







 本文探讨了C语言及其底层知识,包括代码编译过程、操作系统中的可执行文件格式、进程内存空间布局以及作用域规则。通过对PE文件、Linux内存空间、静态作用域和汇编层面的分析,阐述了C语言程序如何运行和内存管理的原理。此外,还提到了C语言与Java等类C语言在作用域和内存管理上的区别,并简要讨论了栈内存分配和ASLR地址空间随机化技术在安全防护中的应用。
本文探讨了C语言及其底层知识,包括代码编译过程、操作系统中的可执行文件格式、进程内存空间布局以及作用域规则。通过对PE文件、Linux内存空间、静态作用域和汇编层面的分析,阐述了C语言程序如何运行和内存管理的原理。此外,还提到了C语言与Java等类C语言在作用域和内存管理上的区别,并简要讨论了栈内存分配和ASLR地址空间随机化技术在安全防护中的应用。
写这篇文章的目的是对近期底层学习的总结,也算是勉励自己吧,毕竟是光靠兴趣苦逼自学不是自己专业的东西要承受很多压力。
要想深入理解C语言就不得不要知道几个知识点:
1.众所周知用任意一高级语言(不是脚本语言)写的代码都要经过类似:预处理->编译成汇编代码(compilation)->汇编(assembly)->连接(linking)这样的阶段。其中预处理产生.i文件,compilation产生.s文件,assembly产生.o文件,最后连接才会产生可执行文件,.o文件中不同机器上是不同的,而Java的能够“一次编译,到处运行“是因为Java不会像c那样在不同机器上产生不同的.o文件,而是用jvm虚拟机屏蔽了不同机器上的不同之处,于是只有不同的机子上都要Java的插件,一次编译后的文件就能到处运行。(可以想象的是为啥Android机的硬件配置往往要比iphone好,因为Android机正用了java的技术故中间多了一次转换过程当然效率要比用object-c编的iOS程序低,不过据说最近jvm采用了一些技术将效率提高了不小,不过这个我还没研究过就不说了)。
2.当你的代码被编译器编译成可执行文件(不一定是exe,这是个误区,以PE文件为例,这些格式其实是在PE文件头偏移量为0016h处的Characteristics字段表明的,如果是exe这一字段为0x0f01),不同的操作系统下的可执行文件是不同的,linux下为ELF,windows下为PE。由于我比较熟悉PE文件的格式,我就拿PE文件做个例子,你反汇编任意一个Windows的可执行文件你就会发现每个文件都被分成了很多个块,大致分成了.text,.idata,.rdata,.data,.rsrc块,这是为啥呢?这其实是为了方便程序映射到进程内存空间,因为为了方便管理和实现各种机制,进程的内存空间是分段的,在linux下一个进程的内存空间大致是这样:
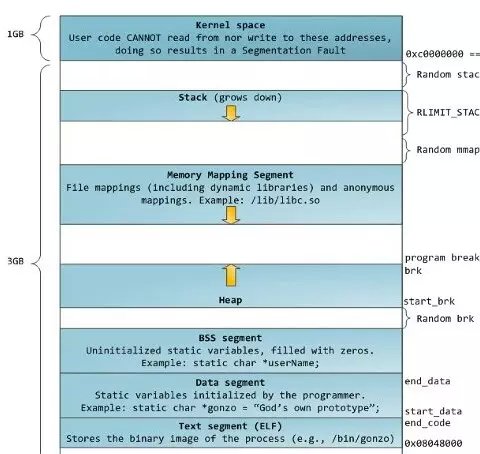
其中进程的用户态的线性地址空间是从0x00000000到0xbfffffff,也就是一般的应用程序跑的线性地址空间(内存中每一个字节的数据被赋予一个地址),注意这里是线性地址空间, 你反汇编左侧的地址空间是逻辑地址,

如上图左侧的是逻辑地址,(这些地址都是16进制),逻辑地址要经过分段机制才能指向线性地址,而线性地址要经过分页才能指向物理地址(物理地址才是内存条上),(有些操作系统没有分段机制,逻辑地址等于线性地址)。这其中的细节展开是一章的内容,我就不多说,有兴趣的可以看下linux内核方面的书籍,你要清楚你的程序要跑起来必定cpu要为你的程序分配内存(其实还有很多东西),跑起来后看情况你的程序会以一个进程或者线程的状态出现在操作系统上(进程的描述可不是简单的pid就能标识的,而是task_struct这个被称为进程描述符的东西同样这些东西要参考内核方面的书籍)。下图是windows可执行文件的映射(比较懒啊,直接把笔记弄上去了 ):
):

我想经过我这样一番描述你大致模糊的清楚一个程序在你电脑的存在和运行是啥情况了,下面我将分析语句了
静态作用域:
没错,这就是《编译原理》里的那部分内容,不过我加上了我的从底层上的一些见解即解释,什么是静态作用域呢?通俗的说就是你通过源代码就能判断一个声明的作用范围,在
这个范围内所有对该声明变量的使用都指向那个声明。c语言的(类c语言)作用域规则是基于程序结构的(块),也就是和你的“{ }”符号的使用有关,如下图:

最后一个cout<<a<<b打印的a的值为1,因为在一个块(也是一个作用域)内的语句会首先使用该块内的声明,如B3域内cout<<a<<b打印的a的值是3,如果该块内没有这个声明,则
找到其父块,如B3域内cout<<a<<b打印的b的值是2。其实,int a是一种声明,int a=1也是声明,而定义是在你声明过后类似于 a=1这种语句,其实定义可以看成是定值,而a这个东西
只是一个名字,名字和变量(内存位置也即不同的内存地址)的关系如图:

在不同域名字可以一样,但是因为其环境(作用域)不同其实它指向的内存位置是不同的,且你在定义之前必须声明,要不然它不清楚是对哪个内存位置进行赋值操作,如:B2域和B3域都有个int a =*的声明,其实它们分别指向不同的内存位置所以可以存不同的值。故定义(定值)所指向的变量(实际上是内存位置)是取决于作用域的声明的,即使是相同语句(名字)也会随环境变化而赋予不同变量值。又因为C语言在作用域内是按顺序执行语句的,也就有了这个例子
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









