







文章目录
写在篇前
这篇博客的雏形,严格来讲,在我脑海中浮现已有近一年之久,起源于我之前在写一个python模块并用jupyter notebook测试时发现,当在一个session中通过import导入模块,修改模块再次通过import导入该模块时,模块修改并不会生效。至此,通过一番研究发现,python 导入机制(import machinery)对于我们理解python这门语言,有着至关重要的作用。因此,本篇博客主要探讨 python import machinery原理及其背后的应用。
import 关键字
关键字import大家肯定都非常熟悉,我们可以通过import导入不同功能的模块 (modules)和包 (packages)。在这里,显然import关键字本身不是我们的重点。因此,我们仅以简略的形式介绍一下python import语句的使用,后面来重点关注import语句背后的导入机制及更深层次的用法。import语句导入主要包括以下形式:
import <module_name>
from <module_name> import <name(s)>
from <module_name> import <name> as <alt_name>
import <module_name> as <alt_name>
import <module_name1>, <module_name2>, <module_name3>, ... # 为了代码规范,不推荐该使用方式
from <module_name> import * # 不推荐
我们举个例子, 假设我们写了一个模块mod.py,在该模块中定义了一个字符串s,一个list a, 一个函数foo和一个类Foo:
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
通过import导入mod.py模块,可以使用dir()函数查看导入前后当前命名空间变量的变化:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__']
>>> import mod
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'mod']
>>> mod.__file__
'/Users/jeffery/mod.py'
>>> mod.__name__
'mod'
>>> mod.s
'If Comrade Napoleon says it, it must be right.'
>>> mod.a
[100, 200, 300]
>>> mod.foo(1)
arg = 1
>>> mod.Foo()
<mod.Foo object at 0x10bf421d0>
>>> s
NameError: name 's' is not defined
我们可以发现,import mod不会使调用者直接访问到mod.py模中块内容,只是将<module_name>放在调用者的**命名空间(namespace)**中;而在模块(mode.py)中定义的对象则保留在模块的命名空间中。因此,从调用者那里,只有通过点表示法 (dot notation) 以<module_name>作为前缀,才能访问模块中的对象。当然,我们可以通过from <module_name> import *的方式,将模块中定义的对象导入到当前调用者的命名空间中(以下划线_开头的对象除外):
>>> from mod import *
>>> dir()
['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'foo', 's']
>>> s
'If Comrade Napoleon says it, it must be right.'
import关键字是导入模块最常见的方式,该语句主要包括两个操作:
-
搜索给定模块,通过函数
__import__(name, globals=None, locals=None, fromlist=(), level=0)实现;该函数默认被
import语句调用,可以通过覆盖builtins.__import__模块来改变导入的语义(不推荐这么做,也不推荐用户使用该函数,建议用户使用importlib.import_module)。name要导入的模块;globals,字典类型,全局变量,用于确定如何解释包上下文中的名称;locals,忽略该参数;fromlist,表示应该从name模块中导入的对象或子模块的名称;level,表征使用绝对导入或相对导入,0表示决定导入,>0表示相对导入,数值指示相对导入的层级;
比如,
import spam,将会调用spam = __import__('spam', globals(), locals(), [], 0);import spam.ham,则调用spam = __import__('spam.ham', globals(), locals(), [], 0);from spam.ham import eggs, sausage as saus,则调用:_temp = __import__('spam.ham', globals(), locals(), ['eggs', 'sausage'], 0) eggs = _temp.eggs saus = _temp.sausage因此,当
name变量的形式为package.module时,通常将会返回最高层级的包(第一个点号之前的名称),而不是以name命名的模块。 但是,当给出了fromlist非空时,则将返回以name命名的模块。 -
将搜索结果绑定到一个局部作用域(
import语句来实现)。即__import__()函数搜索并创建模块,然后其返回值被用来实现import的name binding操作
导入模块时,python首先会检查模块缓存sys.modules是否已经导入该模块,若存在则直接返回;否则Python首先会搜索该模块,如果找到该模块,它将创建一个模块对象(types.ModuleType),对其进行初始化。如果找不到命名的模块,则会引发ModuleNotFoundError。
import语句本身的使用就是这么简单,但是本节中提到的几个概念,如package, module, namespace,还需我们有一个更深入的理解。
先导概念
namespace & scope
Namespaces are one honking great idea—let’s do more of those!
— The Zen of Python, by Tim Peters
如大佬所言,命名空间(namespace, a mapping from names to objects) 是非常极其十分伟大的想法。不同的namespace有不同的生命周期,当Python执行程序时,它会根据需要创建namespace,并在不再需要时删除它们。通常,在任何给定的时间都会存在许多命名空间,在python中主要包括三大类的namespace:
- Built-in,可通过
dir(__builtins__)查看; - Global,全局命名空间是指包含在主程序层定义的任何对象。Python在主程序启动时创建全局命名空间,并一直存在,直到解释器终止。严格地说,这可能不是唯一存在的全局命名空间。python解释器还为程序用import语句加载的任何模块创建全局命名空间;
- Local,函数中定义的局部变量,函数参数等;
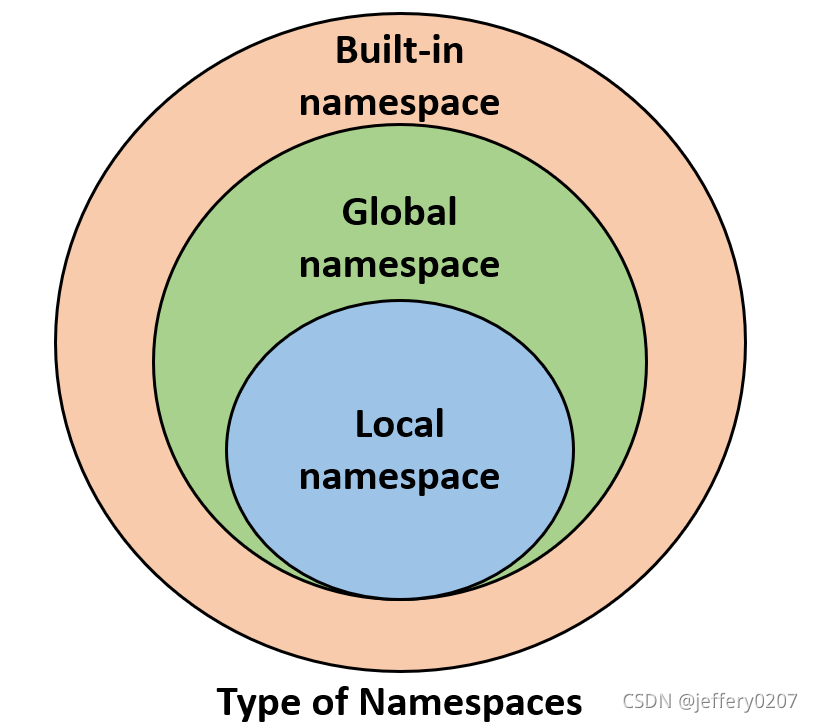
我们可以分别通过dir(__builtins__) or __builtins__.__dict__, globals()以及locals() 查看内置、当前全局及局部命名空间中的对象:
>>> def func(x):
... a = 2
... print(locals())
...
>>> func(5)
{'x': 5, 'a': 2}
>>>
>>> globals()
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'func': <function func at 0x2b256f36ae50>}
>>> dir(__builtins__)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'ZeroDivisionError', '_', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
接着,我们会想,当在一个程序的不同命名空间中存在相同的对象名时,程序又如何知道你想要调用一个呢?这时则需要引入一个新的概念:作用域(scope),官方定义: a textual region of a Python program where a namespace is directly accessible,即指一个 Python 程序中可以直接访问(Directly accessible)命名空间的文字区域。Directly accessible是指尝试在命名空间中去寻找一个unqualified reference的对象名所对应的对象。python作用域搜索遵循LEGB rule ,即假如在程序中引用x,解释器将依次在以下作用域搜索该对象:

- Local: 如果在函数中引用
x,那么解释器首先在该函数的最内部作用域中搜索它; - Enclosing: 如果
x不在local作用域中,但出现在另一个函数内部的函数中,则解释器将在enclosing function(请参考博客)的作用域中进行搜索; - Global: 如果以上两个搜索都没有结果,那么解释器接下来就会在全局作用域中查找;
- Built-in: 如果依然没找到,最后解释器会尝试在内置作用域查找;
如果上述四个作用域中都没找到x,则会报错。举例如下:
a = 1
def func():
a = 3
def inner_func():
a = 5
print(a)
inner_func()
print(a)
if __name__ == '__main__':
func()
print(a)
### output
# 5
# 3
# 1
我们再看一个有趣的例子:
_list: list = [1, 2, 3]
_int: int = 4
def func(seq: list, integer: int):
seq[0] = -1
integer += 1
if __name__ == '__main__':
func(_list, _int)
print(_list, _int)
在该例子中,将全局定义的_list, _int传入函数func, 调用执行之后发现,_lis改变了而_int却没有发生改变,这是为什么呢?学过C语言的同学应该马上会想到这会不会是传值和传址的区别。很遗憾,严格来讲都不是。因为在python中一切皆为对象,也就是说一个引用指向一个对象,而不是指向一个特定的内存地址。在python中这和可变对象 mutable和不可变对象 immutable有关:
- 当函数参数传入不可变对象时,类似于C语言传值(pass-by-value),在函数中的修改不会影响全局空间的对象引用;
- 当函数参数传入可变对象时,有一点类似于C语言传址(pass-by-reference),在函数中的修改不会影响全局空间的对象引用,但可以修改全局空间对象中的项(item);
那么如果我想要改变全局空间中的引用呢?这时则可以通过global和nonlocal来"修改"对象的作用域:
a = 3
def func():
global a
a += a
b = 5
def inner_func():
nonlocal b
b += b
inner_func()
print(f'b={b}')
if __name__ == '__main__':
func()
print(f'a={a}')
### output
b=10
a=6
所以,global声明允许函数在全局作用域中访问和修改对象;nonlocal声明允许在enclosed function中修改enclosing function中的对象。
Module & Packages
模块化编程(modular programming),是强调将计算机程序的功能分离成独立的、可相互改变的“模块”(module)的软件设计技术,它使得每个模块都包含着执行预期功能的一个唯一方面(aspect)所必需的所有东西。python使用 函数(Functions),模块(modules)和包(packages)等概念来实现模块化编程,使得代码更具有可维护性和可重用性。在理解python import machinery之前,读者有必要先了解module和packages两个概念。
module
我们常见的*.py文件,以及*.pyc、*.pyo、*.pyd、*.pyw等单个文件都是module。 在Python中常有三种不同的方式定义module:
- 模块可以用Python本身编写,如
test.py; - 模块可以用C语言编写,并在运行时动态加载,如python标准库
re(推荐阅读,python re 正则表达式); - 内置模块则内置在解释器中,如
itertools(推荐阅读,python函数式编程之functools、itertools、operator详解);
In [17]: import re, itertools
In [18]: itertools
Out[18]: <module 'itertools' (built-in)>
In [19]: re
Out[19]: <module 're' from '/Users/jeffery/workspace/envs/common/lib/python3.7/re.py'>
在这三种情况下,访问模块中的内容都是通过import语句实现,比如我们编写一个模块mod.py:
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
假设mod.py在一个合适的位置,这些对象可以通过如下方式导入:
>>> import mod
>>> print(mod.s)
If Comrade Napoleon says it, it must be right.
>>> mod.a
[100, 200, 300]
>>> mod.foo(['quux', 'corge', 'grault'])
arg = ['quux', 'corge', 'grault']
>>> x = mod.Foo()
>>> x
<mod.Foo object at 0x03C181F0>
>>> dir(mod)
['Foo', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'foo', 's']
所以,所谓合适的位置是指什么呢?这就涉及到python模块导入的路径搜索问题,python模块导入时,将依次搜索以下路径:
- 运行输入脚本的目录或当前目录;
- 环境变量
PYTHONPATH中所包含的目录列表; - 安装Python时配置的与安装相关的目录列表;
这些目录以列表的形式存储在sys.path中,如:
>>> import sys
>>> sys.path
['', '/Users/jeffery/workspace/envs/common/lib/python37.zip', '/Users/jeffery/workspace/envs/common/lib/python3.7', '/Users/jeffery/workspace/envs/common/lib/python3.7/lib-dynload', '/Users/jeffery/workspace/envs/common/lib/python3.7/site-packages']
packages
A python module which can contain submodules or recursively, subpackages. Technically, a package is a python module with an
__path__attribute. From python glossary
先举例解释一下上面这句话吧,下面实例中我们可以发现,python标准库re不是一个package,但是是一个module;而numpy则是一个package(它包含很多modules;另外,在实际使用中作为用户并不需要关注导入的library是module还是package)。可以将package视为文件系统上的一个目录,将module视为目录中的文件,但也不要过于字面地理解这个类比,因为包和模块不一定需要源自文件系统。
>>> import re
>>> re.__path__
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 're' has no attribute '__path__'
>>> import numpy
>>> numpy.__path__
['/Users/jeffery/workspace/envs/DLBCL/lib/python3.7/site-packages/numpy']
从概念上来讲,package又包括regular package和namespace package PEP420:
regular package
Regular package,即常规包,一般是指每一个文件夹或子文件夹下都包含__init__.py(模块初始化文件,可以为空)。默认情况下,submodules 和 subpackages不会被导入,而通过__init__.py可以将任意或全部子模块按照你的想法进行导入。比如在我写的一个示例packagepython_dotplot中,可以通过__init__.py的__all__默认暴露且只暴露出部分你想暴露的接口。
namespace package
Namespace package,即命名空间包,该概念是在python 3.3中新增加的特性,是一种将单个Python包拆分到磁盘上多个目录的机制(当然不局限于磁盘空间)。命名空间包隐式建立,即如果你有一个包含.py文件但没有__init__.py文件的目录,那么该文件夹则是一个命名空间包。
importlib
绕了这么远的路,终于来到今天的正题。通常,要在一个模块中使用另一个模块中的代码我们可以通过import来实现,但这不是唯一的方法,用户可以使用其他的导入机制,如importlib.import_module(),绕过__import__()并使用自己的解决方案实现模块导入。那么,python是通过怎样的机制来实现模块的导入呢?
当导入一个特定模块时,首先搜索模块缓存sys.modules中是否存在需要导入的模块,如果存在则直接返回;如果为None,则抛出ModuleNotFoundError;如果不存在,python将依次利用finders和loaders查找并加载该模块。
Loaders & Finders
详细来讲,当要导入一个sys.modules中不存在的模块时,将依次使用sys.meta_path中的finders对象去查询他们是否知道如何导入用户所需模块。如果finder可以处理,则返回一个spec对象(spec对象中则包含一个loader对象及模块导入相关的信息),反之返回None。如果sys.meta_path中的finder循环完都是返回None, 则会抛出错误ModuleNotFoundError。
>>> sys.modules
{'sys': <module 'sys' (built-in)>, 'builtins': <module 'builtins' (built-in)>, '_frozen_importlib': <module 'importlib._bootstrap' (frozen)>, '_imp': <module '_imp' (built-in)>, '_thread': <module '_thread' (built-in)>, '_warnings': <module '_warnings' (built-in)>, '_weakref': <module '_weakref' (built-in)>, 'zipimport': <module 'zipimport' (built-in)>, '_frozen_importlib_external': <module 'importlib._bootstrap_external' (frozen)>, '_io': <module 'io' (built-in)>, 'marshal': <module 'marshal' (built-in)>, 'posix': <module 'posix' (built-in)>}
-
Finder: 它的工作是确定它是否可以使用它所知道的任何策略找到命名模块,内置实现的finder和importers包括以下三个:
>>> sys.meta_path [<class '_frozen_importlib.BuiltinImporter'>, # 定位内置模块 <class '_frozen_importlib.FrozenImporter'>, # 定位frozen模块 <class '_frozen_importlib_external.PathFinder'> # 定位指定path(sys.path)中的模块,又被称为 Path Based Finder ]python 3.4 更新: 在python 3.4之前, finders 直接返回 loaders;而python 3.4及以后finders返回module specs,module spec则包含了 loaders。 Loaders在导入过程中依然用到,但承担更少的职能了。
-
Loader:loaders提供模块加载过程中最重要的一个功能:module execution,导入机制调用
exec_module(module)执行模块代码,该函数的一切返回值都忽略。Loader必须实现以下两个条件:- 如果load一个python模块,loader必须在module的全局命名空间执行模块代码(
module.__dict__); - 如果Loader不能执行该模块,则应抛出
ImportError;
Loaders可以选择在加载期间通过实现
create_module(module_spec)方法来创建module对象,在模块创建之后,但在执行之前,导入机制会初始化设置与导入相关的模块信息(基于ModuleSpec对象的信息),主要包括以下属性:__name__ # fully-qualified name of the module __loader__ # load模块时所对应的loader对象 __package__ # 和__spec__.parent的值一样 __spec__ # 导入模块时所对应的module spec对象 __path__ # package的一个必要属性,数据类型为iterable[strings],该属性在导入子模块时会用到 __file__ # package 所在路径 __cached__ # 代码编译版本的路径Importers: 同时实现了finders和loaders的对象
- 如果load一个python模块,loader必须在module的全局命名空间执行模块代码(
import hooks
python的导入机制是可扩展的,主要通过Import hooks(meta hooks and import path hooks)的机制来实现:
-
meta hooks: 在import开始时meta hook会被调用,具体是在
sys.modules缓存查找之后,任何其他导入操作发生之前。 这允许meta hook覆盖sys.path、frozen模块,甚至built-in模块。meta hook是通过向sys.meta_path添加新的 finder 对象来注册的;>>> sys.meta_path [<class '_frozen_importlib.BuiltinImporter'>, # 定位内置模块 <class '_frozen_importlib.FrozenImporter'>, # 定位frozen模块 <class '_frozen_importlib_external.PathFinder'> # 定位指定path(sys.path)中的模块 ] 上述的meta path finders/importers都实现了
find_spec(fullname, path, target=None)函数,第一个参数是导入模块的fully qualified name;当导入顶层模块(top-level module)时第二个参数为None,反之为模块上一级的__path__属性(参考例子),第三个参数为一个已经存在的作为导入模块目标的module object (当且仅当调用importlib.reload()时使用该参数)。其中,第三个finder又被称为Path Based Finder,它通过搜索sys.path中指定的路径(path entry)来搜索模块。 与前两个不同的是,
Path Based Finder本身并没有实现导入模块的操作;相反,它遍历搜索路径(sys.path)中的各个path entry,并关联知道如何处理该path entry的path entry finders。Path Based Finder主要利用sys.path,sys.path_hooks,sys.path_importer_cache以及package.__path__几个变量。>>> sys.path ['/Applications/PyCharm.app/Contents/helpers/pydev', '/Applications/PyCharm.app/Contents/helpers/pycharm_display', '/Applications/PyCharm.app/Contents/helpers/third_party/thriftpy', '/Applications/PyCharm.app/Contents/helpers/pydev', '/Users/jeffery/workspace/envs/test/lib/python37.zip', '/Users/jeffery/workspace/envs/test/lib/python3.7', '/Users/jeffery/workspace/envs/test/lib/python3.7/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7', '/Users/jeffery/workspace/envs/test/lib/python3.7/site-packages', '/Applications/PyCharm.app/Contents/helpers/pycharm_matplotlib_backend', '/Users/jeffery/PycharmProjects/python-dotplot'] 所以,
Path Based Finder通过调用find_spec(path_entry_related_path)函数寻找指定模块并关联相对应的path entry finders。为了方便,Path Based Finder维护了一个缓存字典,表征每个path entry应该由哪个path entry finder处理,如下所示:>>> sys.path_importer_cache # path entry finders {'/Applications/PyCharm.app/Contents/helpers/pycharm_matplotlib_backend': FileFinder('/Applications/PyCharm.app/Contents/helpers/pycharm_matplotlib_backend')} -
import path hooks: import path hooks作为
sys.path(或package.__path__)处理的一部分,其通过向sys.path_hooks添加新的可调用对象来注册的
如果缓存字典中不存在该path entry,Path Based Finder将path entry作为参数循环调用sys.path_hooks中的每一个callable对象,返回一个可以处理该path entry的path entry finder或者抛出错误ImportError。如果循环结束都没有找到合适的path entry finder,find_spec函数将会将缓存mapping中path entry的值设置为None并返回None,代表该meta path finder不能找到该module。如果sys.path_hooks中的某个hook返回了一个path entry finder,则该path entry finder用于后续module spec对象的构建及模块加载。path entry finder必须实现find spec方法,返回module spec对象,该方法包含两个参数:模块的fully qualified name以及target module (optional)。
>>> sys.path_hooks
>>> [zipimport.zipimporter,
<function _frozen_importlib_external.FileFinder.path_hook.<locals>.path_hook_for_FileFinder(path)>]
importlib.abc
importlib.abc模块包含import关键字用到的所有核心抽象基类,主要包含以下这些类:
object
±- Finder (deprecated since 3.3)
| ±- MetaPathFinder
| ±- PathEntryFinder
±- Loader
±- ResourceLoader(deprecated since 3.7) --------+
±- InspectLoader |
±- ExecutionLoader --+
±- FileLoader
±- SourceLoader
其中,imporlib.machinery模块利用importlib.abc模块实现了很多用于寻找、加载模块的功能。
-
BuiltinImporterBuiltinImporter是一个针对built-in模块的importer, 即sys.builtin_module_names中所包含的所有模块。该类实现了importlib.abc.MetaPathFinder和importlib.abc.InspectLoader的抽象。 -
FrozenImporterFrozenImporter是一个针对frozen模块的importer。该类也实现了importlib.abc.MetaPathFinder和importlib.abc.InspectLoader相关的功能。 -
PathFinderPathFinder是一个针对sys.path和package __path__属性的Finder,该类实现了importlib.abc.MetaPathFinder的抽象。 -
FileFinderimportlib.abc.PathEntryFinder的具体实现,用来缓存来自文件系统的结果。
importlib.resources
If you can import a package, you can access resources within that package.
importlib.resources 模块是在 python 3.7新增的功能模块,其允许像导入模块一样导入包内的资源(resources)。 资源可以是位于可导入包中的任何文件,该文件可能是文件系统上的物理文件也可能是网络资源。但importlib.resources 只支持regular package,不支持namespace package。
该模块首先定义了以下两种数据类型,作为主要的两种参数实现该模块功能:
Package = Union[str, ModuleType] # 包,如果Package是ModuleType, 那么其该属性__spec__.submodule_search_locations不可为None
Resource = Union[str, os.PathLike] # 资源名称
我们简单的构建如下层级结构的regular package作为示例,来看该模块主要的函数:
test_package
├── __init__.py
├── data
│ ├── __init__.py
│ └── data.txt
└── data0.txt
其中,test_package/_init_.py文件包含以下代码:
from .data import *
print('____root init____')
test_package/data/_init_.py文件中包含以下代码:
print('____data dir init____')
data0.txt文件包含一行数据:
this is data0.
data.txt文件包含两行数据:
col1 col2
data1 data2
-
is_resource(package, name),contents(package)for item in contents(test_package): if is_resource(test_package, item) and item.endswith('.txt'): print(item) # Output: # data0.txtcontents()函数返回一个可迭代对象,该可迭代对象包含package中的所有资源(如,文件)和非资源(如,文件夹),通过is_resource可以进一步判断类型,如果是资源则返回True,反之返回False。 -
open_binary(package, resource),open_text(package, resource, encoding='utf-8', errors='strict')for item in contents(test_package): if is_resource(test_package, item) and item.endswith('.txt'): with open_text(test_package, item) as f: line = f.readline() print(line) # Output: # This is data0.进一步地,我们可以使用上述两个函数打开数据文件从而读取数据,前者返回
typing.BinaryIO, 后者返回typing.TextIO,分别代表读状态下的字节/文本 I/O stream。 -
read_binary(package, resource),read_text(package, resource, encoding='utf-8', errors='strict')也可以使用更直接的方式,打开并读取数据文件。这里值得注意的是,我们读取的目标是子模块data中的数据文件,可以通过传入参数
package.submodule来实现,也就是说contents()函数不会去遍历子文件夹的内容。for item in contents(test_package.data): if is_resource(test_package.data, item) and item.endswith('.txt'): print(read_binary(test_package.data, item)) # Output: # b'col1 col2\ndata1 data2' -
path(package, resource)该函数可以返回一个ContextManager对象,指示资源的路径with path(test_package, 'data0.txt') as file: # ContextManager print(file, type(file)) # Output: # /path/to/test_package/data0.txt <class 'pathlib.PosixPath'> -
files(package),as_file(Traversable)这两个方法是在python 3.9中新增的,前者返回一个
importlib.resources.abc.Traversable,后者参数一般为前者返回值test_traversable = files(test_package) print(test_traversable, isinstance(test_traversable, resources_abc.Traversable)) with as_file(test_traversable) as traversable_files: print(traversable_files, type(traversable_files)) # Output /path/to/test_package True /path/to/test_package <class 'pathlib.PosixPath'>
##Importlib 常用API
importlib.import_module(name, package=None)
name参数指定导入模块名字,以绝对(absolute)或则相对(relative)的方式导入模块;当name是relative形式(如..mod),则需要指定package参数作为一个anchor来解析包的名字或路径(如pkg.subpkg)。所以importlib.import_module('..mod', 'pkg.subpkg')将会导入模块pkg.mod。实际上,该函数是基于importlib.__import__(name, globals=None, locals=None, fromlist=(), level=0)来实现的,区别是,前者返回用户指定的包或模块(如pkg.mod),后者返回的是top-level 的包或模块。为了更深入了解python导入包的过程我们可以结合源码来分析一下整个过程。
-
import_module(name, package)根据参数形式确定是相对导入还是绝对导入,并调用importlib包中的_gcd_import(name, package, level)函数def import_module(name, package=None): """Import a module. 当相对导入的时候,才需要用到package参数,作为导入模式时的anchor point. """ level = 0 if name.startswith('.'): if not package: msg = ("the 'package' argument is required to perform a relative " "import for {!r}") raise TypeError(msg.format(name)) for character in name: # 当 name='..data', level=2; 当name='...data', level=3 if character != '.': break level += 1 return _bootstrap._gcd_import(name[level:], package, level) -
_gcd_import(name, package, level)函数进一步调用importlib中的_find_and_load(name, import_)函数。值得注意的是,gcd,即greatest common denominator,也即最大公约数。为什么起这么个名字呢?因为该函数代表了builtin__import__函数和importlib.import_module函数功能的主要相似之处。This function represents the greatest common denominator of functionality between import_module and
__import__. This includes setting__package__if the loader did not.def _gcd_import(name, package=None, level=0): """返回name,package所指定的module """ _sanity_check(name, package, level) if level > 0: name = _resolve_name(name, package, level) # _resolve_name将得到要导入模块的全路径,如numpy, numpy.random等 return _find_and_load(name, _gcd_import) -
从返回值可见,
_find_and_load(name, import_)函数实现了搜索和加载的功能,最后返回指定的模块。在搜索开始前,先查询模块缓存sys.modules中是否已经存在要导入的指定模块;然后搜索和加载的功能实际上由_find_and_load_unlocked(name, import_)承担。def _find_and_load(name, import_): """Find and load the module.""" with _ModuleLockManager(name): module = sys.modules.get(name, _NEEDS_LOADING) if module is _NEEDS_LOADING: return _find_and_load_unlocked(name, import_) if module is None: message = ('import of {} halted; ' 'None in sys.modules'.format(name)) raise ModuleNotFoundError(message, name=name) _lock_unlock_module(name) # 用于确保模块被完全初始化,以防它被另一个线程导入。 return module -
从源码我们可以非常清晰的看出,主要是利用
_find_spec(name, path, target=None)获得模块/包的ModuleSpec对象;然后再利用_load_unlocked(spec)函数根据ModuleSpec对象信息获得module对象。可以预见,以下再分别分析这两个过程就可以知道全部过程啦。def _find_and_load_unlocked(name, import_): path = None parent = name.rpartition('.')[0] if parent: if parent not in sys.modules: _call_with_frames_removed(import_, parent) # 如果存在父级,则先导入父级; # Crazy side-effects! if name in sys.modules: return sys.modules[name] parent_module = sys.modules[parent] try: path = parent_module.__path__ except AttributeError: msg = (_ERR_MSG + '; {!r} is not a package').format(name, parent) raise ModuleNotFoundError(msg, name=name) from None spec = _find_spec(name, path) if spec is None: raise ModuleNotFoundError(_ERR_MSG.format(name), name=name) else: module = _load_unlocked(spec) if parent: # Set the module as an attribute on its parent. parent_module = sys.modules[parent] child = name.rpartition('.')[2] try: setattr(parent_module, child, module) except AttributeError: msg = f"Cannot set an attribute on {parent!r} for child module {child!r}" _warnings.warn(msg, ImportWarning) return module -
为了获得模块/包的ModuleSpec对象,
_find_spec(name, path, target=None)函数循环调用sys.meta_path中的importers/Finders尝试能不能处理该指定的模块,如果可以则返回ModuleSpec对象,反之返回None。def _find_spec(name, path, target=None): """Find a module's spec.""" meta_path = sys.meta_path if meta_path is None: # PyImport_Cleanup() is running or has been called. raise ImportError("sys.meta_path is None, Python is likely " "shutting down") if not meta_path: _warnings.warn('sys.meta_path is empty', ImportWarning) # We check sys.modules here for the reload case. While a passed-in # target will usually indicate a reload there is no guarantee, whereas # sys.modules provides one. is_reload = name in sys.modules for finder in meta_path: with _ImportLockContext(): try: find_spec = finder.find_spec except AttributeError: spec = _find_spec_legacy(finder, name, path) if spec is None: continue else: spec = find_spec(name, path, target) if spec is not None: # The parent import may have already imported this module. if not is_reload and name in sys.modules: module = sys.modules[name] try: __spec__ = module.__spec__ except AttributeError: # We use the found spec since that is the one that # we would have used if the parent module hadn't # beaten us to the punch. return spec else: if __spec__ is None: return spec else: return __spec__ else: return spec else: return None -
获得了模块/包的ModuleSpec对象之后,再调用
_load_unlocked(spec)函数加载并执行模块。def _load_unlocked(spec): # A helper for direct use by the import system. if spec.loader is not None: # Not a namespace package. if not hasattr(spec.loader, 'exec_module'): return _load_backward_compatible(spec) module = module_from_spec(spec) # 利用importlib.module_from_spec获得模块 spec._initializing = True try: sys.modules[spec.name] = module # 执行模块前,应该先将模块放入模块缓存中 try: if spec.loader is None: if spec.submodule_search_locations is None: raise ImportError('missing loader', name=spec.name) # A namespace package so do nothing. else: spec.loader.exec_module(module) # 执行模块代码 except: try: del sys.modules[spec.name] except KeyError: pass raise module = sys.modules.pop(spec.name) sys.modules[spec.name] = module _verbose_message('import {!r} # {!r}', spec.name, spec.loader) finally: spec._initializing = False return module
因此,我们可以总结该函数的近似实现如下:
import importlib.util
import sys
def import_module(name, package=None):
"""An approximate implementation of import."""
absolute_name = importlib.util.resolve_name(name, package)
try:
return sys.modules[absolute_name]
except KeyError:
pass
path = None
if '.' in absolute_name: # 例如为numpy.random时,先import numpy,再回来import子模块random
parent_name, _, child_name = absolute_name.rpartition('.')
parent_module = import_module(parent_name)
path = parent_module.__spec__.submodule_search_locations
for finder in sys.meta_path:
spec = finder.find_spec(absolute_name, path) # 根据submodule_search_locations搜索子模块
if spec is not None:
break
else:
msg = f'No module named {absolute_name!r}'
raise ModuleNotFoundError(msg, name=absolute_name)
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module) # 这一步很重要
sys.modules[absolute_name] = module # optional,推荐加上
if path is not None:
setattr(parent_module, child_name, module)
return module
-
importlib.invalidate_caches()该函数使
sys.meta_path中缓存的Finders失效,适用于动态导入程序执行之后才创建/安装的包的场景。 -
importlib.reload(module)重新导入一个已导入的模块(
module),以上面的test_package为例,并修改test_package/_init_.py 如下:from .data import * print('____root init____') num = 10进入python console 执行下列代码:
>>> import test_package ____data dir init____ ____root init____ >>> test_package.num 10此时,不要关闭console,并直接修改源码,将
num=10这一行改为num=11,此时重新导入test_package,我们会发现num的值并不会改变:>>> import test_package >>> test_package.num 10这种情况下则需要用到
reload函数来使源码的修改得到应用:>>> import importlib >>> importlib.reload(test_package) >>> test_package = importlib.reload(test_package) ____root init____ >>> test_package.num 11 -
importlib.util.find_spec()通过
importlib.util.find_spec()测试一个模块是否可以被导入,如果可以被导入则使用importlib.util.module_from_spec获得模块对象并执行module code, 执行load操作导入模块。import importlib.util import sys name = 'itertools' module = None spec = importlib.util.find_spec(name) if spec is None: print("can't find the itertools module") else: # 实际导入操作 module = importlib.util.module_from_spec(spec) spec.loader.exec_module(module) sys.modules[name] = module # optional print(list(module.accumulate([1, 2, 3])))该函数是python3.4的新增函数,用来替代python3.3版本中的
importlib.find_loader(name, path=None) -
importlib.util.spec_from_file_location也可以通过
importlib.util.spec_from_file_location导入python源文件import importlib.util import sys # For illustrative purposes. import tokenize file_path = tokenize.__file__ module_name = tokenize.__name__ spec = importlib.util.spec_from_file_location(module_name, file_path) module = importlib.util.module_from_spec(spec) spec.loader.exec_module(module) # Optional; only necessary if you want to be able to import the module # by name later. sys.modules[module_name] = module -
importlib.util.spec_from_loader基于
Loader创建ModuleSpec对象 -
importlib.util.module_from_spec通过
importlib.util.find_spec()测试一个模块是否可以被导入,如果可以被导入则使用importlib.util.module_from_spec获得模块对象并执行module code, 执行load操作导入模块。 -
importlib.machinery.ModuleSpec(name, loader, *, origin=None, loader_state=None, is_package=None)ModuleSpec是一个模块的import-system-related 状态,对于一个模块,可以通过module.__spec__来获取相关的信息。该类主要包括以下重要的属性(注意,以下属性说明中,圆括弧内的属性名可以直接通过模块来访问,module.__spec__.origin == module.__file__):-
name (__name__)模块的名字(fully-qualified name)In [1]: import numpy.random In [2]: from numpy import random In [3]: numpy.random.__name__ Out[3]: 'numpy.random' In [4]: random.__name__ Out[4]: 'numpy.random' -
loader (__loader__)import该模块时所使用的LoaderIn [5]: random.__loader__ Out[5]: <_frozen_importlib_external.SourceFileLoader at 0x2abdf0f8bf10> -
origin (__file__)模块在文件系统上的位置In [6]: random.__file__ Out[6]: '/path/to/python/site-packages/numpy/random/__init__.py' -
submodule_search_locations (__path__)package的子模块搜寻路径,如果不是package返回NoneIn [7]: random.__path__ Out[7]: ['/path/to/python/site-packages/numpy/random'] -
loader_state加载期间使用的额外模块特定数据的容器或则None -
cached (__cached__)compiled module的位置In [8]: random.__cached__ Out[8]: '/path/to/python/site-packages/numpy/random/__pycache__/__init__.cpython-38.pyc' -
parent (__package__)fully-qualified nameIn [9]: random.__package__ Out[9]: 'numpy.random' -
has_locationbool值,指示模块的“origin”属性是否指代一个可加载位置In [10]: random.__spec__.has_location Out[10]: True
-
##importlib应用
写到这里,python 的导入机制其实就基本写完了。总结来讲,python导入一个包主要涉及以下三个步骤:
-
确认要导入的模块/包是否已经存在模块缓存中
sys.modules,如果存在,则返回,进行命名绑定即可; -
依次循环查询
sys.meta_path中的importers/finders,看是否能处理要导入的模块/包(不能处理返回None;能处理则返回一个ModuleSpec对象);这一步可能会比较复杂,当要导入的包既不是built-in也不是frozen包时,则需要利用
PathFinder查找搜索路径sys.path找到相应的包。由于PathFinder本身没有实现模块导入功能,找到包之后需要结合sys.path_importer_cache或sys.path_hooks关联能导入该包的path entry finder -
利用上一步返回的
ModuleSpec对象(ModuleSpec包含Loader对象)导入包;
基于此,我们就可以很好利用Finder和Loader的概念来自定义模块/包的导入行为啦。我们可以利用修改import hooks(sys.meta_path, sys.path_hooks)的方法,改变import默认的加载方式。比如,我们可以实现一个包的导入机制,如果该包不存在则利用pypi安装再导入(更多自定义导入例子,请参考导入数据文件):
from importlib import util
import subprocess
import sys
class PipFinder:
@classmethod
def find_spec(cls, fullname, path, target=None):
print(f"Module {fullname!r} not installed. Attempting to pip install")
cmd = f"{sys.executable} -m pip install {fullname}"
try:
subprocess.run(cmd.split(), check=True)
except subprocess.CalledProcessError:
return None
return util.find_spec(fullname)
sys.meta_path.append(PipFinder)
这时,导入未安装的模块时,将会自动安装相应模块:
In [1]: import parse
Module 'parse' not installed. Attempting to pip install
Collecting parse
Downloading parse-1.19.0.tar.gz (30 kB)
Building wheels for collected packages: parse
Building wheel for parse (setup.py) ... done
Created wheel for parse: filename=parse-1.19.0-py3-none-any.whl size=24581 sha256=90690a858905aa38e2935201a725276fa85e928cb5f6b16236b6a1494985850e
Stored in directory: ~/.cache/pip/wheels/d6/9c/58/ee3ba36897e890f3ad81e9b730791a153fce20caa4a8a474df
Successfully built parse
Installing collected packages: parse
Successfully installed parse-1.19.0
参考资料
Stackoverflow How to use the __import__function to import a name from a submodule?















 552
552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









