







随着业务发展,系统拆分导致系统调用链路加发复杂,一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的。

通过整合Zipkin+sleuth,实现分布式系统调用跟踪。
一、组件说明
1.1 Zipkin
Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现,它致力于收集服务的定时数据,以及解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
1.2 sleuth
sleuth是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具
二、Zipkin服务端
三、微服务集成Zipkin
在需要继承Zipkin的所有微服务中加入依赖和配置内容
3.1 引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
3.2 配置文件
Spring:
zipkin:
base-url: http://127.0.0.1:9411 # zipkin服务地址
sender:
type: web
sleuth:
sampler:
probability: 1 # 日志记录采样率,1为100%,默认为0.1即10%
四、测试
这里搭建了两个服务order-server和goods-server,订单下单减少商品库存。
从Zipkin平台可以看到两个服务
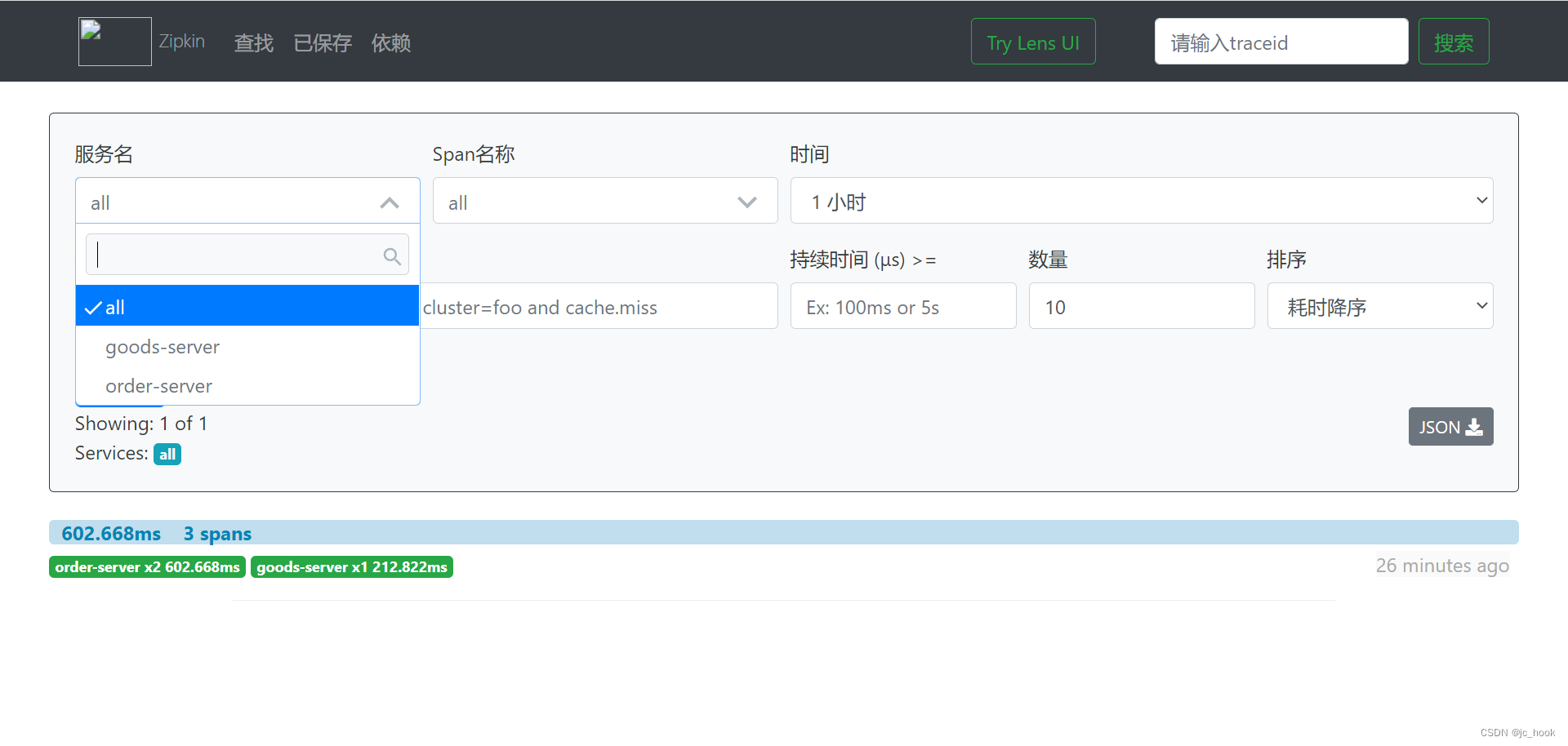
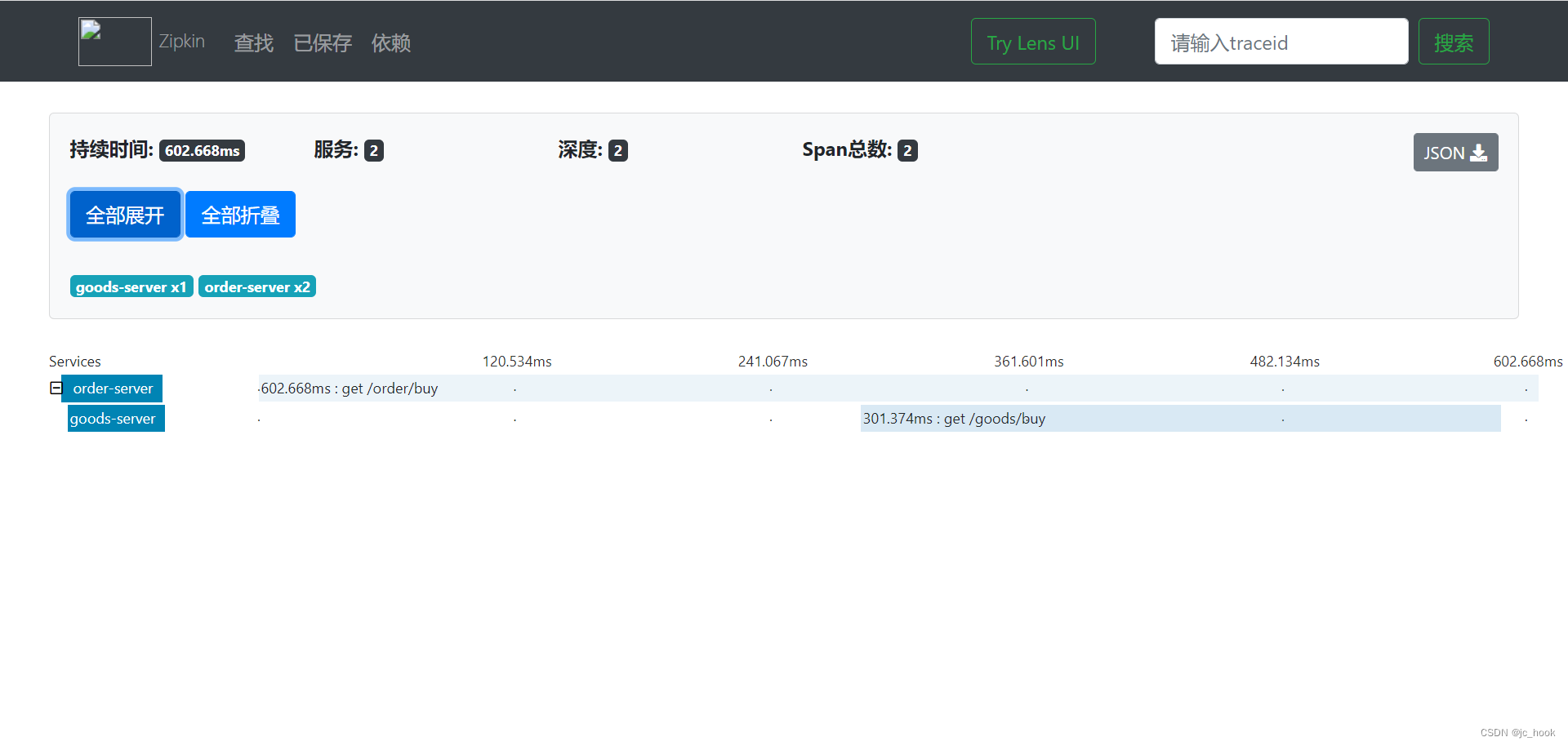
也能查看到对应请求顺序和所有时间
















 3428
3428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









