







使用Dev Tools操作es首先确保正确安装Kibana并和es配置成功,可参考我另一篇文章Windows安装Kibana
Dev Tools工具
我的是汉化了的,如果是英文版的在相应位置就好像就叫 Dev Tools
查看es信息
GET /

新增数据
自动生成id
格式:POST /test/_doc/ { }
test:自己的index,如果是新建就随意定义
{ }:json字符串,也是根据自己想存什么数据就存什么数据
如:
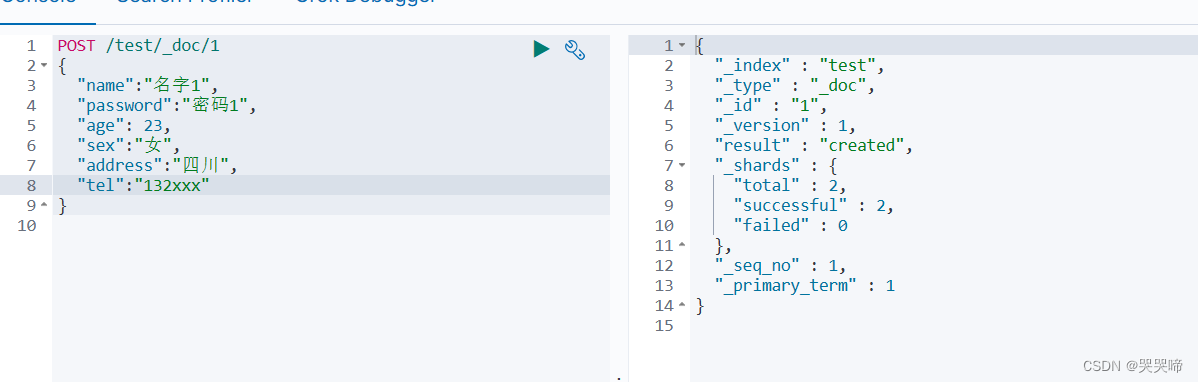
POST /test/_doc/
{
"name":"名字",
"password":"密码",
"age": 22,
"sex":"男",
"address":"地址xxx",
"tel":"电话"
}

手动生成id
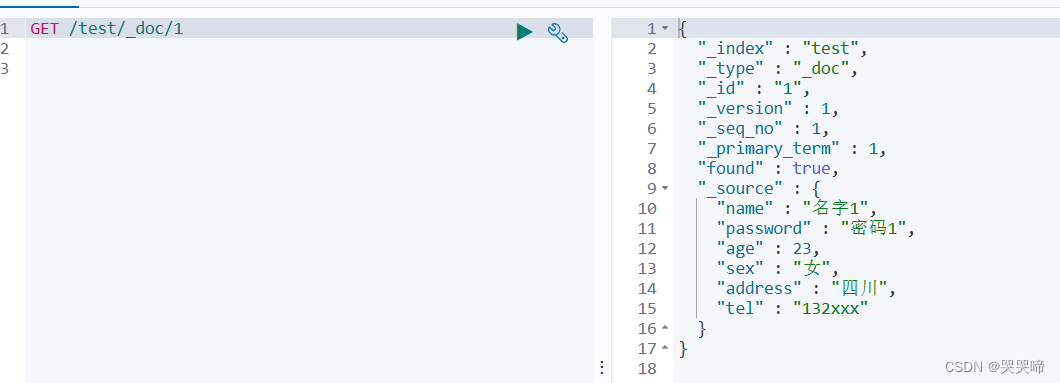
POST /test/_doc/1
{
"name":"名字1",
"password":"密码1",
"age": 23,
"sex":"女",
"address":"四川",
"tel":"132xxx"
}
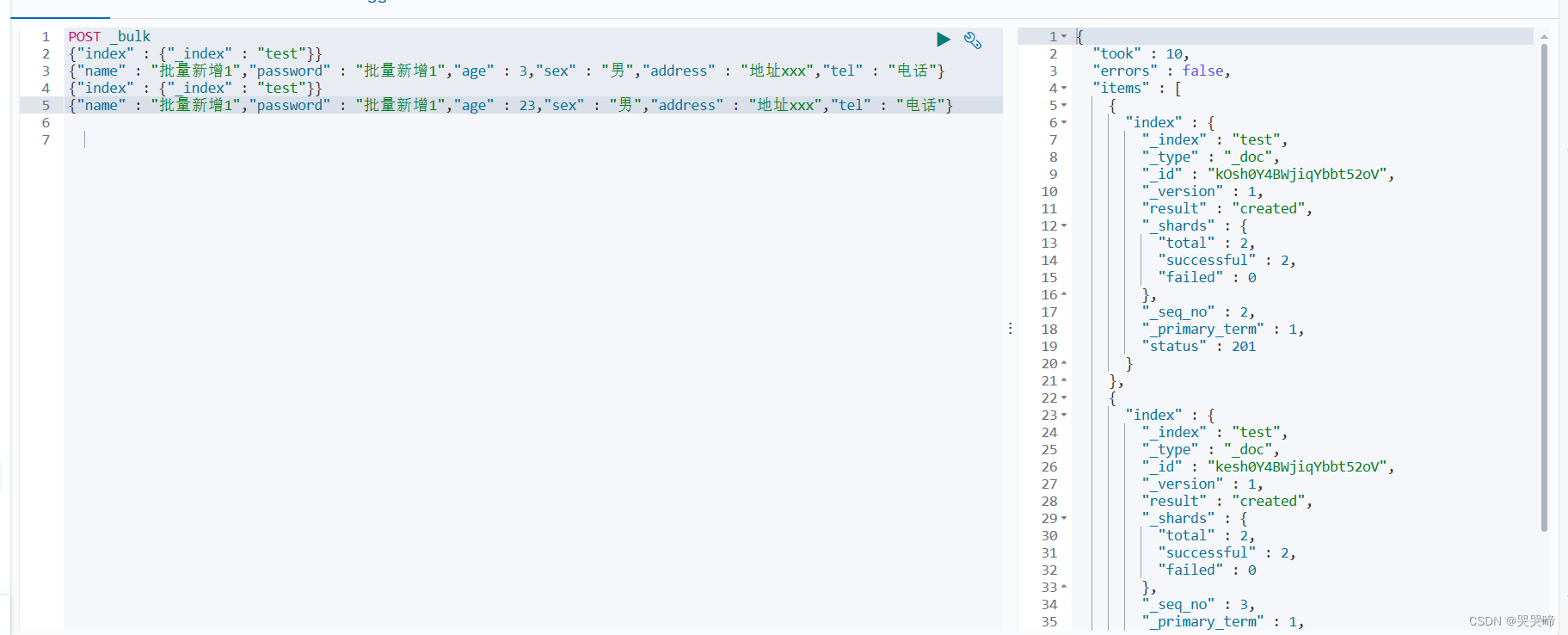
批量新增
POST _bulk
{"index" : {"_index" : "test"}}
{"name" : "批量新增1","password" : "批量新增1","age" : 3,"sex" : "男","address" : "地址xxx","tel" : "电话"}
{"index" : {"_index" : "test"}}
{"name" : "批量新增1","password" : "批量新增1","age" : 23,"sex" : "男","address" : "地址xxx","tel" : "电话"}
插入的数据不能使用刚才创建数据时的那种多行形式,只能使用没有回车的一条数据,否则会报错
也可以指定id
POST _bulk
POST _bulk
{"index" : {"_index" : "test","_id" : 2}}
{"name" : "批量新增2","password" : "批量新增1","age" : 3,"sex" : "男","address" : "地址xxx","tel" : "电话"}
{"index" : {"_index" : "test","_id" : 3}}
{"name" : "批量新增3","password" : "批量新增1","age" : 23,"sex" : "男","address" : "地址xxx","tel" : "电话"}
查询数据
所有数据
_search是固定的
GET /test/_search
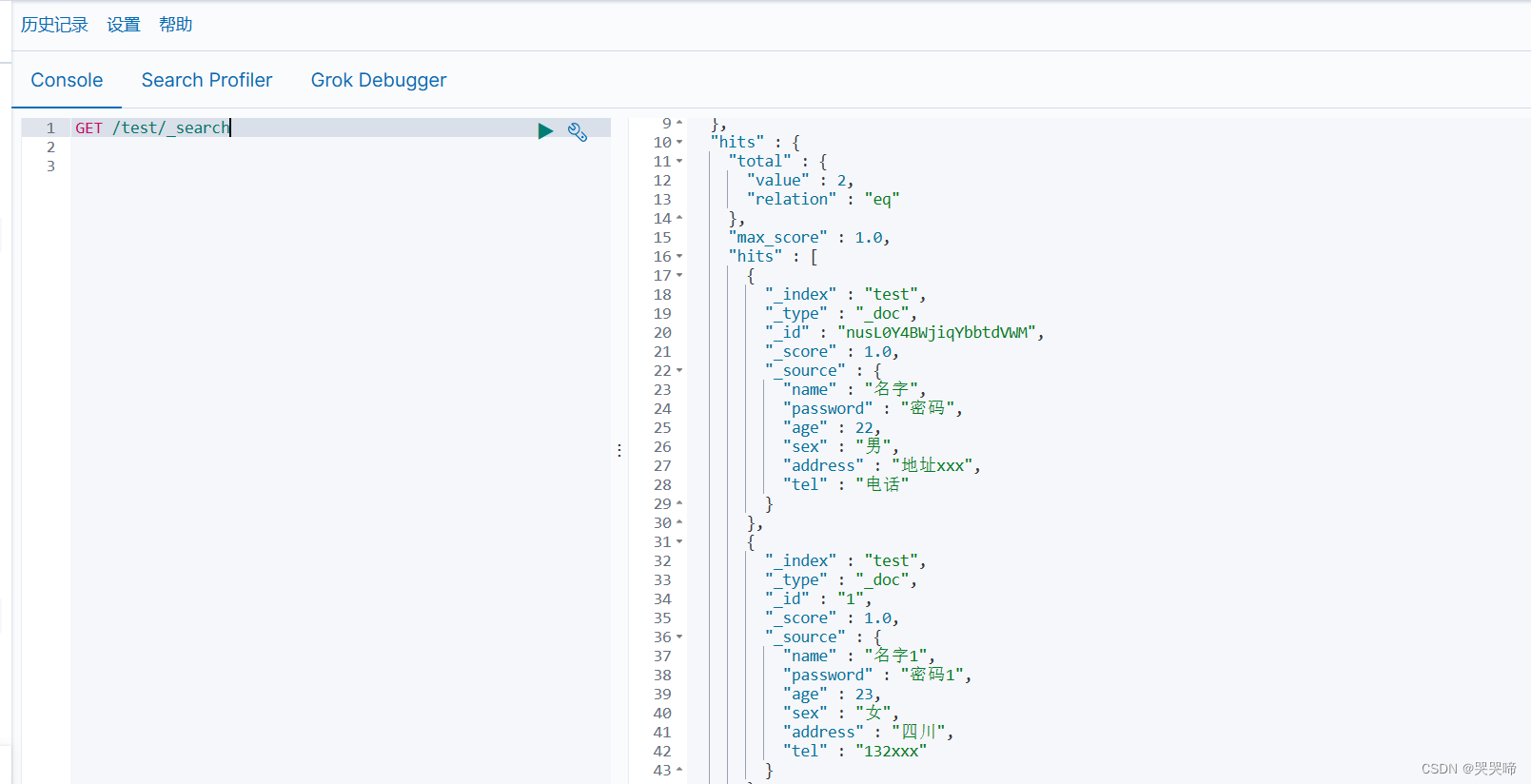
GET /test/_search
{
"query": {
"match_all": {
}
}
}
根据id
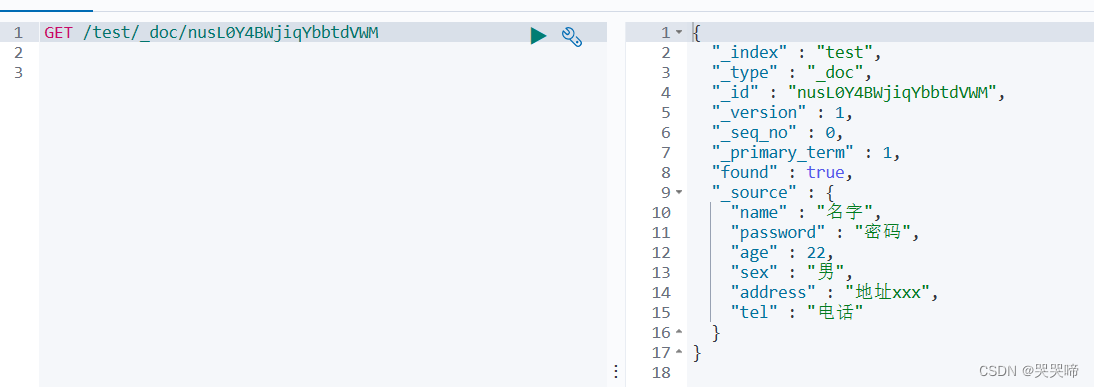
GET /test/_doc/1
_doc 是固定的
1 是id
条件查询
所有查询条件如果是字符串形式,如果无法匹配,就需要在查询属性后面加
.keyword
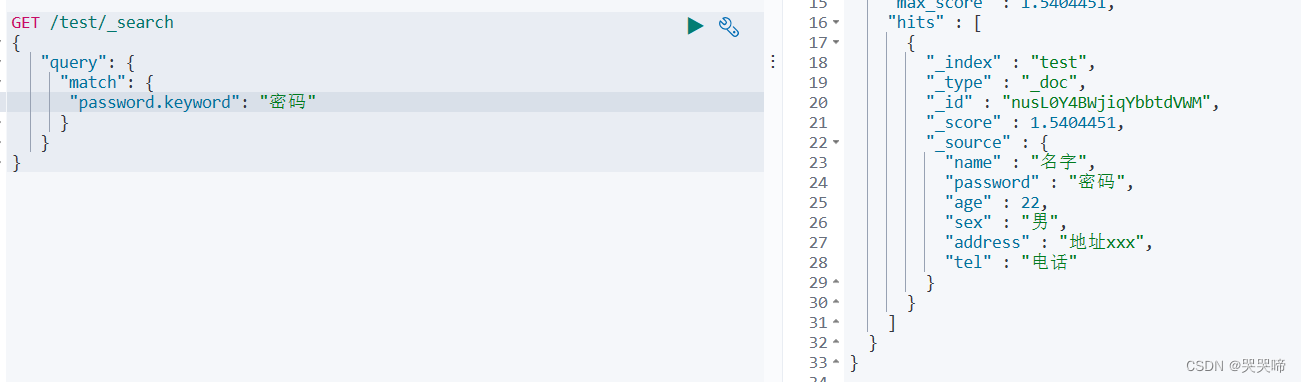
单条件查询
password 等于密码
GET /test/_search
{
"query": {
"match": {
"password.keyword": "密码"
}
}
}
查询和筛选上下文
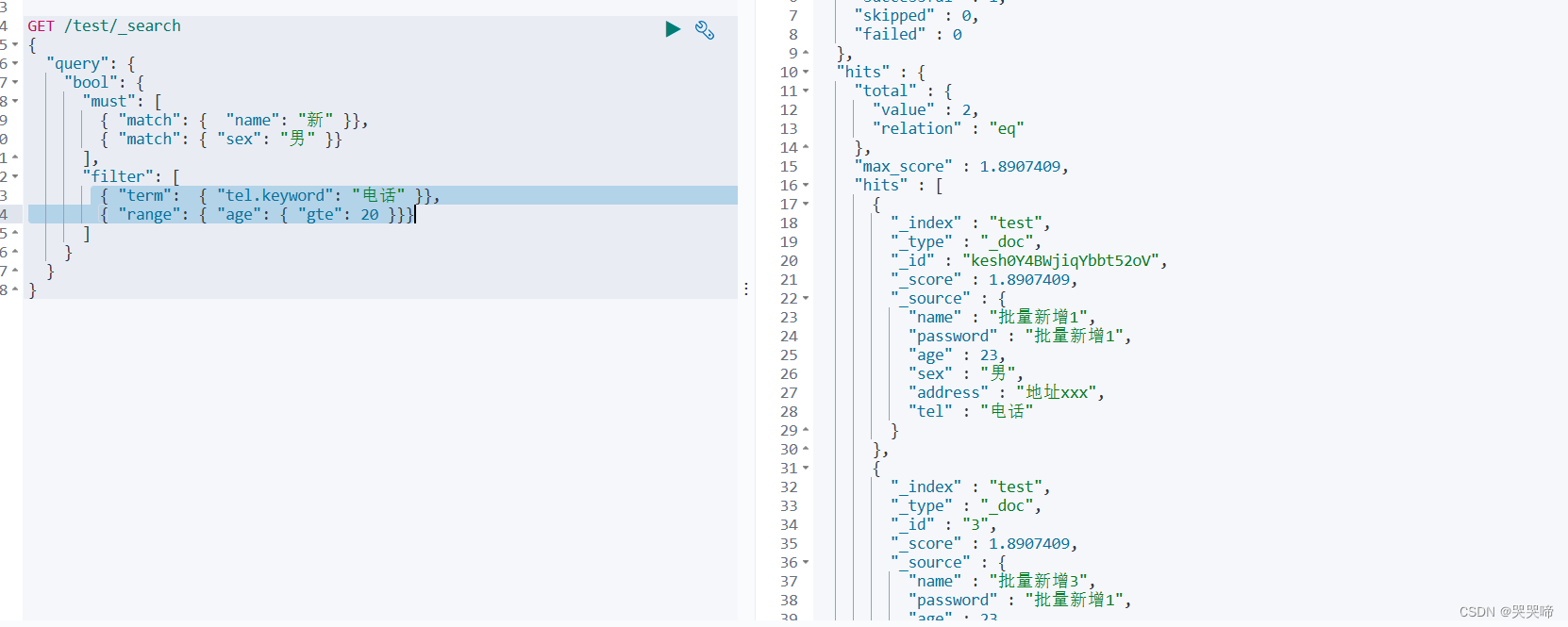
多个条件查询必须使用 bool must
查询name包含新,sex包含男,tel等于电话,age大于20的数据
filter 参数指示筛选器上下文。它的 and 子句用于筛选器上下文。它们会过滤掉 不匹配的文件,但它们会 不影响匹配文档的分数。
GET /test/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "新" }},
{ "match": { "sex": "男" }}
],
"filter": [
{ "term": { "tel.keyword": "电话" }},
{ "range": { "age": { "gte": 20 }}}
]
}
}
}
复合查询
关键字
-
minimum_should_match 设置为 0:表示查询中至少有一个 should 子句需要匹配,也就是说,只要有一个条件满足,文档就有可能被返回。这通常会导致较高的召回率,但可能会降低精度。
minimum_should_match 设置为 1:表示所有的 should 子句都需要匹配,即所有指定的条件都必须满足,文档才会被返回。这通常会提高查询的精度,但可能会减少召回率 -
must:这个关键字用来指定文档必须匹配的条件。只有满足所有must条件的文档才会被包含在搜索结果中。这类似于逻辑运算中的AND操作。
-
filter:filter子句也是用来指定必须匹配的条件,但它不会对查询结果进行评分。这意味着filter子句执行起来通常比must快,因为Elasticsearch会缓存filter子句的结果。这使得filter非常适合用于处理那些与相关性评分无关的查询条件,如性别、年龄等。filter子句可以看作是优化过的must子句。
-
must_not:这个关键字用来指定文档必须不匹配的条件。任何满足must_not条件的文档都会被排除在搜索结果之外。这类似于逻辑运算中的NOT操作。
-
should:should关键字用来指定文档应该匹配的条件。这些条件是可选的,如果文档满足了should中的任何一个条件,它的相关性评分会增加。如果没有满足任何should条件,也不会对文档的评分产生影响。这类似于逻辑运算中的OR操作(一般不用)。
总的来说,must和filter都用于确保文档满足特定条件,但filter更高效;must_not用于排除不符合条件的文档;而should用于增加匹配文档的相关性评分。在实际使用中,这些关键字可以组合使用,以构建复杂的查询逻辑。
- term:用于精确匹配某个字段的值
- range:用于指定一个范围,并匹配该范围内的值。
- wildcard:用于进行模糊匹配,可以使用通配符来指定模式
- terms:用于精确匹配多个值
- prefix:匹配以什么开头
匹配name等于批量新增1并且age不等于3
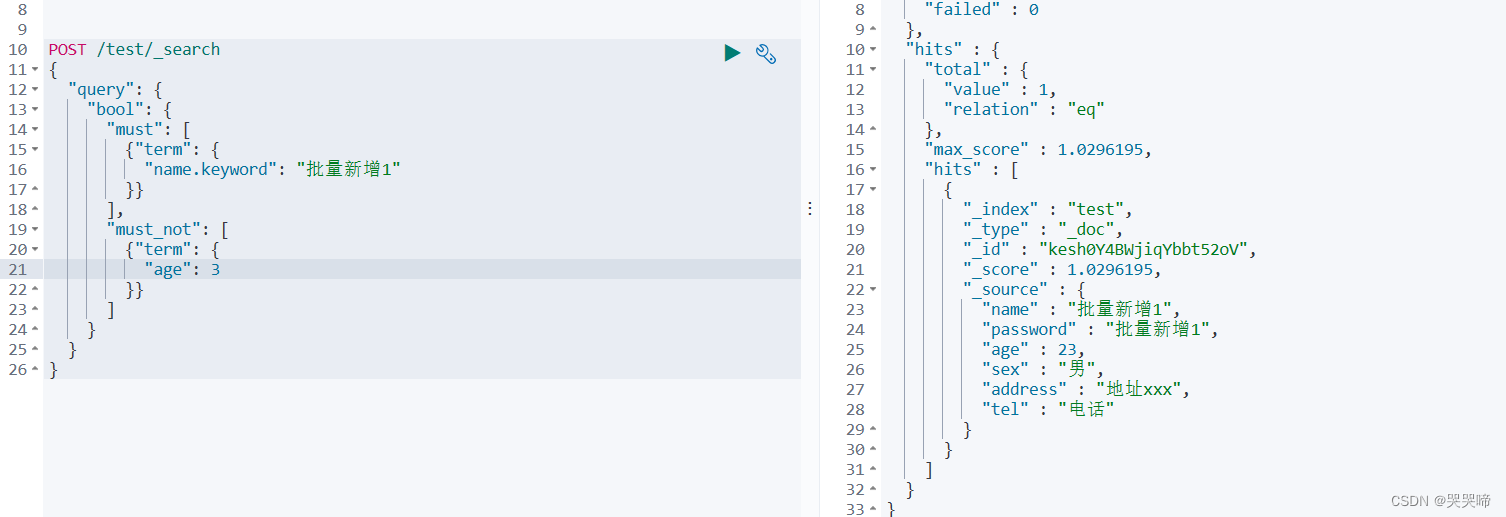
匹配name等于批量新增1和名字的数据
POST /test/_search
{
"query": {
"bool": {
"must": [
{"terms": {
"name.keyword": ["批量新增1","名字"]
}}
]
}
}
}
匹配name等于批量新增1和名字的数据并且不以名开头
POST /test/_search
{
"query": {
"bool": {
"must": [
{
"terms": {
"name.keyword": [
"批量新增1",
"名字"
]
}
}
],
"must_not": [
{"wildcard": {
"name": "名*"
}}
]
}
}
}
匹配name等于批量新增1和名字的数据并且不以名开头并且年龄在10-30之间
POST /test/_search
{
"query": {
"bool": {
"must": [
{
"terms": {
"name.keyword": [
"批量新增1",
"名字"
]
}
},
{
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
],
"must_not": [
{
"prefix": {
"name.keyword": "名"
}
}
]
}
}
}
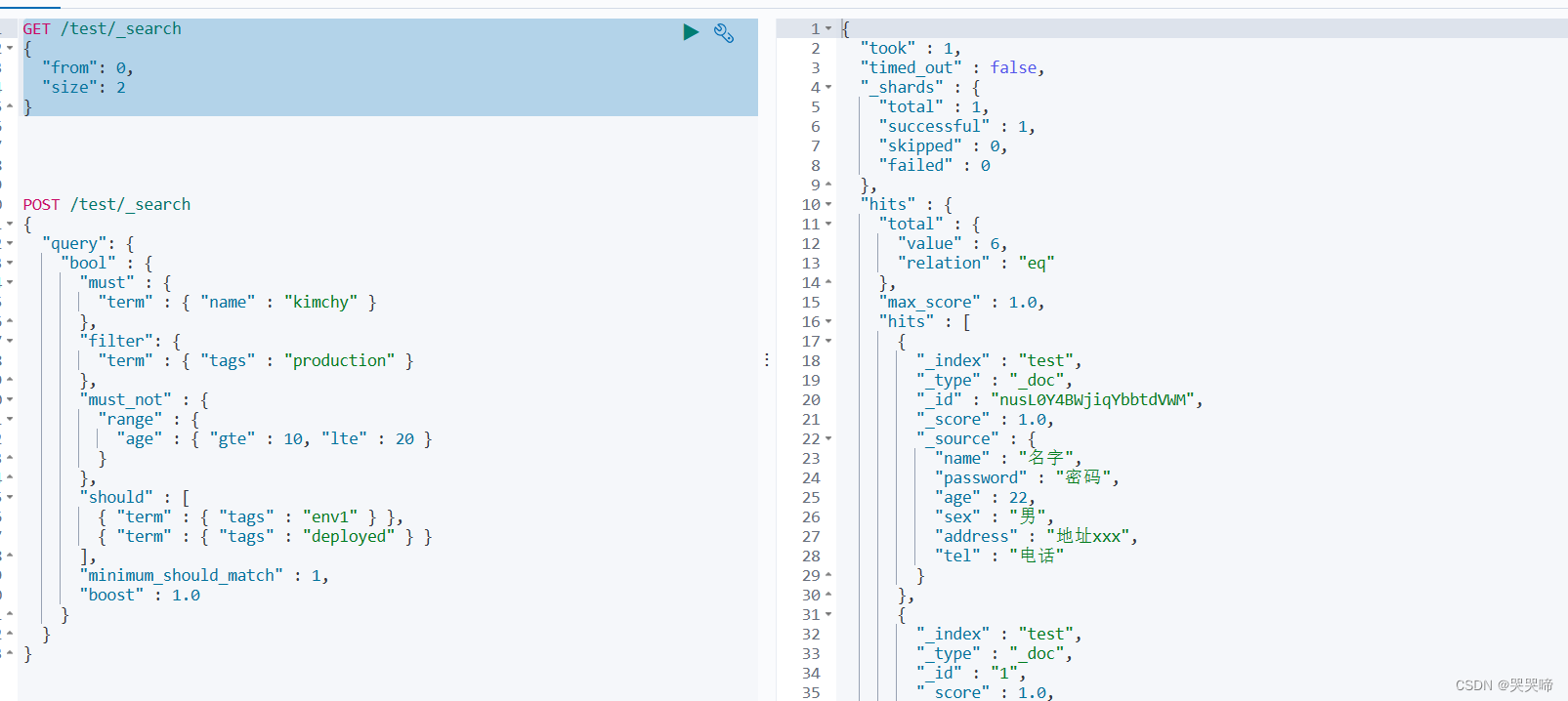
分页查询
from 当前页
size 每页展示多少数据
GET /test/_search
{
"from": 0,
"size": 2
}
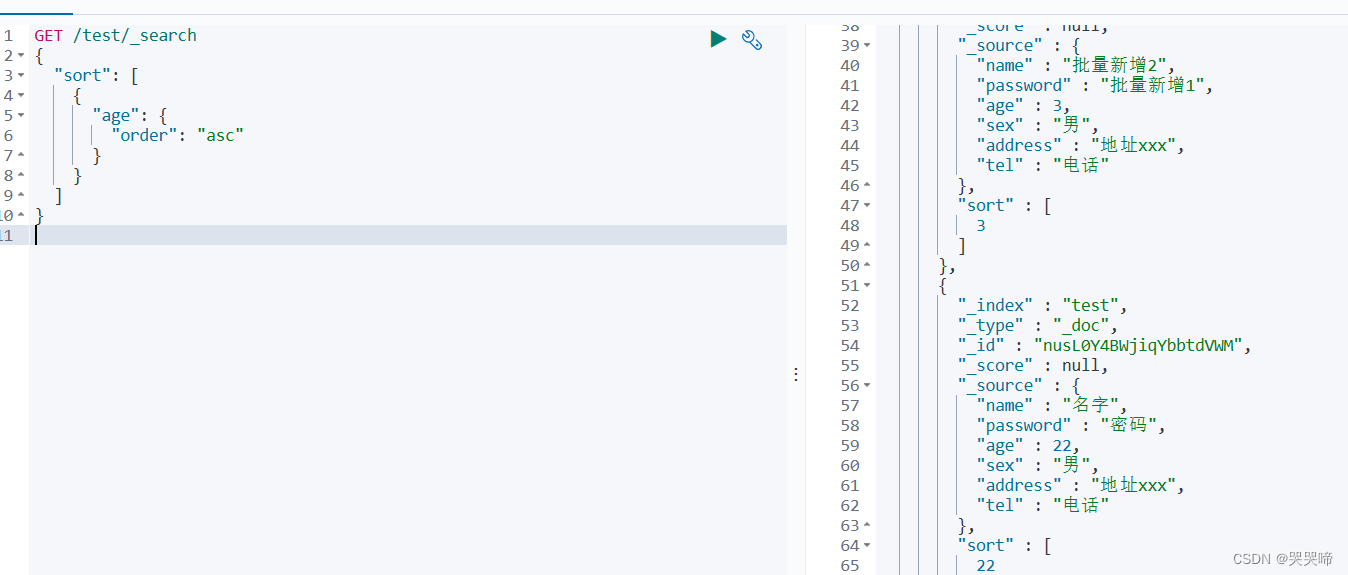
排序
升序
GET /test/_search
{
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
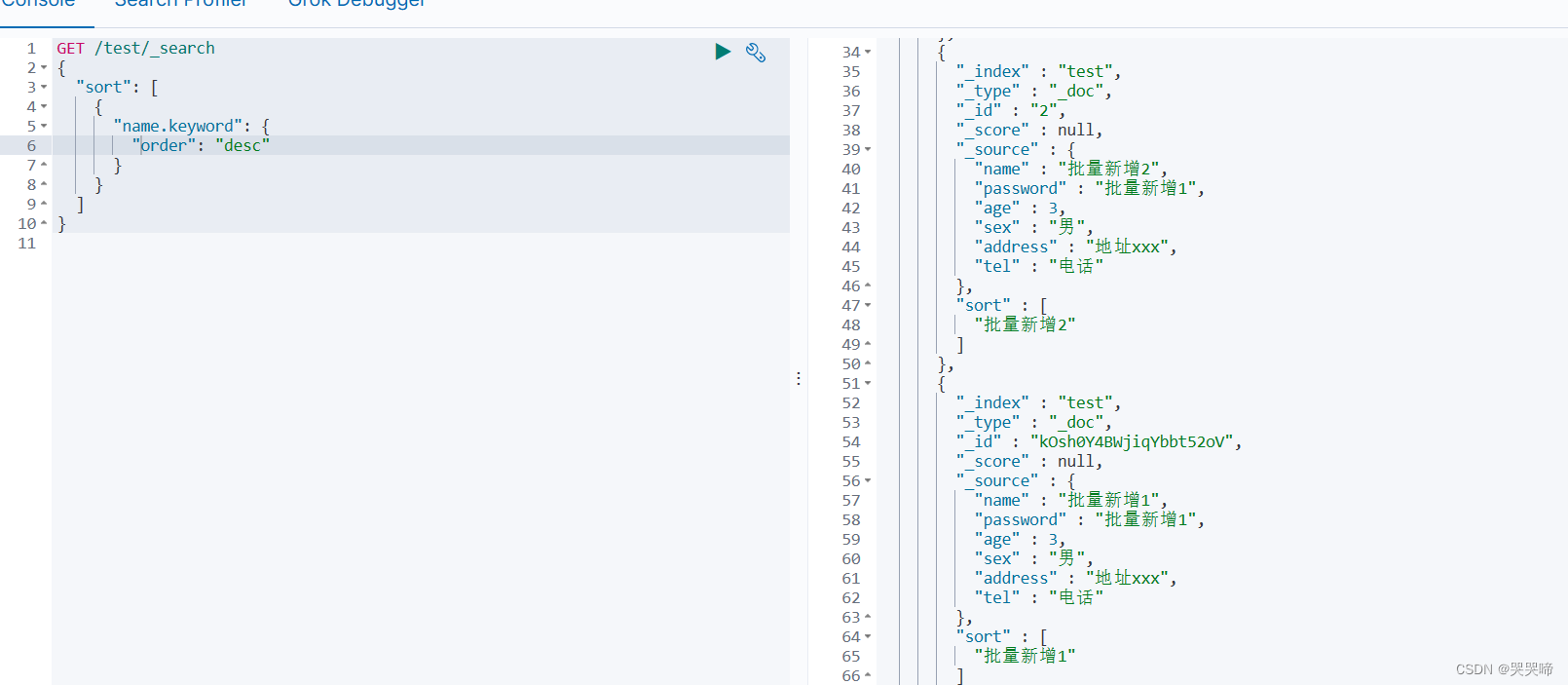
降序
GET /test/_search
{
"sort": [
{
"name.keyword": {
"order": "desc"
}
}
]
}
修改
根据id
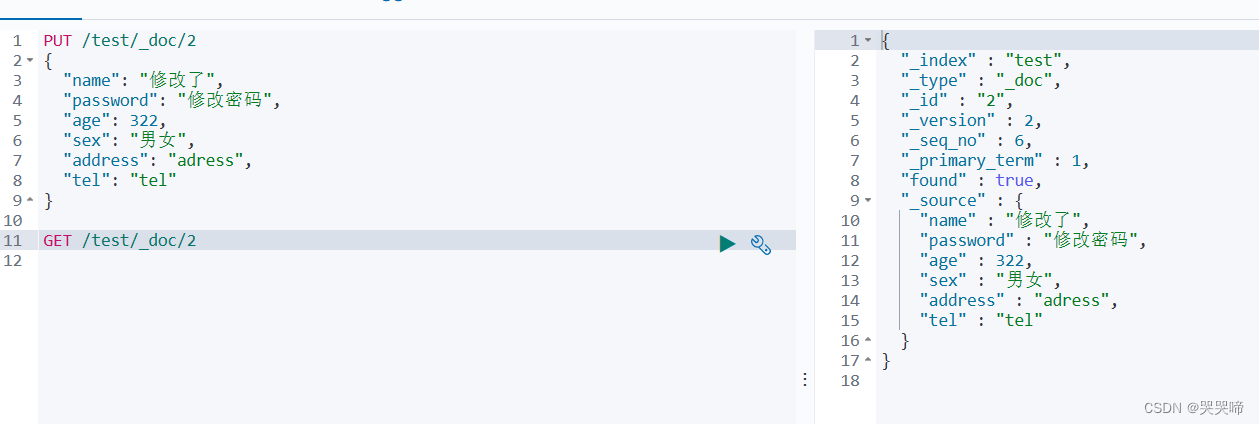
如果id存在则修改不存在就新增
PUT /test/_doc/2
{
"name": "修改了",
"password": "修改密码",
"age": 322,
"sex": "男女",
"address": "adress",
"tel": "tel"
}
根据查询条件修改
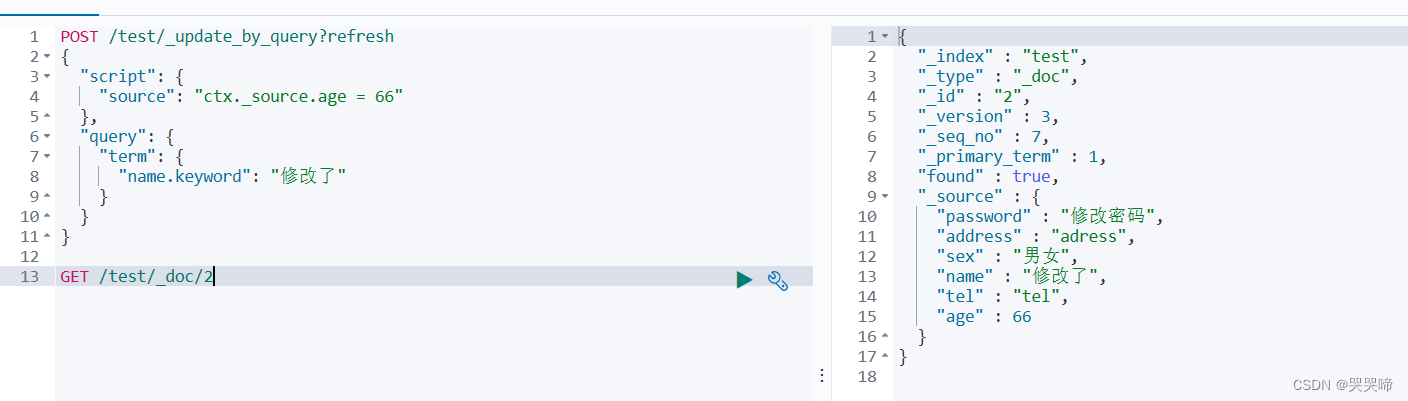
修改name = "修改了"的年龄为66
POST /test/_update_by_query?refresh
{
"script": {
"source": "ctx._source.age = 66"
},
"query": {
"term": {
"name.keyword": "修改了"
}
}
}
删除
和修改类似
根据id删除
DELETE /test/_doc/2

根据查询条件删除
先看有什么数据
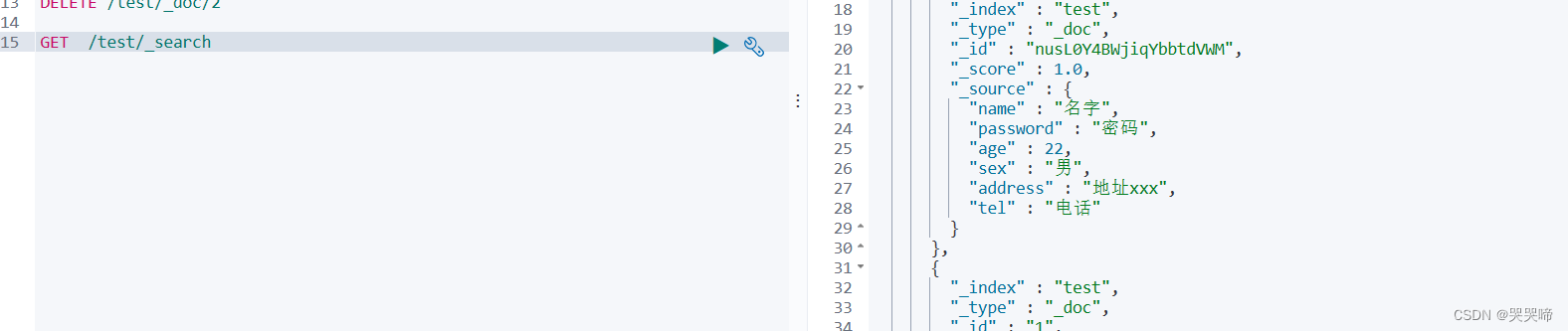
删除name="名字"的数据

删除index(所有数据,慎重)
DELETE /test















 7902
7902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









