







本文为学习B站上的Flink入门视频课程的总结,有些重点知识或许在面试中会被问到,故于此分享学习。
1.Flink和Storm,Hadoop,Spark的对比?
Hadoop是纯粹的批处理框架,storm是纯粹的流处理框架,spark通过基于两种不同的技术实现了批处理和流处理,但是Flink同时支持实现了批处理和流处理,将批处理作为一种特殊的流处理。
Storm:延迟低,能做到毫秒级,牺牲了精确性,没法做到高吞吐,需要搭建独立的Storm集群。
Hadoop: 纯粹的批处理框架,吞吐量大。
Spark streaming: 将连续时间中的流数据分割成一系列微小的批量作业,做到精确一致性的语义,提高吞吐量。本质上是一种微批次的处理技术。
Flink:高吞吐,在压力下保持正确,低延迟,语义化窗口。
2.Flink如何实现将批处理数据变为流数据处理的?
它通过将批处理数据一批一批的采集过来,在底层就相当于实现了流数据的特点,然后就可以统一进行流处理了。
3.Flink在部署时有哪两种常见模式?
常见的模式有YARN模式和standalone模式。
4.解释Flink的slot概念?
slot在是将JVM进行等分,用来划分分区,在每个slot中执行一个task,slot的个数决定一个taskmanager的最大并行度。
5.如何理解精确一致性(exactly-once)?
就是在保证数据不丢失的情况下,还能保证数据的不重复。
6.解释流处理和批处理?
批处理的特点是有界,持久,大量,需要访问全套记录才能完成的计算工作,一般用于离线统计,要求支持高吞吐,高效处理。流处理的特点是无界,实时,流处理无需对整个数据集执行操作,而是对通过系统传输的每个数据执行操作,一般用于实时统计,要求支持低延迟,精确一致性保证。
7.Spark同时支持批处理和流处理跟Flink有什么不一样?
Spark是通过Spark Streaming和Spark Pool+SQL两套技术体系实现了
8.简述一下Flink的计算架构?
可以大致分为四层,最底层是single JVM,或者Cluster或者云作为部署环境,网上就是核心层,叫做运行时,再往上就是datastream API和Dataset API分别用来进行流处理和批处理,在这之上还有些应用层的库, 比如事件处理,机器学习处理等。
9.Flink的基本架构?
包含两种类型的处理器,JobManager与TaskManager。本质上是两个JVM的进程,JobManager相当于Master,负责资源申请和任务分发,TaskManager相当于Executor,主要负责任务的执行。Taskmanager需要通过注册的方式在Jobmanager中进行注册。
10.有界数据流和无界数据流?
有界数据流就是有头有尾的数据流,无界数据流就是有头无尾的数据流,对于无界数据流的处理,一般也会通过窗口机制来进行处理。
11.Flink数据处理的抽象级别?
一共可以分为四层,最底层的是有状态的流处理,往上可以是Datastream/Dataset API进行查询,在往上就是Table API和SQL。对于Table API可以通过select语句等对表格进行操作。
12.Flink的运行架构?

图片来源:尚硅谷大数据技术之Flink
1)上传Flink的jar包和配置到HDFS上。
2)向ResourceManager提交Job。
3)ResourceManager可以启动ApplicationMaster,JobManager被包含在ApplicationMaster当中。
4)JobManager去ResourceManager中申请资源。
5)申请资源后最终启动TaskManager,并且进行任务的划分,然后分发给taskManager。
YARN模式是通过部署YARN session将Flink部署到NodeManager的相关容器当中。
13.Flink的任务调度原理
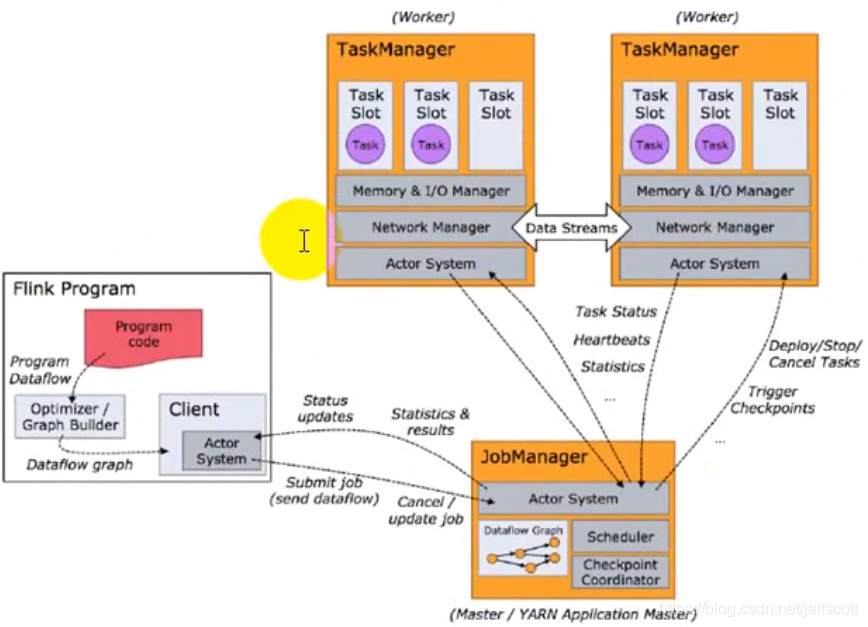
图片来源:尚硅谷大数据技术之Flink
1)将每个程序抽象为一个数据流图。
2)Actor System是模块之间的通信功能实现。
3)通过检测数据流图算子之间的分区是否有变化来划分task,然后将task分发给不同的slot。
4)每个TaskManager会根据配置的Slot的参数来将JVM等分为几个slot,注意只分配内存,不划分CPU。
5)slot数是支持的最大并行度,并行度参数决定最终的并行情况。
14.worker和slot之间的关系?
每一个worker(TaskManager)是一个JVM进程,它可能会在独立的线程上执行一个或多个subtask。通过slot来指定一个worker最多可以执行几个subtask。每一个task就是一个线程。
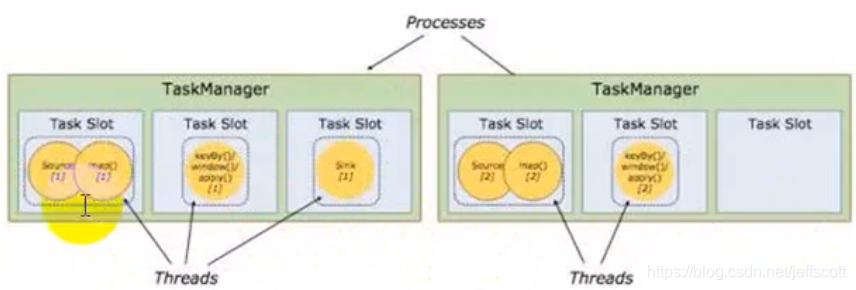
为了避免不同分区之间的通信导致资源浪费,只有当检测到分区数量变化时,才会将不同算子划分为不同的task,这一动作通过redistribute来完成,否则会将连续的算子放到一个task中去执行。
15.程序与数据流之间的关系
Flink程序的基础模块是流与转换,流的本质就上数据的中间处理结果,转换就是一个或多个算子。
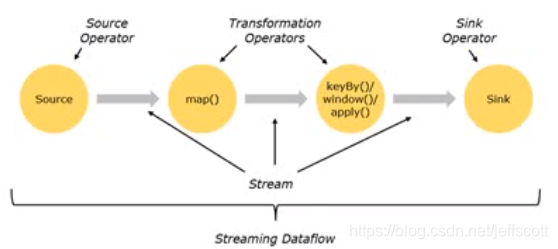
图片来源:尚硅谷大数据技术之Flink
资源获取,中间处理,最终通过sink进行结果的输出。
16.stream在operator之间的传输形式有哪些?
1)one-to-one:维护操作前后分区的个数以及元素的顺序。
2) redistribute:原来在同一分区的数据被分到不同的分区当中,数据被打散了。
3)对于两个算子之间属于one2one的关系时,可以将其组合在一起,放到一个task之间进行执行。只有对于会引起redistribute的算子才将其放到不同的task中进行执行。
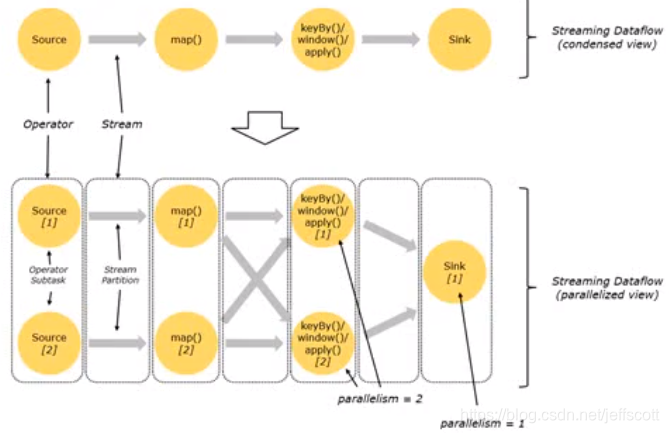
图片来源:尚硅谷大数据技术之Flink
17.Flink的运行模型?
1)获得一个执行环境。
2)加载/创建初始数据。
3)指定转换这些数据。
4)指定放置计算结果的位置。
5)触发程序执行。
18.Flink创建执行环境的方式有哪些?
1)getExecutionEnviroment,会查询运行的方式决定返回什么样的运行环境。
2) createLocalEnviroment,创建一个本地的执行环境。
3)createRemoteEnviroment,创建一个远端的执行环境。
19.Flink创建数据源有哪几种方式?
1)readTextFile(path),一列一列读取文本文件,并将结果作为String返回
2)readFile(fileInputFormat,path)
3)基于集合的数据源
4)基于socket的数据源
5)可以从kafka获取数据
20.Flink的Sink方式有哪些?
1)writeAsText
2) writeAsCsv
3) print/printToErr,直接将结果打印出来
4)writeUsingOutFormat(自定义对象到字节的转换)
5)writeToSocket,以socket的形式发送。
21. Flink常见的算子有哪些?
1)Map,
2) FlatMap,将一条数据按指定规则切分后。
3) Filter,按指定条件过滤掉。
4) Connect + CoMap/CoFlatmap。
5) Split + Select,将流按条件分割后,可以进行选择。
6)Union,将两个流合并为一个流。
7)KeyBy,将具有相同关键字的聚合在一起,放到同一个分区里面。
8)Reduce,进行聚合操作,需要先加窗口才可以。
9) Fold,
10) Aggregation,
22. 请简单说明Flink里面的window和Time的概念
1)Flink的时间一共分为Event Time(事件创建的时间),Ingestion Time(数据进入Flink的时间),Processing Time,就是每一个执行基于时间操作的算子的本地系统时间,与机器相关。
2)window可以分为两类,一种叫做countwindow,另一种叫做timewindow。可以根据窗口实现原理的不同分为三类:滚动窗口(Tumbling window),滑动窗口(Sliding window)和会话窗口(Session window)。
23.请简单说一下EventTime和Time的区别
1)EventTime是指日志记录中记录的时间,可以看做是事件的实际时间。
24.简单解释一下Watermark的含义
1)watermark是用来处理乱序事件的,而正确的处理乱序事件,通常用watermark结合window来实现。
2)数据流中的watermark用于表示eventTime小于watermark的数据,都已经到达了,因此window的执行也是由watermark触发的。
3)watermark本质上相当于是一个延迟触发机制,在window的触发机制里面,如果有步长,那么会根据步长的大小来进行触发,窗口大小是数据的缓存长度,过老的数据会被丢弃。














 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









