







快速排序[编辑]



算法[编辑]

快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
步骤为:
- 从数列中挑出一个元素,称为 "基准"(pivot),
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
在简单的伪代码中,此算法可以被表示为:
function quicksort(q)
var list less, pivotList, greater
if length(q) ≤ 1 {
return q
} else {
select a pivot value pivot from q
for each x in q except the pivot element
if x < pivot then add x to less
if x ≥ pivot then add x to greater
add pivot to pivotList
return concatenate(quicksort(less), pivotList, quicksort(greater))
}
原地(in-place)分区的版本[编辑]
上面简单版本的缺点是,它需要Ω(n)的额外存储空间,也就跟归并排序一样不好。额外需要的存储器空间配置,在实际上的实现,也会极度影响速度和高速缓存的性能。有一个比较复杂使用原地(in-place)分区算法的版本,且在好的基准选择上,平均可以达到O(log n)空间的使用复杂度。
function partition(a, left, right, pivotIndex)
pivotValue := a[pivotIndex]
swap(a[pivotIndex], a[right]) // 把 pivot 移到結尾
storeIndex := left
for i from left to right-1
if a[i] < pivotValue
swap(a[storeIndex], a[i])
storeIndex := storeIndex + 1
swap(a[right], a[storeIndex]) // 把 pivot 移到它最後的地方
return storeIndex
这是原地分区算法,它分区了标示为 "左边(left)" 和 "右边(right)" 的串行部份,借由移动小于a[pivotIndex]的所有元素到子串行的开头,留下所有大于或等于的元素接在他们后面。在这个过程它也为基准元素找寻最后摆放的位置,也就是它回传的值。它暂时地把基准元素移到子串行的结尾,而不会被前述方式影响到。由于算法只使用交换,因此最后的数列与原先的数列拥有一样的元素。要注意的是,一个元素在到达它的最后位置前,可能会被交换很多次。
一旦我们有了这个分区算法,要写快速排列本身就很容易:
procedure quicksort(a, left, right)
if right > left
select a pivot value a[pivotIndex]
pivotNewIndex := partition(a, left, right, pivotIndex)
quicksort(a, left, pivotNewIndex-1)
quicksort(a, pivotNewIndex+1, right)
这个版本经常会被使用在命令式语言中,像是C语言。
优化的排序算法[编辑]
快速排序是二叉查找树(二叉查找树)的一个空间优化版本。不是循序地把数据项插入到一个明确的树中,而是由快速排序组织这些数据项到一个由递归调用所隐含的树中。这两个算法完全地产生相同的比较次数,但是顺序不同。对于排序算法的稳定性指标,原地分区版本的快速排序算法是不稳定的。其他变种是可以通过牺牲性能和空间来维护稳定性的。
快速排序的最直接竞争者是堆排序(Heapsort)。堆排序通常比快速排序稍微慢,但是最坏情况的运行时间总是O(n log n)。快速排序是经常比较快,除了introsort变化版本外,仍然有最坏情况性能的机会。如果事先知道堆排序将会是需要使用的,那么直接地使用堆排序比等待 introsort 再切换到它还要快。堆排序也拥有重要的特点,仅使用固定额外的空间(堆排序是原地排序),而即使是最佳的快速排序变化版本也需要Θ(log n)的空间。然而,堆排序需要有效率的随机存取才能变成可行。
快速排序也与归并排序(Mergesort)竞争,这是另外一种递归排序算法,但有坏情况O(n log n)运行时间的优势。不像快速排序或堆排序,归并排序是一个稳定排序,且可以轻易地被采用在链表(linked list)和存储在慢速访问媒体上像是磁盘存储或网络连接存储的非常巨大数列。尽管快速排序可以被重新改写使用在炼串行上,但是它通常会因为无法随机存取而导致差的基准选择。归并排序的主要缺点,是在最佳情况下需要Ω(n)额外的空间。
正规的分析[编辑]
从一开始快速排序平均需要花费O(n log n)时间的描述并不明显。但是不难观察到的是分区运算,数组的元素都会在每次循环中走访过一次,使用O(n)的时间。在使用结合(concatenation)的版本中,这项运算也是O(n)。
在最好的情况,每次我们运行一次分区,我们会把一个数列分为两个几近相等的片段。这个意思就是每次递归调用处理一半大小的数列。因此,在到达大小为一的数列前,我们只要作 log n 次嵌套的调用。这个意思就是调用树的深度是O(log n)。但是在同一层次结构的两个程序调用中,不会处理到原来数列的相同部份;因此,程序调用的每一层次结构总共全部仅需要O(n)的时间(每个调用有某些共同的额外耗费,但是因为在每一层次结构仅仅只有O(n)个调用,这些被归纳在O(n)系数中)。结果是这个算法仅需使用O(n log n)时间。
另外一个方法是为T(n)设立一个递归关系式,也就是需要排序大小为n的数列所需要的时间。在最好的情况下,因为一个单独的快速排序调用牵涉了O(n)的工作,加上对n/2大小之数列的两个递归调用,这个关系式可以是:
- T( n) = O( n) + 2T( n/2)
解决这种关系式型态的标准数学归纳法技巧告诉我们T(n) = O(n log n)。
事实上,并不需要把数列如此精确地分区;即使如果每个基准值将元素分开为 99% 在一边和 1% 在另一边,调用的深度仍然限制在 100log n,所以全部运行时间依然是O(n log n)。
然而,在最坏的情况是,两子数列拥有大各为 1 和 n-1,且调用树(call tree)变成为一个 n 个嵌套(nested)调用的线性连串(chain)。第 i 次调用作了O(n-i)的工作量,且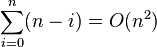 递归关系式为:
递归关系式为:
- T( n) = O( n) + T(1) + T( n - 1) = O( n) + T( n - 1)
这与插入排序和选择排序有相同的关系式,以及它被解为T(n) = O(n2)。
乱数快速排序的期望复杂度[编辑]
乱数快速排序有一个值得注意的特性,在任意输入数据的状况下,它只需要O(n log n)的期望时间。是什么让随机的基准变成一个好的选择?
假设我们排序一个数列,然后把它分为四个部份。在中央的两个部份将会包含最好的基准值;他们的每一个至少都会比25%的元素大,且至少比25%的元素小。如果我们可以一致地从这两个中央的部份选出一个元素,在到达大小为1的数列前,我们可能最多仅需要把数列分区2log2 n次,产生一个 O(nlogn)算法。
不幸地,乱数选择只有一半的时间会从中间的部份选择。出人意外的事实是这样就已经足够好了。想像你正在翻转一枚硬币,一直翻转一直到有 k 次人头那面出现。尽管这需要很长的时间,平均来说只需要 2k 次翻动。且在 100k 次翻动中得不到 k 次人头那面的机会,是像天文数字一样的非常小。借由同样的论证,快速排序的递归平均只要2(2log2 n)的调用深度就会终止。但是如果它的平均调用深度是O(log n)且每一阶的调用树状过程最多有 n 个元素,则全部完成的工作量平均上是乘积,也就是 O(n log n)。
平均复杂度[编辑]
即使如果我们无法随机地选择基准数值,对于它的输入之所有可能排列,快速排序仍然只需要O(n log n)时间。因为这个平均是简单地将输入之所有可能排列的时间加总起来,除以n这个因子,相当于从输入之中选择一个随机的排列。当我们这样作,基准值本质上就是随机的,导致这个算法与乱数快速排序有一样的运行时间。
更精确地说,对于输入顺序之所有排列情形的平均比较次数,可以借由解出这个递归关系式可以精确地算出来。

在这里,n-1 是分区所使用的比较次数。因为基准值是相当均匀地落在排列好的数列次序之任何地方,总和就是所有可能分区的平均。
这个意思是,平均上快速排序比理想的比较次数,也就是最好情况下,只大约比较糟39%。这意味着,它比最坏情况较接近最好情况。这个快速的平均运行时间,是快速排序比其他排序算法有实际的优势之另一个原因。
空间复杂度[编辑]
被快速排序所使用的空间,依照使用的版本而定。使用原地(in-place)分区的快速排序版本,在任何递归调用前,仅会使用固定的額外空間。然而,如果需要产生O(log n)嵌套递归调用,它需要在他们每一个存储一个固定数量的信息。因为最好的情况最多需要O(log n)次的嵌套递归调用,所以它需要O(log n)的空间。最坏情况下需要O(n)次嵌套递归调用,因此需要O(n)的空间。
然而我们在这里省略一些小的细节。如果我们考虑排序任意很长的数列,我们必须要记住我们的变量像是left和right,不再被认为是占据固定的空间;也需要O(log n)对原来一个n项的数列作索引。因为我们在每一个堆栈框架中都有像这些的变量,实际上快速排序在最好跟平均的情况下,需要O(log2 n)空间的比特数,以及最坏情况下O(n log n)的空间。然而,这并不会太可怕,因为如果一个数列大部份都是不同的元素,那么数列本身也会占据O(n log n)的空间字节。
非原地版本的快速排序,在它的任何递归调用前需要使用O(n)空间。在最好的情况下,它的空间仍然限制在O(n),因为递归的每一阶中,使用与上一次所使用最多空间的一半,且
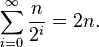
它的最坏情况是很恐怖的,需要

空间,远比数列本身还多。如果这些数列元素本身自己不是固定的大小,这个问题会变得更大;举例来说,如果数列元素的大部份都是不同的,每一个将会需要大约O(log n)为原来存储,导致最好情况是O(n log n)和最坏情况是O(n2 log n)的空间需求。
选择的关连性[编辑]
选择算法(selection algorithm)可以选取一个数列的第k个最小值;一般而言这是比排序还简单的问题。一个简单但是有效率的选择算法与快速排序的作法相当类似,除了对两个子数列都作递归调用外,它仅仅针对包含想要的元素之子数列作单一的结尾递归(tail recursive)调用。这个小改变降低了平均复杂度到线性或是Θ(n)时间,且让它成为一个原地算法。这个算法的一种变化版本,可以让最坏情况下降为O(n)(参考选择算法来得到更多信息)。
相反地,一旦我们知道一个最坏情况的O(n)选择算法是可以利用的,我们在快速排序的每一步可以用它来找到理想的基准(中位数),得到一种最坏情况下O(n log n)运行时间的变化版本。在实际的实现,然而这种版本一般而言相当的慢。
实现示例[编辑]
于此我们展示在数种语言下的几个快速排序实现。我们在此仅展示出最普遍或独特的一些;针对其他的实现,参见快速排序实现条目。
C[编辑]
#include <stdio.h> int a[] = { 1, 2, 8, 7, 9, 5, 6, 4, 3, 66, 77, 33, 22, 11 }; /* 输出数组前n各元素 */ void prt(int n) { int i; for (i = 0; i < n; i++) { printf("%d\t", a[i]); } printf("\n"); } void quick_sort (int data[], size_t left, size_t right) { size_t p = (left + right) / 2; int pivot = data[p]; size_t i = left,j = right; for ( ; i < j;) { while (! (i>= p || pivot < data[i])) ++i; if (i < p) { data[p] = data[i]; p = i; } while (! (j <= p || data[j] < pivot)) --j; if (j > p) { data[p] = data[j]; p = j; } } data[p] = pivot; if (p - left > 1) quick_sort(data, left, p - 1); if (right - p > 1) quick_sort(data, p + 1, right); } int main(void) { /* 排序与输出 */ quick_sort(a, 0, 13); prt(14); return 0; }
C89标准在stdlib.h中定义了抽象数据类型的快速排序函数 qsort(3)。
#include <stdio.h> #include <stdlib.h> static int cmp(const void *a, const void *b) { return *(int *)a - *(int *)b; } int main() { int arr[10]={5, 3, 7, 4, 1, 9, 8, 6, 2}; qsort(arr, 10, sizeof(int), cmp); return 0; }















 2189
2189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









