






LZW编码原理
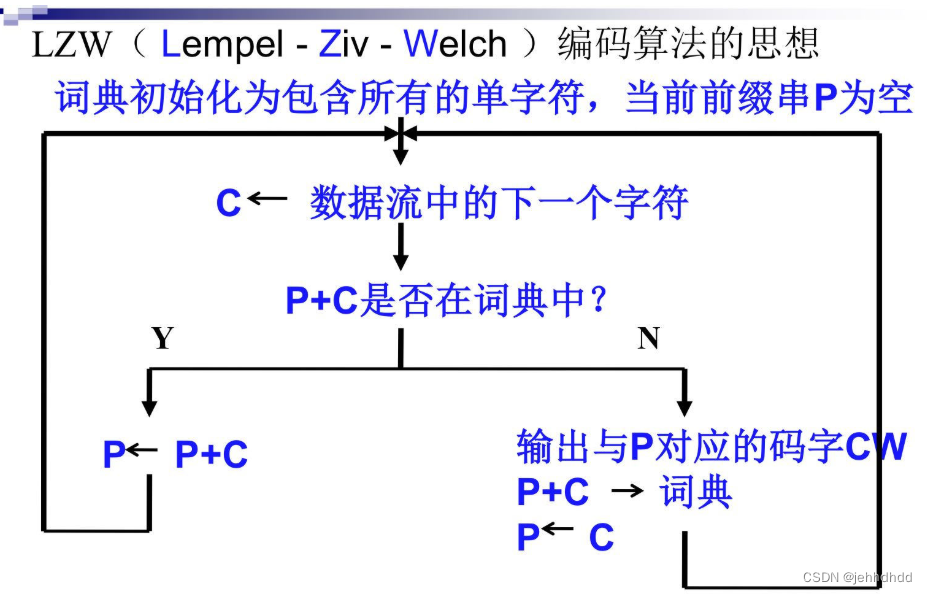
LZW的编码思想是不断地从字符流中提取新的字符串,然后用码字表示这个新字符串。这样用码字去替换字符流,生成码字流,可以达到压缩数据的目的。
1 编码步骤
步骤1:将词典初始化为包含所有可能的单字符(常用ASCII码表),
当前前缀P初始化为空。
步骤2:当前字符C=字符流中的下一个字符。
步骤3:判断P+C是否在词典中。
(1)如果“是”,则用C扩展P,即让P=P+C,返回到步骤2。
(2)如果“否”,则
输出与当前前缀P相对应的码字W;
将P+C添加到词典中;
令P=C,并返回到步骤2。
2 解码步骤
LZW解码算法开始时,译码词典和编码词典相同,包含所有可能的前缀根。具体解
码算法如下:
步骤1:在开始译码时词典包含所有可能的前缀根。
步骤2:令CW:=码字流中的第一个码字。
步骤3:输出当前缀-符串string.CW到码字流。
步骤4:先前码字PW:=当前码字CW。
步骤5:当前码字CW:=码字流的下一个码字。
步骤6:判断当前缀-符串string.CW 是否在词典中。
(1)如果”是”,则把当前缀-符串string.CW输出到字符流。
当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前前缀-符串string.CW的第一个字符。
把缀-符串P+C添加到词典。
(2)如果”否”,则当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前缀-符串string.CW的第一个字符。
输出缀-符串P+C到字符流,然后把它添加到词典中。
步骤7:判断码字流中是否还有码字要译。
(1)如果”是”,就返回步骤4。
(2)如果”否”,结束。
代码实现
首先定义结构体
struct {//词典节点结构体
int suffix; //后缀字符
int parent, firstchild, nextsibling;//母节点、第一个孩子节点、兄弟节点
} dictionary[MAX_CODE+1]; //数组下标为编码
typedef struct{//二进制文件结构体
FILE *fp;//输出文件指针
unsigned char mask;//掩码
int rack;//缓存,每写入8位,写入rack
}BITFILE;
编码代码
void LZWEncode( FILE *fp, BITFILE *bf){
int character;//字符
int string_code;//前缀
int index;//编码
unsigned long file_length;//文件大小
fseek( fp, 0, SEEK_END);//文件指针定位到文件最后
file_length = ftell( fp);//输入文件大小
fseek( fp, 0, SEEK_SET);//文件指针定位到文件起始
BitsOutput( bf, file_length, 4*8);//将输入文件大小写入输出文件。32位表示文件大小
InitDictionary();//词典初始化
string_code = -1;//前缀初始化
while( EOF!=(character=fgetc( fp))){//依次扫描输入文件,取出各字符
index = InDictionary( character, string_code);//判断码字string+character是否在词典中
if( 0<=index){ // string+character在词典中
string_code = index;//将string+character对应编码作为前缀
}else{ // string+character不在词典中
output( bf, string_code);//输出前缀
if( MAX_CODE > next_code){ // 若词典有剩余空间
// 将string+character加入词典
AddToDictionary( character, string_code);
}
string_code = character;//将新字符作为新的前缀
}
}
output( bf, string_code);//文件扫描完毕,将最后未输出的前缀输出
}
void InitDictionary( void){//词典初始化即将0-255根节点初始化
int i;
for( i=0; i<256; i++){//下标为ASCII码值
dictionary[i].suffix = i;//根的后缀字符为对应ASCII码
dictionary[i].parent = -1;//没有母节点
dictionary[i].firstchild = -1;//暂时没有第一个孩子节点
dictionary[i].nextsibling = i+1;//下一个兄弟节点下标为下一个ASCII码值
}
dictionary[255].nextsibling = -1;//最后一个根节点没有下一个兄弟节点
next_code = 256;//下一个编码为256
}
int InDictionary( int character, int string_code){//判断码字string+character是否在词典中 string_code前缀 character后缀
int sibling;
if( 0>string_code) return character;//文件第一个字符,故而编码为character的ASCII码值
/*自左向右遍历string_code节点的所有孩子(第一个孩子的所有兄弟)*/
sibling = dictionary[string_code].firstchild;//string_code节点的第一个孩子
while( -1<sibling){//sibling=-1时说明所有兄弟遍历结束
if( character == dictionary[sibling].suffix) return sibling;//若找到兄弟节点的后缀是character,则返回此节点的编码即下标sibling
sibling = dictionary[sibling].nextsibling;//若该兄弟节点后缀不是character,则寻找下一个兄弟节点
}
return -1;//若遍历所有兄弟节点的后缀后,都找不到该字符,说明string+character不在字典中,返回-1
}
void AddToDictionary( int character, int string_code){//码字不在词典,添加进词典中,并编码为next_code
int firstsibling, nextsibling;
if( 0>string_code) return;
dictionary[next_code].suffix = character;//新节点的后缀为该字符
dictionary[next_code].parent = string_code;//新节点的母亲节点为该前缀
dictionary[next_code].nextsibling = -1;//新节点下一个兄弟节点暂不存在
dictionary[next_code].firstchild = -1;//新节点的第一个孩子节点暂不存在
firstsibling = dictionary[string_code].firstchild;//新节点的母亲节点的第一个孩子
/*设置新节点的兄弟关系*/
if( -1<firstsibling){ // 若新节点的母亲节点原本有孩子
nextsibling = firstsibling;
while( -1<dictionary[nextsibling].nextsibling ) //循环找到该母亲节点的最后一个孩子即新节点的最后一个兄弟
nextsibling = dictionary[nextsibling].nextsibling;
dictionary[nextsibling].nextsibling = next_code;//将新节点设为最后一个兄弟的下一个兄弟
}else{// 若新节点的母亲节点原本没有孩子
dictionary[string_code].firstchild = next_code;//则新节点是母亲节点的第一个孩子
}
next_code ++;//下一个编码增加1
}
BITFILE *OpenBitFileOutput( char *filename){//输出文件名
BITFILE *bf;
bf = (BITFILE *)malloc( sizeof(BITFILE));
if( NULL == bf) return NULL;
if( NULL == filename) bf->fp = stdout;//如果参数为NULL,则指向屏幕
else bf->fp = fopen( filename, "wb");//以二进制只写的方式打开文件
if( NULL == bf->fp) return NULL;
bf->mask = 0x80;//掩码为10000000
bf->rack = 0;//缓存为0
return bf;
}void BitsOutput( BITFILE *bf, unsigned long code, int count){
unsigned long mask;
/*计算掩码值,位数为count的数值且最高位为1,例如若count为16,则mask=1000 0000 0000 0000*/
mask = 1L << (count-1);
while( 0 != mask){//mask为0时,说明code的count位数字输出完毕,注意:LZW是等长码
BitOutput( bf, (int)(0==(code&mask)?0:1));//按位输出code
mask >>= 1;//掩码向右移位
}
}
void BitOutput( BITFILE *bf, int bit){
/*若bite=1,则本code输出结束,此时mask为1,rack为0,则缓存rack变为1
若bit=0,则尚未输出结束,此时mask向右移位,为0,rack不变*/
if( 0 != bit) bf->rack |= bf->mask;
bf->mask >>= 1;//mask向右移1位
/*若mask溢出为0,则表示成功累计写入8位,则直接输出rack,
并将rack初始化为0,mask初始化为1000 0000*/
if( 0 == bf->mask){ // eight bits in rack
fputc( bf->rack, bf->fp);
bf->rack = 0;
bf->mask = 0x80;
}
}解码代码
void LZWDecode( BITFILE *bf, FILE *fp){
//需填写
int character;//新/旧编码首字母
int new_code;//新编码
int last_code = -1;//起初旧编码空缺,初始化为-1
int string_length;//输出字符串长度
unsigned long file_length;//输出文件大小
file_length = BitsInput(bf, 4*8);//输入文件起始处为输出文件大小,共32位
if (-1 == file_length) file_length = 0;//若文件无内容,大小为0
InitDictionary();//词典初始化,设置0-255的根节点
while (file_length > 0) {//若读取到最后一个编码,结束循环
new_code = input(bf);//16位读取新编码
if (new_code >= next_code) {//若字典中没有新编码
d_stack[0] = character;//character为旧编码last_code的首字母,将其放置在数组d_stack[0]首位
/*遍历旧编码last_code所在树,将last_code对应字符串放入d_stack,前缀在栈底,后缀在d_stack[1]。返回字符串长度*/
string_length = DecodeString(1, last_code);
}
else {//若字典中已有新编码
/*遍历新编码new_code所在树,将new_code对应字符串放入d_stack,前缀在栈底,后缀在d_stack[0]。返回字符串长度*/
string_length = DecodeString(0, new_code);
}
/*若新读取的编码不存在于词典中,character为旧编码last_code的首字母
若新读取的编码存在于词典中,character为新编码new_code的首字母*/
character = d_stack[string_length - 1];
/*若新读取的编码不存在于词典中,输出旧编码last_code对应字符串+last_code的首字母
若新读取的编码存在于词典中,输出新编码new_code对应字符串*/
while (string_length > 0) {
string_length--;
fputc(d_stack[string_length], fp);
file_length--;
}
/*若新读取的编码不存在于词典中,将last_code对应字符串+last_code的首字母添加到词典
若新读取的编码存在于词典中,将last_code对应字符串+new_code的首字母添加到词典*/
if (MAX_CODE > next_code) {
AddToDictionary(character, last_code);
}
last_code = new_code;//新编码变为旧编码
}
}最后返回解码字符串长度
int longString(int start, int code){
int count;
count = start;
while (0 <= code) {
d_stack[count] = dictionary[code].suffix;
code = dictionary[code].parent;
count++;
}
return count;
}效果如图















 4952
4952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









