






为什么要了解变量赋值?
变量赋值牵涉到对象和变量名,理解对象和变量名之间的区别和联系将对你有如下帮助:
(1)帮助你更精准预测代码的行为和内存的使用情况;(2)避免代码运行过程中不必要的对象复制,从而加快代码运行的速度;(3)帮助你进一步了解R语言函数式编程的原理。
理解绑定(banding)
x <- c(1, 2, 3)
阅读上面这行代码,我们自然地理解为:”创建一个名为x的对象,其包括元素值1,2和3“。但实际上这种理解是不准确的,我们可以认为这行代码背后做了两件事情:(1)创建一个向量对象,即c(1, 2, 3);(2)将这个对象和变量名x绑定起来。换句话说对象可以有一定的类型但是没有名字,而变量名可以通过和对象绑定从而指向一定的值。
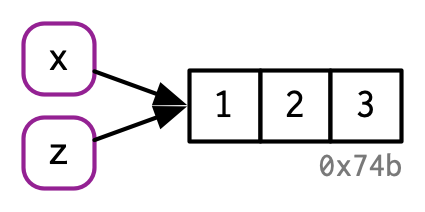
可以参考下图进一步理解,左边方框中的变量名x和右边的向量对象通过绑定从而联系起来。右边对象下方的”0x74b“可以理解为这个向量对象的识别符(identifier),实际上是该对象在内存中的存储地址。一个对象的存储地址可以通过R包lobstr的obj_addr()函数进行获取。
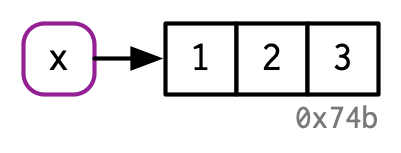
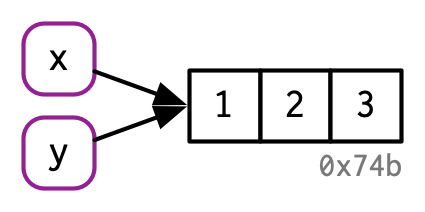
此时如果将变量x赋值给y,那么x和y会指向同一个对象。
y <- x
##通过lobstr::obj_addr()查看x和y的存储地址
obj_addr(x)
#> [1] "0x7fe11b31b1e8"
obj_addr(y)
#> [1] "0x7fe11b31b1e8"
符合语法规则的变量名(syntactic names)
R的变量名要求由字母、数字、下划线、小数点组成, 开头不能是数字、下划线、小数点, 中间不能使用空格、减号、井号等特殊符号, 变量名不能与if、NA等保留字相同(可用?Reserved命令查看所有的保留字)。有时为了与其它软件系统兼容, 需要使用不符合规则的变量名, 这时只要将变量名两边用反引号 (``)保护即可。
值得一提的是在用read.csv()读取文件时,不符合命名规则的变量名会被强制改为符合命名规则的名称(比如有的基因名称中的"-“会被改变成”.",造成一定的麻烦),这时候可以通过check.names 参数进行关闭这种强制行为。另外 make.unique()和make.names()也是和变量名相关的函数,感兴趣的读者可继续了解。
Copy-on-modify机制
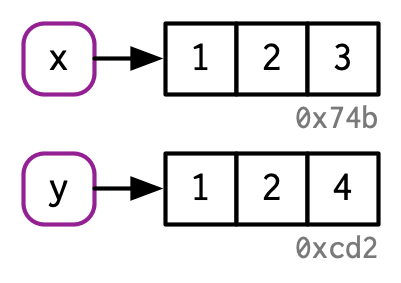
以下代码将x和y同时绑定至同一向量,然后再修改变量y。
x <- c(1, 2, 3)
y <- x
y[[3]] <- 4
x
#> [1] 1 2 3
虽然开始x和y指向同一对象(0x74b),但当改变变量y,变量x并没有改变。x仍然指向原来的向量对象(0x74b),而y则指向了修改后的另一个副本对象(0xcd2),这个对象实际上是通过复制原来的对象(0x74b)并进行对应的修改得来的。即复制行为是通过修改而引发的,故这种行为称为copy-on-modify。
tracemem()函数
你可以通过base::tracemem函数观测一个对象是否被复制。如果对一个对象使用这个命令,首先会返回这个对象的存储地址,之后如果这个对象发生了复制则会输出对应的地址变化信息,除非使用 base::untracemem()函数取消对这个对象的跟踪。
x <- c(1, 2, 3)
cat(tracemem(x), "\n")
#> <0x7f80c0e0ffc8>
y <- x
y[[3]] <- 4L
#> tracemem[0x7f80c0e0ffc8 -> 0x7f80c4427f40]: #提示发生一次复制
Function calls
以上讲的关于变量的复制规则也适用于函数使用时。
f <- function(a) {
a
}
x <- c(1, 2, 3)
cat(tracemem(x), "\n")
#> <0x7fe1121693a8>
z <- f(x)
# 调用函数过程中并没有发生复制,即变量z和x指向同一对象!
untracemem(x)
当函数运行时,函数里的a变量将会指向x指向的对象:
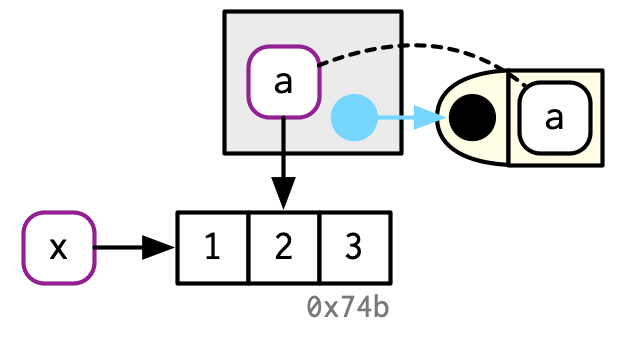
从上面的例子可以看出, 函数f以x为实参, 但不修改x的元素, 不会生成x的副本(不发生复制), 返回的值是x指向的对象本身, 再次赋值给z, 也不制作副本, z和x绑定到同一对象(0x74b)。
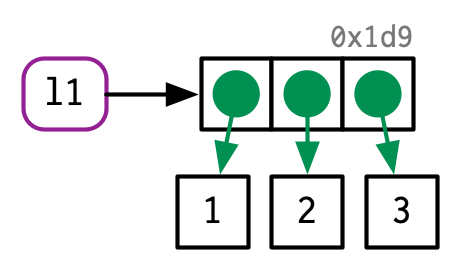
Lists
l1 <- list(1, 2, 3)
对于列表了l1而言,表面上似乎和上面提到的数字向量类似(即l1指向了一个包括三个元素的列表对象)。但实际上列表会更加复杂一点,因为列表存储的不是值本身而是存储指向某些值的链接。
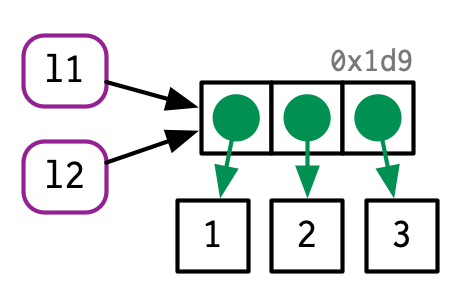
当改变一个列表时:
l2 <- l1
l2[[3]] <- 4
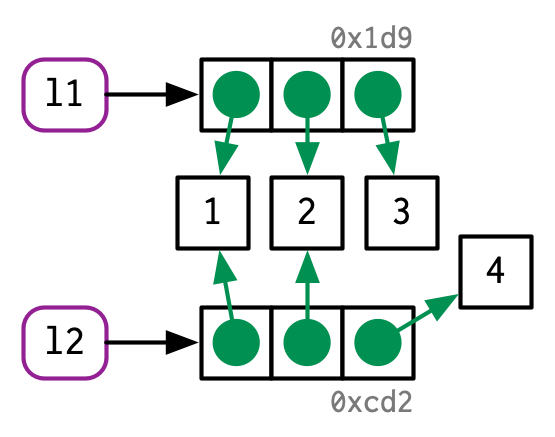
和数字向量一样,列表同样遵守 copy-on-modify规则。即原始的列表被保留下不作变化,R会创建一个经过修改的副本。但这里复制其实是浅拷贝(shallow copy),简单讲就是l2和l1并不是完全独立的两个对象,l2中未经改变的元素(前两个元素)还是和l1共享的。
为了观察两个列表中元素的共享情况,可以用lobstr::ref()函数输出每个列表元素的存储地址,存储地址相同的元素就是共享的元素。
ref(l1, l2)
#> █ [1:0x7fe11166c6d8] <list>
#> ├─[2:0x7fe11b6d2078] <dbl>
#> ├─[3:0x7fe11b6d2040] <dbl>
#> └─[4:0x7fe11b6d2008] <dbl>
#>
#> █ [5:0x7fe11411cc18] <list>
#> ├─[2:0x7fe11b6d2078]
#> ├─[3:0x7fe11b6d2040]
#> └─[6:0x7fe114130a70] <dbl>
Data frames
数据框(data frames)是由多个向量组成,copy-on-modify规则在数据框中也成立,数据框中的每个元素都指向某个对应的向量。
d1 <- data.frame(x = c(1, 5, 6), y = c(2, 4, 3))
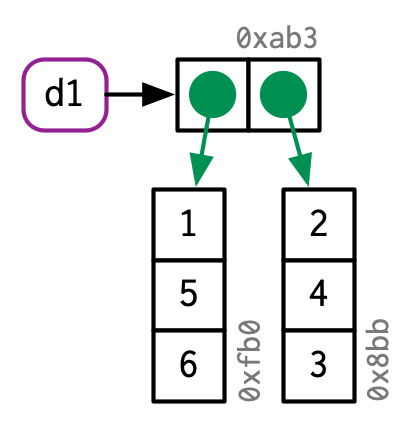
如果你只修改某一列,那么仅仅这一列会被修改,其他的还是指向原始的对象。
d2 <- d1
d2[, 2] <- d2[, 2] * 2
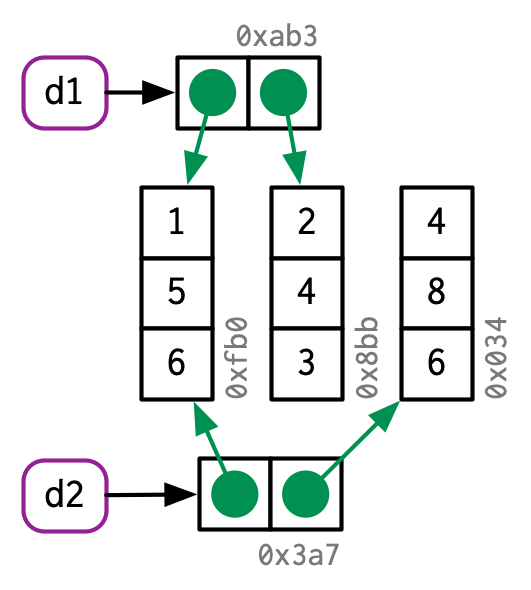
如果你修改某一行,则其实每一列都会被修改,这就意味着每一列都会被复制。
d3 <- d1
d3[1, ] <- d3[1, ] * 3
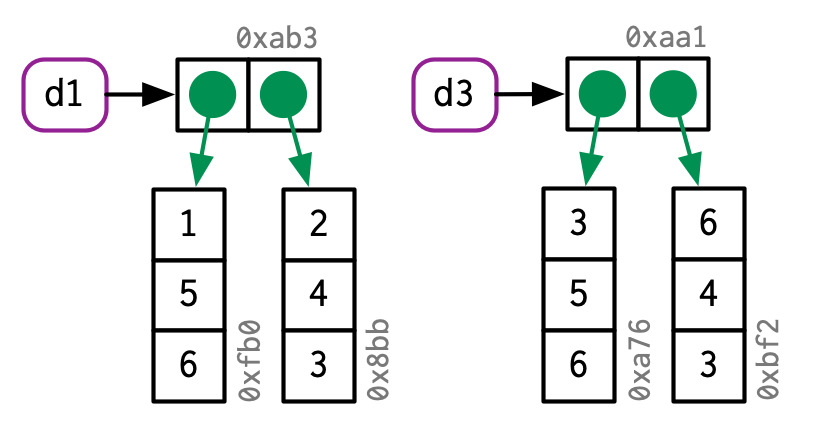
Character vectors
字符串向量和数字向量是不同的。我们常常会用如下图去理解字符串向量。
x <- c("a", "a", "abc", "d")

但实际上对于字符串向量,R常常会使用global string pool,这个pool里面包含所有不重复的(unique)字符串向量元素,每个元素可以被重复指向。这样的好处显而易见,可以减少内存使用。
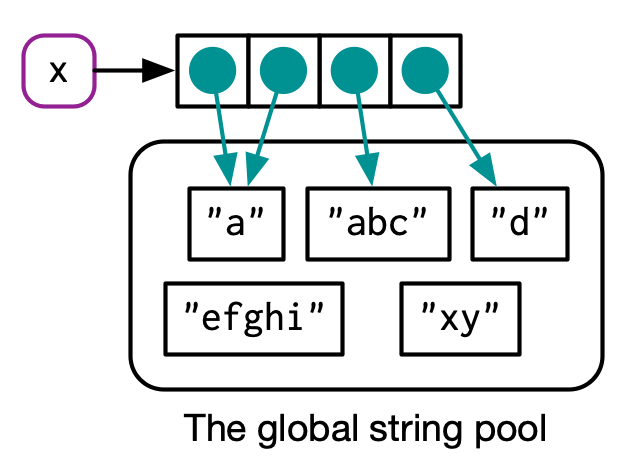
另外可以用ref()函数来查看字符串向量内部的存储结构。
ref(x, character = TRUE) #记得设置character参数
#> █ [1:0x7fe114251578] <chr>
#> ├─[2:0x7fe10ead1648] <string: "a">
#> ├─[2:0x7fe10ead1648]
#> ├─[3:0x7fe11b27d670] <string: "abc">
#> └─[4:0x7fe10eda4170] <string: "d">
对象大小(Object size)
可以通过lobstr::obj_size()函数来查看一个对象的大小。
obj_size(letters)
#> 1,712 B
obj_size(ggplot2::diamonds)
#> 3,456,344 B
因为列表的元素并不是具体值而是指向值的链接。所以下面代码中y变量的大小可能比预计中的要小得多。
x <- runif(1e6)
obj_size(x)
#> 8,000,048 B
y <- list(x, x, x)
obj_size(y)
#> 8,000,128 B
y的大小比x大80bytes,实际上这80bytes就是具有三个元素的空列表的大小。
obj_size(list(NULL, NULL, NULL))
#> 80 B
同样的,因为R使用global string pool存储字符串向量的元素,所以下面代码中即使当字符串的数量增加100倍,但向量的大小并没有增加100倍。
banana <- "bananas bananas bananas"
obj_size(banana)
#> 136 B
obj_size(rep(banana, 100))
#> 928 B
另外一个值得注意特征是:用冒号(:)产生的连续变化的元素组成的字符串向量(如1:3),不管这个向量跨度有多大,所占的大小都是一样的。因为此时只会存储首尾两个元素。
obj_size(1:3)
#> 680 B
obj_size(1:1e3)
#> 680 B
obj_size(1:1e6)
#> 680 B
obj_size(1:1e9)
#> 680 B
Modify-in-place
正如我们在上面所看到的,修改 R 对象时通常会创建一个副本,但有两个例外的情况:
-
当对象只和一个变量名绑定时会进行特殊优化处理,修改对象时不创建副本;
-
环境(Environments)对象
单绑定
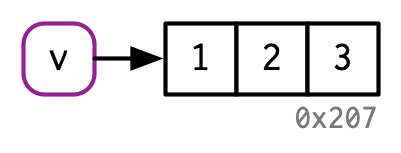
如果一个对象只绑定了一个变量,修改对象不会创建一个副本(注意下面对象修改前后变量指向的地址不变)
v <- c(1, 2, 3)
v[[3]] <- 4
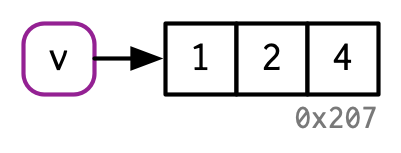
但是作为编写代码的人,在实际应用中其实很难判断一个对象什么时候会应用该优化的机制,主要原因包括两点:
-
与python不同,R语言的引用计数只包括 0 1 many。这意味着如果一个对象有两个绑定,并且一个消失了,那么引用计数不会回到 1。反过来,这意味着 R 有时会在不需要时进行复制。
-
当你调用绝大多数的函数时,它都会对对象进行引用(“primitive” C 编写的函数例外)。
所以,哪怕是经验丰富的R语言爱好者也可能很难准备凭借经验来判断解释器是否会创建副本,这里建议如有需要使用tracemem函数进行追踪调试。
我们来看一个例子,我们实现将一个大数据框的每一列减去其中位数的操作:
x <- data.frame(matrix(runif(5 * 1e4), ncol = 5))
medians <- vapply(x, median, numeric(1))
for (i in seq_along(medians)) {
x[[i]] <- x[[i]] - medians[[i]]
}
这个循环运行速度会非常慢,因为涉及到大量的内存分配、副本创建的操作:
cat(tracemem(x), "\n")
#> <0x7f80c429e020>
for (i in 1:5) {
x[[i]] <- x[[i]] - medians[[i]]
}
#> tracemem[0x7f80c429e020 -> 0x7f80c0c144d8]:
#> tracemem[0x7f80c0c144d8 -> 0x7f80c0c14540]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14540 -> 0x7f80c0c145a8]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c145a8 -> 0x7f80c0c14610]:
#> tracemem[0x7f80c0c14610 -> 0x7f80c0c14678]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14678 -> 0x7f80c0c146e0]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c146e0 -> 0x7f80c0c14748]:
#> tracemem[0x7f80c0c14748 -> 0x7f80c0c147b0]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c147b0 -> 0x7f80c0c14818]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14818 -> 0x7f80c0c14880]:
#> tracemem[0x7f80c0c14880 -> 0x7f80c0c148e8]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c148e8 -> 0x7f80c0c14950]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14950 -> 0x7f80c0c149b8]:
#> tracemem[0x7f80c0c149b8 -> 0x7f80c0c14a20]: [[<-.data.frame [[<-
#> tracemem[0x7f80c0c14a20 -> 0x7f80c0c14a88]: [[<-.data.frame [[<-
untracemem(x)
我们惊恐的发现,循环一次竟然触发了三次开辟内存新建副本的操作!!所以我们需要优化我们的代码,比如我们将data.frame转换成list,性能会得到显著提高:
y <- as.list(x)
cat(tracemem(y), "\n")
#> <0x7f80c5c3de20>
for (i in 1:5) {
y[[i]] <- y[[i]] - medians[[i]]
}
#> tracemem[0x7f80c5c3de20 -> 0x7f80c48de210]:
Environments
环境变量(Environments)是R语言里面一种特殊的数据类型,该种数据类型的修改永远遵守modify in place的原则。我们举例说明:
e1 <- rlang::env(a = 1, b = 2, c = 3)
e2 <- e1
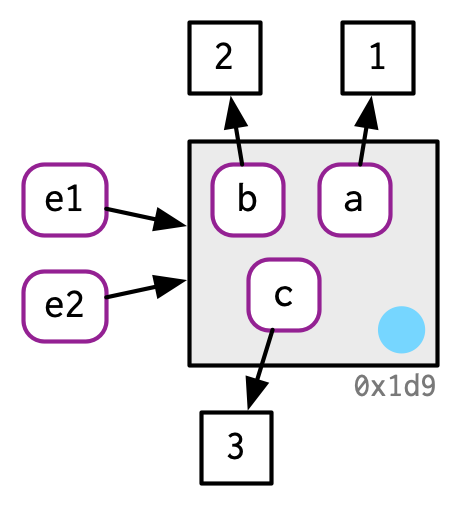
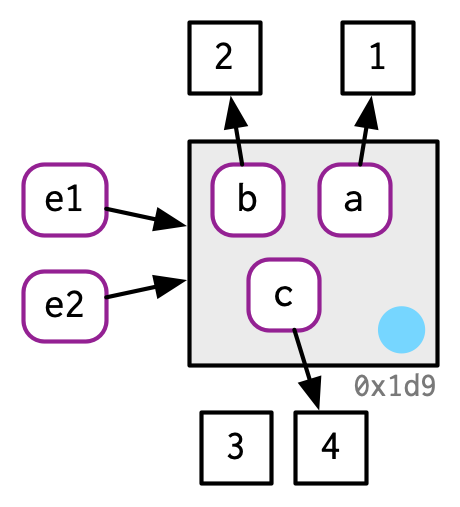
如果我们修改其中的属性,其修改也是modify in place:
e1$c <- 4
e2$c
#> [1] 4
垃圾回收
我们在之前的推文中给大家介绍过《python垃圾回收机制》,趁着这个机会也给大家分享一下R语言的垃圾回收机制。python的垃圾回收机制主要利用引用计数 和分代回收两个算法来实现,而R语言则利用tracing GC的方法。这意味着R语言会跟踪从 global environment 中可访问的每一个对象,以及从这些对象中可访问的所有对象(即递归搜索列表和环境中的引用)。
每当 R 需要更多内存来创建新对象时,垃圾收集器 (GC) 就会自动运行。从用户角度来讲,基本上无法预测 GC 什么时候会运行。如果你想知道 GC 什么时候运行,调用 `gcinfo(TRUE)`,GC 会在每次运行时向控制台打印一条消息。
用户可以通过调用 `gc()`来强制进行垃圾收集。在必要的时候,你可以手动调用 `gc()`快速释放内存给操作系统,以便其他程序可以正常运行,或者统计内存使用情况:
gc()
#> used (Mb) gc trigger (Mb) limit (Mb) max used (Mb)
#> Ncells 884876 47.3 1698228 90.7 NA 1478961 79
#> Vcells 5026893 38.4 17228590 131.5 16384 17226182 132
lobstr::mem_used() # 或则使用该函数
#> 89,748,952 B
需要注意的是,上面所显示的内存使用情况可能和操作系统的内存使用情况不一致,主要有以下三个原因:
-
它包括由 R 创建但不由 R 解释器创建的对象
-
R 和操作系统的统计结果都有一定的延迟
-
内存碎片:R 计算对象占用的内存,但由于删除的对象可能存在空白。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









