







也可以用使用jieba_fast优化切词速度 jieba_fast介绍
import jieba_fast as jieba
import jieba
from collections import Counter
import pandas as pd
import re
import warnings
warnings.filterwarnings('ignore')
"""
df:Dataframe格式数据
df['content']:要进行词云统计的那列文本名称
"""
def cipin(df):
cut_words=""
for i in range(len(df)):
df['content'][i] = re.sub("[A-Za-z0-9\:\·\—\,\。\“ \”\#\\u200b\&,\_\.]", "", df['content'][i])
seg_list=jieba.cut(df['content'][i],cut_all=False)
cut_words+=(" ".join(seg_list))
df = 0
all_words=cut_words.split()
c=Counter()
for x in all_words:
if len(x)>1 and x != '\r\n':
c[x] += 1
data = pd.DataFrame([])
for (k,v) in c.most_common(500):# 输出词频最高的前500个词
data = data.append(pd.DataFrame({"key_word":[k], "count":[v]}), ignore_index=True)
print(display(data.head(5)))
return data
结果
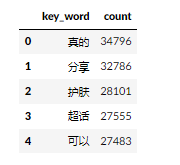
另外一种超简洁的写法
import pandas as pd
import jieba
def cal_word_freq(texts):
words = []
for text in texts:
words.extend(list(jieba.cut(text)))
return pd.Series(words).value_counts()
但是缺点是数据基本没有预处理,所以效果不太理想,请自行探索
示例
sents = ["""抱一抱就当作从没有在一起
好不好要解释都已经来不及
算了吧我付出过什么没关系
我忽略自己就因为遇见你
没办法好可怕那个我不像话
一直奋不顾身是我太傻
"""]
cal_word_freq(sents)
结果
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











