







1.Redis分片实现
1.1 为什么是使用分片
1)说明:虽然inredsi可以扩展内存空间的大小,但是如果需要存储海量的数据一味的扩大内存,其实效 率也不高
2)分片介绍:准备多态redis,共同为用户提供缓存服务,在保证效率的前提下,实现了内存的扩容
1.2 分片搭建
1.2.1 分片规划
由3台redis构成 端口号分别为6379/6380/6381,如果需要准备多台redis,那就准备多个redis配置文件,注意其中的端口号
1.2.2 准备多台redis

1.2.3 修改redis端口
说明:修改redis的端口号 vim 6380.conf

1.2.4 启动多台redis服务
命令:redis-server 6379.conf & redis-server 6380.conf & redis-server 6381.conf &

1.2.5 spring整合Redis入门案例
public class TestRedisShards {
//思考:key=shards 存储到了哪台redis中? 如何存储的?
@Test
public void test01() {
//1.准备list集合之后添加节点信息
List<JedisShardInfo> shards = new ArrayList<JedisShardInfo>();
shards.add(new JedisShardInfo("192.168.126.131",6379));
shards.add(new JedisShardInfo("192.168.126.131",6380));
shards.add(new JedisShardInfo("192.168.126.131",6381));
//2.创建分片对象
ShardedJedis shardedJedis = new ShardedJedis(shards);
shardedJedis.set("shards", "准备分片操作");
System.out.println(shardedJedis.get("shards"));
}
}
1.3 一致性hash算法
一致性hash算法是一种特殊的hash算法,目的是解决分布式缓存的问题。在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了简单哈希算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的动态伸缩等问题
1.3.1 一致性hash原理说明
目的:解决数据如何在分布式环境下进行存储!!!
hash取值区间: 8位16进制数 共有 2^32种可能性!!! (24)8=2^32次方
1).数据如何存储

2).当节点发生变化带来哪些影响
当节点的数量发生了变化时,则节点中的对应的数据可以动态的迁移.
原则: 当发生了节点变化时,应该尽可能小的影响其他节点.

1.3.2 一致性hash特性
一致性哈希算法是在哈希算法基础上提出的,在动态变化的分布式环境中,哈希算法应该满足的几个条件:平衡性、单调性和分散性 [4] 。
①平衡性(均衡性)是指hash的结果应该平均分配到各个节点,这样从算法上解决了负载均衡问题 [4] 。 利用虚拟节点实现数据平衡 (平衡数据不能做到绝对平均,只能是相对的)
②单调性是指在新增或者删减节点时,不影响系统正常运行 . 可以实现动态的数据迁移.
③分散性是指数据应该分散地存放在分布式集群中的各个节点(节点自己可以有备份),不必每个节点都存储所有的数据 [4]
1.4 SpringBoot整合Redis分片
1.4.1 编辑分片properties配置文件
redis.nodes=192.168.126.131:6379,192.168.126.131:6380,192.168.126.131:6381

1.4.2 编辑RedisConfig配置类整合redis
@Configuration //表示该类是配置类 一般与@Bean连用
@PropertySource(value = "classpath:/properties/redis.properties")
public class RedisConfig {
@Value("${redis.nodes}")
private String redisNodes; //node,node,node
/**
* 整合分片实现redis内存扩容
*/
@Bean
public ShardedJedis shardedJedis() {
String[] nodes = redisNodes.split(",");//节点数组
List<JedisShardInfo> shards = new ArrayList<>();
for (String node : nodes) {//node-> [host:port]
String host = node.split(":")[0];//host
int port = Integer.parseInt(node.split(":")[1]);
shards.add(new JedisShardInfo(host, port));
}
//返回分片对象
return new ShardedJedis(shards);
}
/**
* 单台redis测试
@Value("${redis.host}")
private String host;
@Value("${redis.port}")
private Integer port;
@Bean
public Jedis jedis() {
return new Jedis(host, port);
}
*/
}
1.4.3 修改CacheRedis中的注入–实现redis整合AOP

1.4.4 关于redis分片总结
1.当redis节点宕机之后,用户访问必然受到影响.
2.当redis服务宕机之后,该节点中的数据可能丢失
3.Redis分片可以实现内存数据的扩容.
4.Redis分片机制中hash运算发生在业务服务器中.redis只负责存取.不负责计算. 所以效率更高.
2 Redis属性说明
2.1 Redis持久化策略
2.1.1 Redis持久化策略说明
说明: Redis的数据都保存在内存中,如果断电或者宕机,则内存数据将擦除,导致数据的丢失.为了防止数据丢失,Redis内部有持久化机制.
当第一次Redis服务启动时,根据配置文件中的持久化要求.进行持久化操作.如果不是第一次启动,则在服务启动时会根据持久化文件的配置,读取指定的持久化文件.实现内存数据的恢复.
2.1.2 RDB模式
特点:
1.rdb模式是redis中默认的持久化策略.
2.rdb模式定期持久化.保存的是Redis中的内存数据快照.持久化文件占用空间较小.
3.rdb模式可能导致内存数据丢失
命令:
前提:需要在redis的客户端中执行.
- save 命令 立即持久化 会导致其他操作陷入阻塞.
- bgsave 命令 开启后台运行. 以异步的方式进行持久化. 不会造成其他操作的阻塞.
持久化周期:
save 900 1 900秒内,如果用户执行的1次更新操作,则持久化一次
save 300 10 300秒内,如果用户执行的10次更新操作,则持久化一次
save 60 10000 60秒内,如果用户执行的10000次更新操作,则持久化一次
save 1 1 1秒内,如果用户执行的1次更新操作,则持久化一次 set 阻塞!!!!
持久化文件:

持久化文件路径:

2.1.3 AOF模式
特点:
1). AOF模式默认条件下是关闭状态. 如果需要开启则需要修改配置文件.
2). AOF模式可以实现数据的实时持久化操作,AOF模式记录的是用户的操作过程.
3). 只要开启了AOF模式,则持久化方式以AOF模式为主.
配置:
开启AOF持久化方式

持久化文件格式:

持久化文件名称配置:

持久化文件策略说明
appendfsync always 只要用户执行一次操作,则持久化一次.
**appendfsync everysec 每秒持久化一次 默认策略** 效率略低于RDB
appendfsync no 不主动持久化
2.1.4 持久化总结
1.如果用户允许少量的数据丢失,则可以选用RDB模式. 效率更高
2.如果用户不允许数据丢失,则选用AOF模式.
3.可以2种方式都选, 需要搭建组从结构 , 主机选用RDB模式, 从机选用AOF模式,可以保证业务允许.
2.1.5 配置多种持久化方式
1).设计 : 6379 当主机 7380当从机.
2).修改主机的配置文件:
要求: 主机使用RDB模式

从机使用AOF模式

3).检查默认模式的状态
命令: info replication

4).实现主从挂载
编辑从服务器向主机进行挂载

5).主从测试
1.主机中添加测试数据.
2.检查从机中是否有数据
3.检查持久化文件是否有数据.
总结: 一般条件下主机采用RDB模式,从机采用AOF模式,效率更高.
2.2 Redis内存策略
2.2.1 内存策略说明
如果向redis中添加数据,如果不定期维护内存的大小,则可能会出现内存溢出的问题. 所以通过有效的内存的策略来维护内存的大小.
2.2.2 LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
2.2.3 LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
2.2.4 Random算法
随机算法
2.2.5 TTL算法
说明:在设定了超时时间的数据中,将马上超时的数据提前删除.
2.2.6Redis内存策略的配置
1.volatile-lru -> 在设定超时时间的数据选中lru算法提前删除数据.
2.allkeys-lru -> 所有的数据都采用lru算法删除.
3.volatile-lfu -> 设定了超时时间的数据采用lfu算法
4.allkeys-lfu -> 所有的数据采用lfu
5.volatile-random -> 设定超时时间的数据采用random算法
6.allkeys-random -> 所有数据随机
7.volatile-ttl -> 将马上要超时的数据提前删除.
8.noeviction -> 不会删除数据,并且该配置项是默认的配置.如果内存数据存满了将会报错返回.
2.3 Redis集群
2.3.1 集群搭建
2.3.1.1 准备集群文件夹
1.准备集群文件夹
Mkdir cluster
2.在cluster文件夹中分别创建7000-7005文件夹

2.3.1.2 复制配置文件
说明:
将redis根目录中的redis.conf文件复制到cluster/7000/ 并以原名保存
cp redis.conf cluster/7000/
2.3.1.3 编辑配置文件
-
注释本地绑定IP地址

-
关闭保护模式

-
修改端口号

-
启动后台启动

-
修改pid文件

-
修改持久化文件路径

-
设定内存优化策略

-
关闭AOF模式
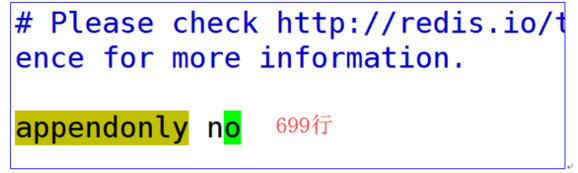
-
开启集群配置

-
开启集群配置文件
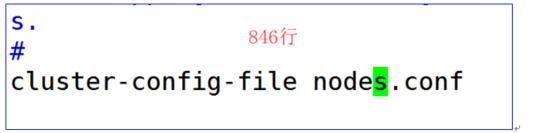
-
修改集群超时时间

2.3.1.4 复制修改后的配置文件
说明:将7000文件夹下的redis.conf文件分别复制到7001-7005中
[root@localhost cluster]# cp 7000/redis.conf 7001/
[root@localhost cluster]# cp 7000/redis.conf 7002/
[root@localhost cluster]# cp 7000/redis.conf 7003/
[root@localhost cluster]# cp 7000/redis.conf 7004/
[root@localhost cluster]# cp 7000/redis.conf 7005/
2.3.1.5 批量修改
说明:分别将7001-7005文件中的7000改为对应的端口号的名称,

2.3.1.6 通过脚本编辑启动/关闭指令
- 创建启动脚本 vim start.sh

- 编辑关闭的脚本 vim shutdown.sh

- 启动redis节点
sh start.sh - 检查redis节点启动是否正常
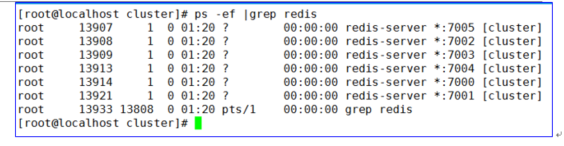
2.3.1.7 创建redis集群
#5.0版本执行
redis-cli --cluster create --cluster-replicas 1 192.168.126.131:7000 192.168.126.131:7001 192.168.126.131:7002 192.168.126.131:7003 192.168.126.131:7004 192.168.126.131:7005

2.3.2 SpringBoot整合redis集群
入门案例
public class TestCluster {
@Test
public void TestCluster01() {
HashSet<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.126.131", 7000));
nodes.add(new HostAndPort("192.168.126.131", 7001));
nodes.add(new HostAndPort("192.168.126.131", 7002));
nodes.add(new HostAndPort("192.168.126.131", 7003));
nodes.add(new HostAndPort("192.168.126.131", 7004));
nodes.add(new HostAndPort("192.168.126.131", 7005));
//利用程序操作redis集群
JedisCluster jedisCluster = new JedisCluster(nodes);
jedisCluster.set("abc", "redis集群测试");
System.out.println(jedisCluster.get("abc"));
}
}















 3140
3140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









