







查看19lou.com的Cookie
chrome中打开19lou.com,按F12可以打开开发者工具查看
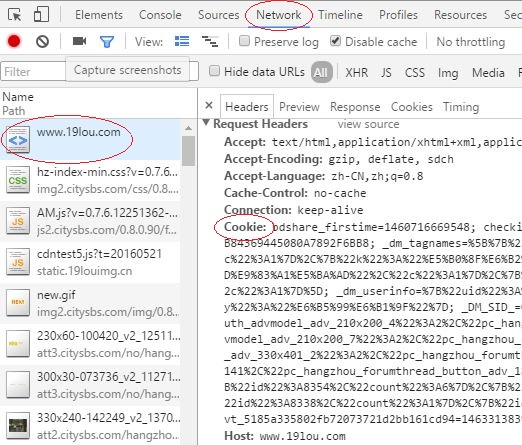
不获取Cookie会导致爬取网站时重定向而抓不到内容
定义headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1',
'Referer':'http://www.19lou.com',
'Cookie':"your cookie"}请求页面
try:
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
except:
print 'server connect failed'
raw_input('Press enter key to exit')
exit()BeautifulSoup解析网页
整个网页结构

首先用开发者工具找出需要获取到的元素位置
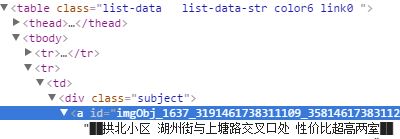
用BeautifulSoup解析
html = response.read()
soup = BeautifulSoup(html,"html.parser",fromEncoding="gb18030")
for child in soup.table.find_all('a'):
url = child.get('href')
pass 循环 <a> 标签获取所有子页面的url,然后请求详情页获取租房信息和图片
详情页解析
for child in soup.table.find_all('a'):
url = child.get('href')
try:
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
except:
print 'server conect failed'
raw_input('Press enter key to exit')
exit() 通过开发者工具查看详情页结构,抓取相关信息
html = response.read()
soup = BeautifulSoup(html,"html.parser",fromEncoding="gb18030")
ul = soup.find('ul',{'id':'slide-data'})
tr = soup.find('table',{'class':'view-table link0'}).find_all('tr')
hx = tr[2].td.get_text() #获取 户型 信息
#循环获取房屋图片地址
for row in ul.find_all('li'):
image = row.find('a',{'class':'J_login nail'}).img.get('src')
image_big = row.find('p').img.get('src')以上为部分讲解,下面是代码链接
抓取到的信息
github完整代码
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









