百万的数据只需三次io 性能提升是比较大的如果没有索引 那么要上百万此io
从中我们能发现 树的高度决定了磁盘io的次数,所以同样的数据量的话 怎么才能让树高度低呢,很显然就是每块磁盘块存储的数据量越大树的高度越低
假设树的高度h
表数据总量N
每个磁盘块数据项是m
则有h=㏒(m+1)N N不变的话m越大 h越小 m = 磁盘块的大小/数据项的大小 磁盘块大小就是一个数据页的大小,是固定不变的 如果数据项占的空间越小,那么存的数据项数量就越多,树的高度越低。这也是为什么索引字段要尽量的小 同样的int(4)要比int(8)少一半 ,这也不难解释为啥b+tree非叶子节点不存真实数据
索引的最左匹配特性(从左往右匹配):当使用了复合索引的时候 比如(name,age,phone) b+tree 时从左往右的顺序来建立索引树 当(jay ,12,18999999999)这样的数据来检索的时候 会优先比较name确定下一步的搜索方向,如果name相同的话再比较age 和 phone。 但是如果是(12,189999999)这样来检索的时候 那么btree就不知道下一步该查询哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索判断下一步的方向所有这就用不到索引了
如果(jay ,189999999)这样的数据来搜索时 会先用name来指定搜索方向,但是age没有 那么只能把名字=jay 的所有数据都找到然后再匹配phone的数据
5,创建索引的原则
索引并不是越多越好,创建合适的索引才能起到好的效果
1,必须得符合最左匹配原则
2,尽量给那些离散度高的字段添加索引 count(distinct col)/count(*) 离散度高的比如姓名 电话 离散度低的不如性别 就两种
如果离散度低的字段添加索引 查询的时候 查询优化器反而会认为走全表更加快
3,索引列不能参与计算















 1995
1995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









