







Myeclipse运行Hadoop(适合新手阅读)
很久不写东西了,最近一直在对大数据进行研究,研究了几天搭建了一套简单的Hadoop环境,连接Myeclipse,并成功地运行了Hello World。
希望这篇文章可以帮助到初学者完成Hello World,也算是成功地踏出第一步。
一步一步跟着做,不放弃,就可以成功。
- 首先要有一套Linux环境
- 伪分布式Hadoop模式
- Myeclipse连接Hadoop
- 编写第一个MapReduce
- 调试并运行HelloWorld
首先要有一套Linux环境
工欲善其事必先利其器,搭建一套Linux环境是一切的基础。
这里采用的是虚拟机Linux:
1.安装VMware Workstation(以下简称VM)

2.在VM中安装Ubuntu 64位系统,版本为【ubuntu-16.04.1-server-amd64.iso】
具体安装步骤,可以参照Ubuntu安装教程
3.安装好后,登录Linux,表示安装成功
4.安装两款比较实用的工具
Xshell
用于可以远程连接Linux,操作起来要比直接操作虚拟机方便很多
Xftp
用于向Linux中传输文件、安装包等,如果熟练也可以直接拷贝至虚拟机内
完成以上步骤,一台Linux环境就搭建好了。
伪分布式Hadoop模式
在Linux上安装并运行Hadoop。
这里使用的版本是JDK1.6/Hadoop-1.0.3(截止到发稿时Hadoop的最新版本已经是2.6.5,这里使用1.0.3全当是做为学习使用):
安装JDK 1.6
1.下载JDK,版本为【jdk-6u27-linux-x64.bin】,使用Xftp拷贝到Linux中(这里安装目录为/usr/lib/jvm/jdk)
注:尽量使用root用户拷贝,普通用户可能导致没有权限的问题
2.进入JDK的安装目录,并输入命令
chmod u+x jdk-6u27-linux-x64.bin注:如果提示权限错误,在此命令前加 sudo,使用root用户则不用加
3.修改权限后可以进行安装,输入命令
-s ./jdk-6u27-linux-x64.bin4.配置环境变量
a) 打开配置文件
vim /etc/profile b) 输入如下内容
\#set Java Enviorment
export JAVA_HOME=/usr/lib/jvm/jdk/jdk1.6.0_27
export CLASSPATH=".:\$JAVA_HOME/lib:\$CLASSPATH"
export PATH="\$JAVA_HOME/bin:\$PATH"c) 让配置生效
source /ect/proflec) 验证是否安装成功
java -version出现JDK版本信息

安装并运行Hadoop
这里采用比较简单的伪分布式配置,仅用于学习,真实环境应部署集群
1.下载Hadoop,版本为【hadoop-1.0.3.tar.gz】,使用Xftp拷贝到Linux中(这里安装目录为/home/suych)
tar -zxvf hadoop-1.0.3.tar.gz2.进入Hadoop的安装目录的conf文件夹,修改配置文件hadoop-env.sh,输入如下内容
export JAVA_HOME=/usr/lib/jvm/jdk/jdk1.6.0_273.配置HDFS(Hadoop的分布式文件系统)的地址及端口号,修改配置文件core-site.xml(同在conf文件夹中)
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.237.130:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/suych/hadoop_tmp/dfs</value>
</property>
</configuration>4.配置HDFS,修改配置文件hdfs-site.xml(同在conf文件夹中)
<configuration>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/suych/hadoop_tmp/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/suych/hadoop_tmp/dfs/data</value>
</property>
</configuration>5.配置MapReduce,修改配置文件mapred-site.xml(同在conf文件夹中)
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.237.130:9001</value>
</property>
</configuration>6.格式化Hadoop的文件系统HDFS,在Hadoop文件夹中输入命令
bin/hadoop namenode -format7.启动Hadoop,输入命令
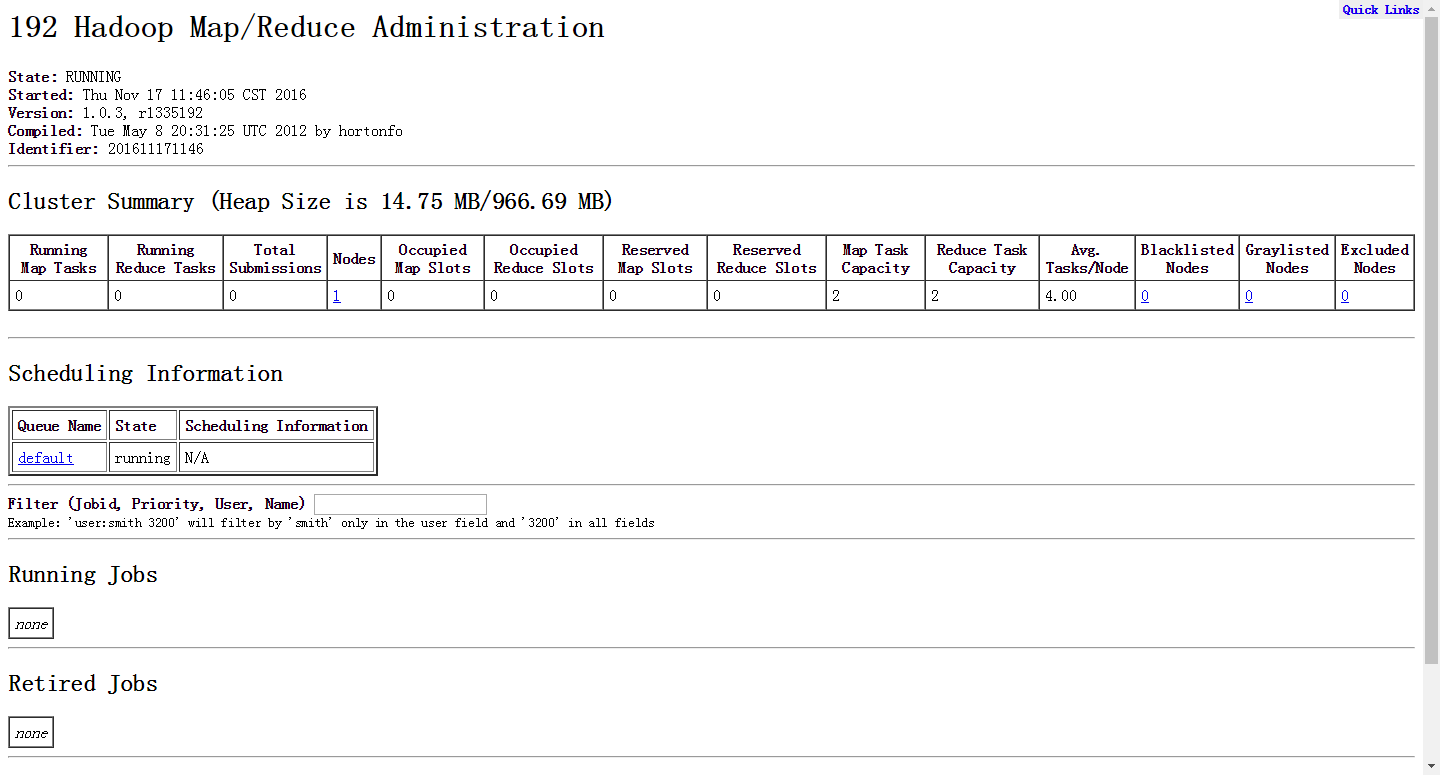
bin/start-all.sh8.打开浏览器,输入网址
http://ip:50030(MapReduce的页面)
http://ip:50070(HDFS的页面)
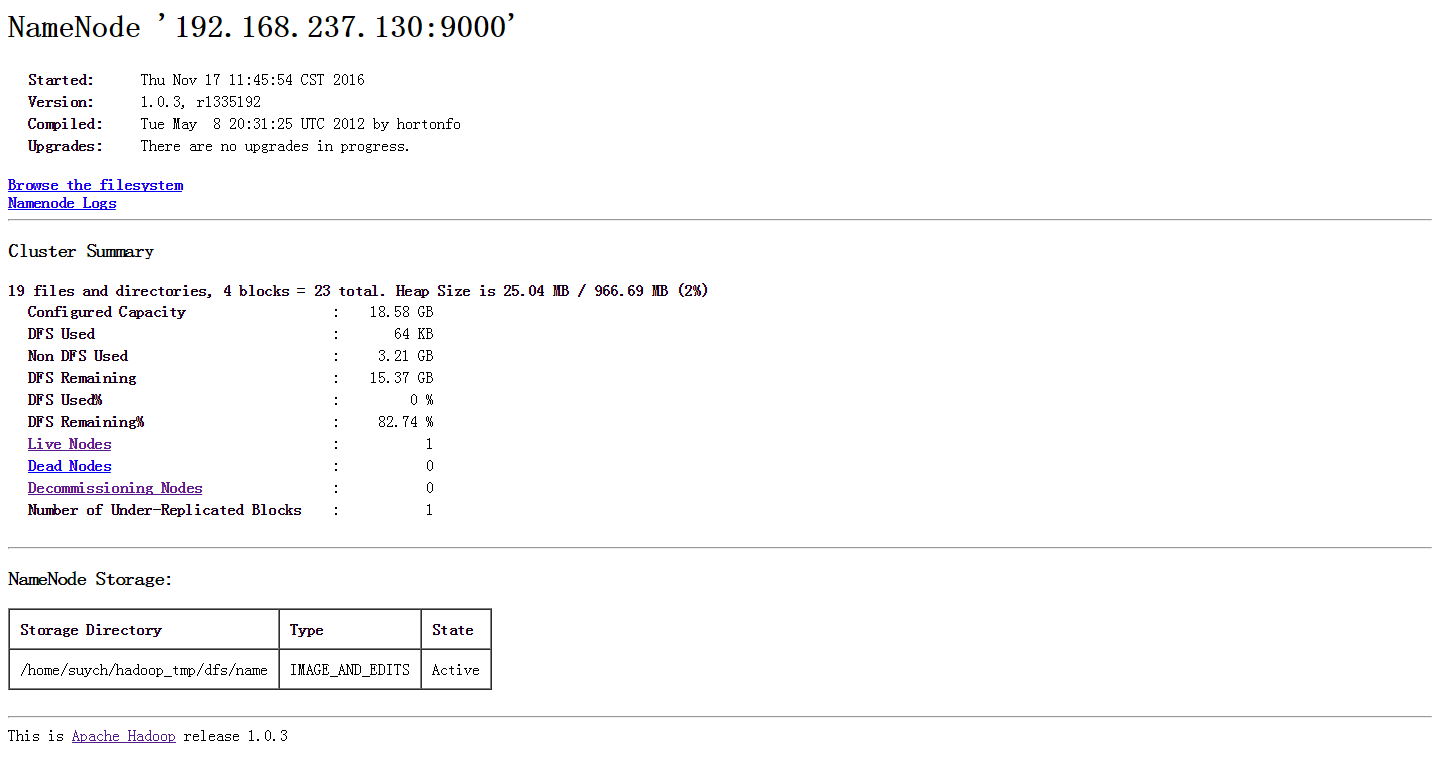
完成以上步骤,一套伪分布式Hadoop就搭建好了。
Myeclipse连接Hadoop
在Myeclipse上安装Hadoop插件。
这里使用的Myeclipse版本是【Myeclipse 10】。
安装Myeclipse的Hadoop插件
1.下载插件,版本为【hadoop-eclipse-plugin-1.0.3.jar】,放在文件夹
D:\Program Files (x86)\MyEclipse\MyEclipse 10\dropins\plugins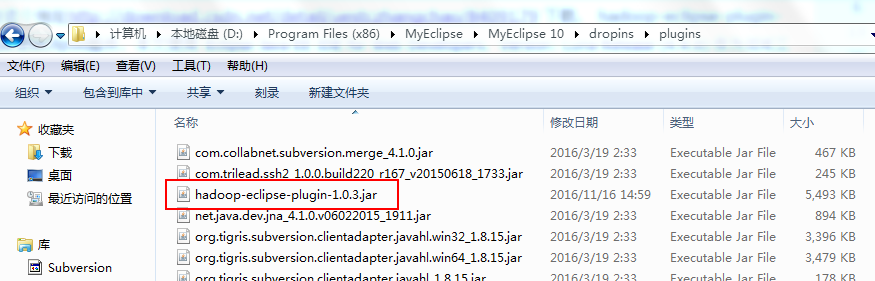
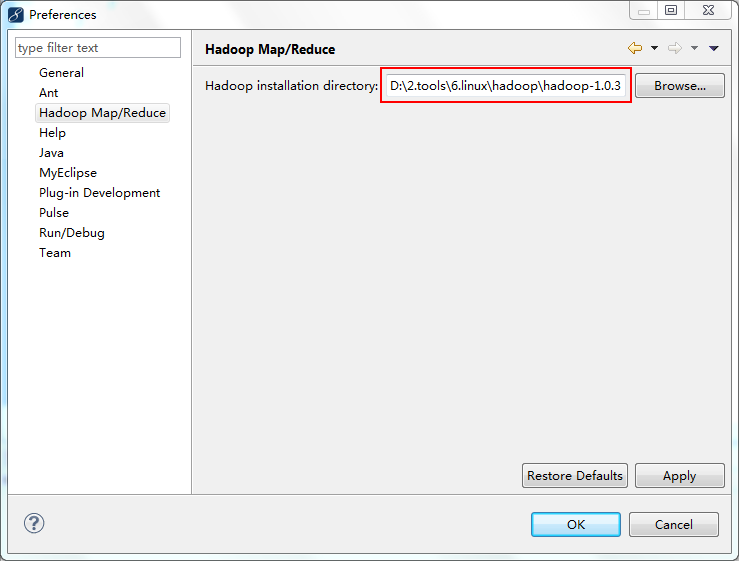
2.在Windows->Preferences中,选择Hadoop Map/Reduce,设置好Hadoop的安装目录(把Hadoop安装包解压到本地一份)
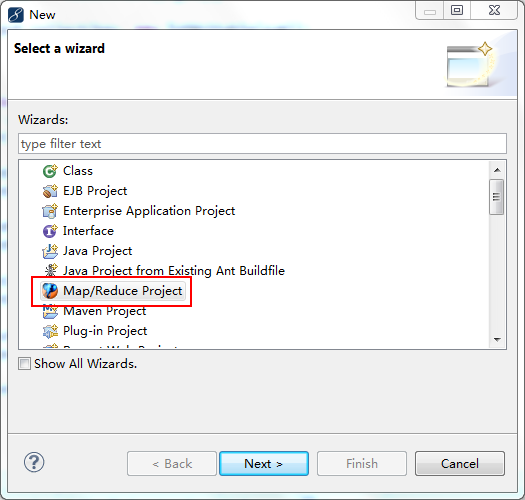
3.新建一个Map/Reduce Project
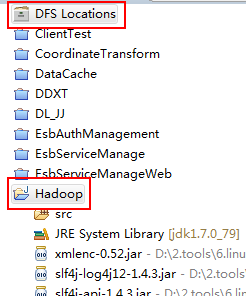
4.新建Map/Reduce Project后,会生成如下的两个目录, DFS Locations和Hadoop的Java工程
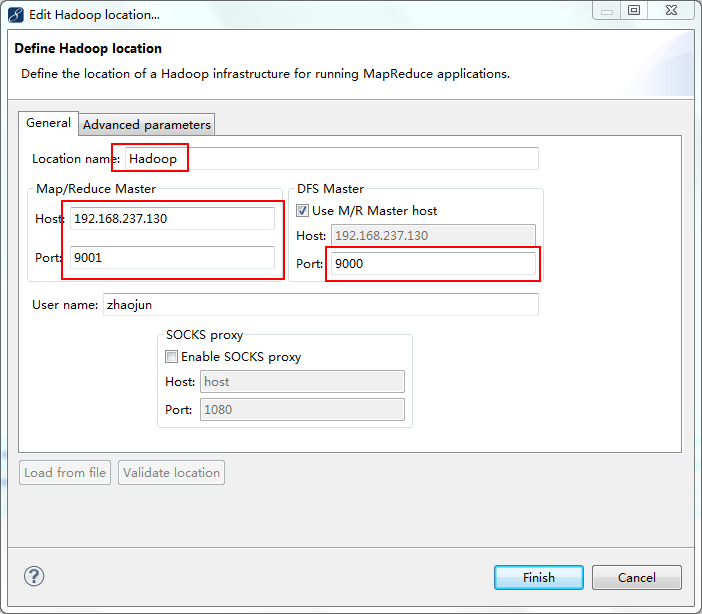
5.在Map/Reduce Locations视图中新建Hadoop Location

6.配置Hadoop Location信息
7.保存后重新编辑刚才建立的Location,编辑advance parameters tab页
(重启编辑advance parameters tab页原因:在新建连接的时候,这个advance paramters tab页面的一些属性会显示不出来,显示不出来也就没法设置,所以必须保存后再编辑才能看到)
这里大部分的属性都已经自动填写上了,其实就是把core-defaulte.xml、hdfs-defaulte.xml、mapred-defaulte.xml里面的一些配置属性展示出来。因为在安装hadoop的时候,其site系列配置文件里有改动,所以这里也要弄成一样的设置。


然后点击Finish,连接成功(保证Hadoop进程已经启动)
完成以上步骤,Myeclipse和Hadoop之间的连接就建立好了。
编写第一个MapReduce
开发第一个MapReduce程序
编写如下代码:
package com.pcd.hadoop;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws IOException {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
调试并运行HelloWorld
调试HelloWorld
上传模拟数据文件夹
为了运行程序,需要一个输入的文件夹和输出的文件夹。输出文件夹,在程序运行完成后会自动生成。我们需要给程序一个输入文件夹。
1.在当前目录(如hadoop安装目录)下新建文件夹input,并在文件夹下新建两个文件file1、file2,这两个文件内容分别如下:
file1
Hello World Bye World file2
Hello Hadoop Goodbye Hadoop 注:文件名可以不要尾缀。
2.将文件夹input上传到分布式文件系统中。
在Hadoop文件夹中,输入如下命令
bin/hadoop fs -put input in 注:可能遇到因为多次格式化HDFS,所导致的问题。
需要修改/home/suych/hadoop_tmp/dfs/data/current目录中VERSION文件,把datanode的namespaceID和namenode的namespaceID,修改成一致即可。
配置运行参数
1.在新建的项目WordCount,点击WordCount.java,右键–>Run As–>Run Configurations
2.在弹出的Run Configurations对话框中,点Java Application,右键–>New,这时会新建一个application名为WordCount
3.配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”
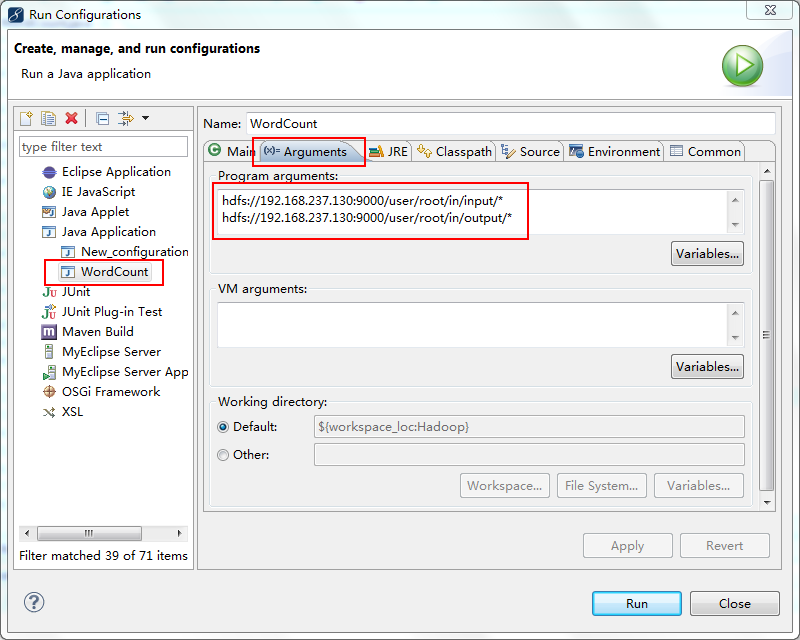
点击Run,运行程序
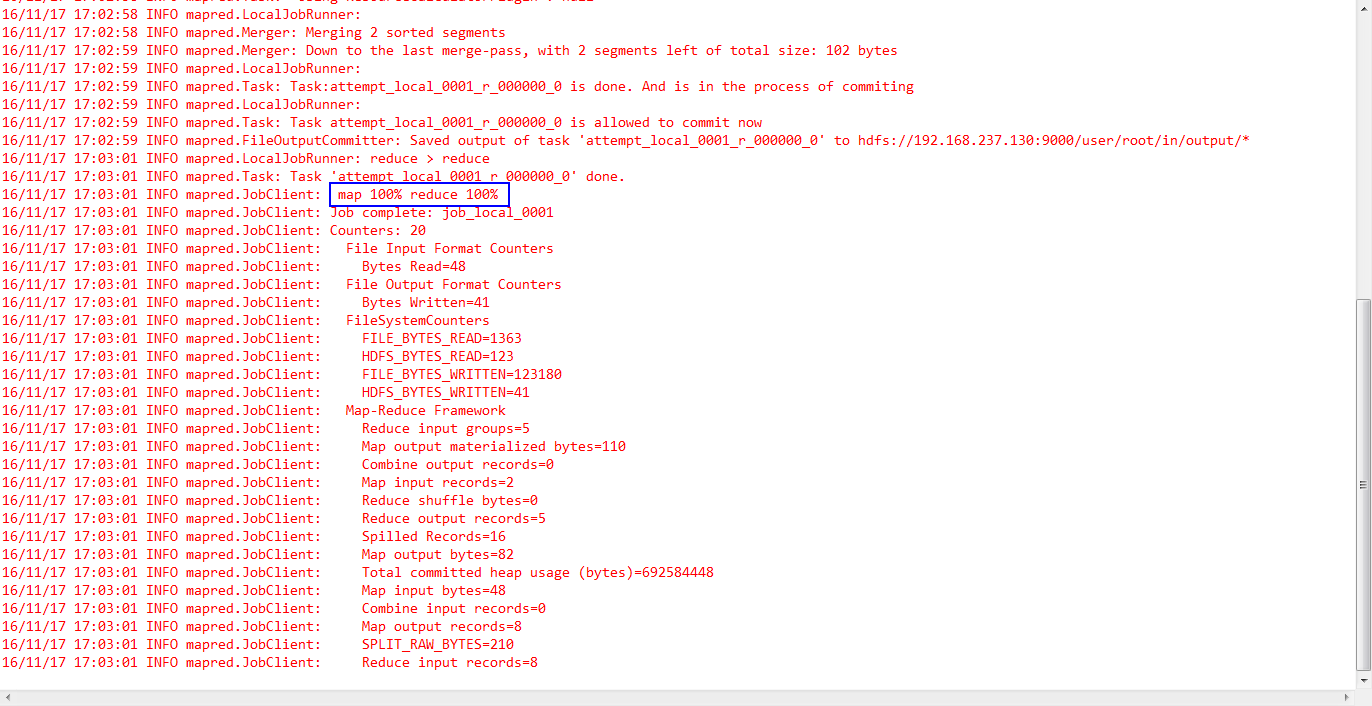
1.在控制台可以看到如下结果
2.在Myeclipse的DFS Locations中可以看到运行程序(统计word)的结果
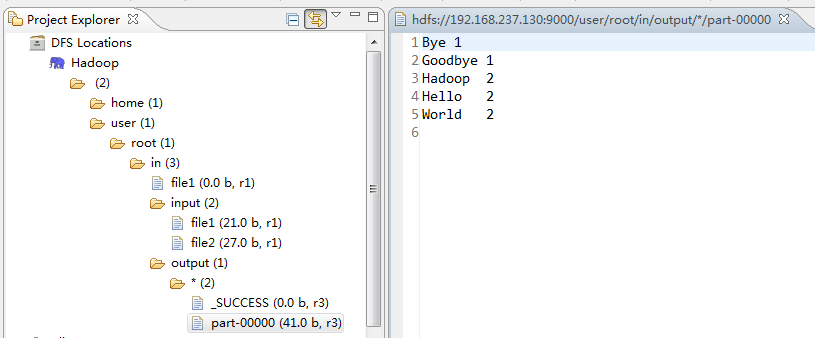
完成以上步骤,HelloWorld程序就调通了。
本文参考下面两个链接,感谢他们,前人栽树,后人乘凉。
Hadoop Eclipse开发环境搭建
myeclipse配置hadoop开发环境















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









