






文章结构:
目录
GitHub文档加载器设计与实现
引言
GitHub文档加载器是一个用于从GitHub仓库加载文件和目录内容的工具。它允许应用程序直接访问GitHub仓库中的文档,将其封装为标准的Document对象,以便进一步处理和分析。
本工具主要适用于以下场景:
- 基于GitHub仓库构建知识库系统
- 从开源代码库提取文档进行分析
- 构建依赖于GitHub内容的RAG(检索增强生成)应用
架构设计
GitHub文档加载器由两个主要组件组成:GitHubDocumentLoader和相应的测试类GitHubDocumentLoaderTest。下面是系统的类图: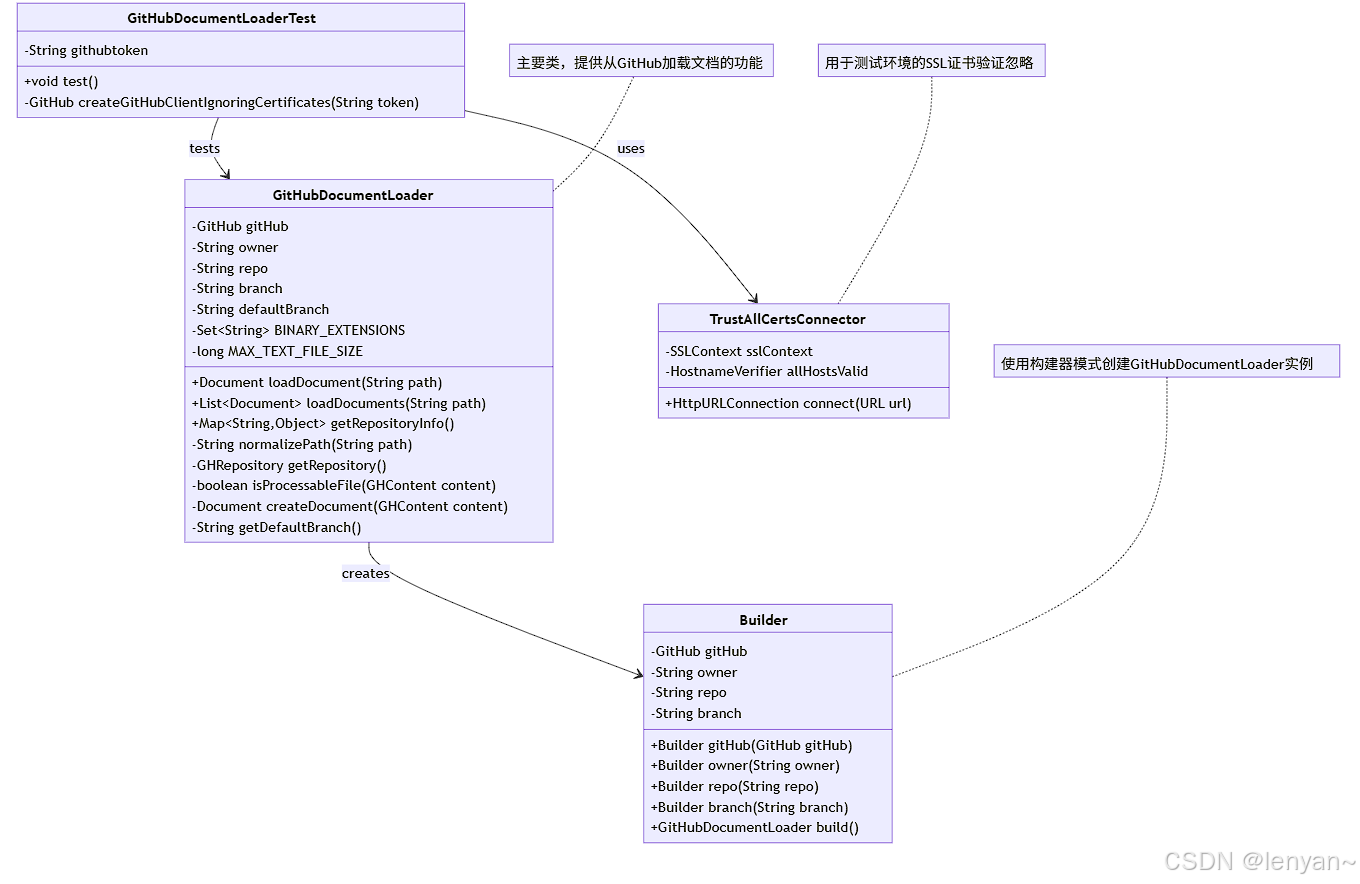
主要组件
- GitHubDocumentLoader:核心类,提供从GitHub仓库加载文档的功能
-
- 使用Builder模式创建实例
- 支持加载单个文件或整个目录
- 处理文件类型和大小限制
- 提供智能分支回退机制
- TrustAllCertsConnector:用于测试环境的自定义连接器
-
- 解决SSL证书验证问题
- 仅用于测试,不建议在生产环境使用
核心功能
文档加载流程
下面的时序图展示了从GitHub加载文档的过程:
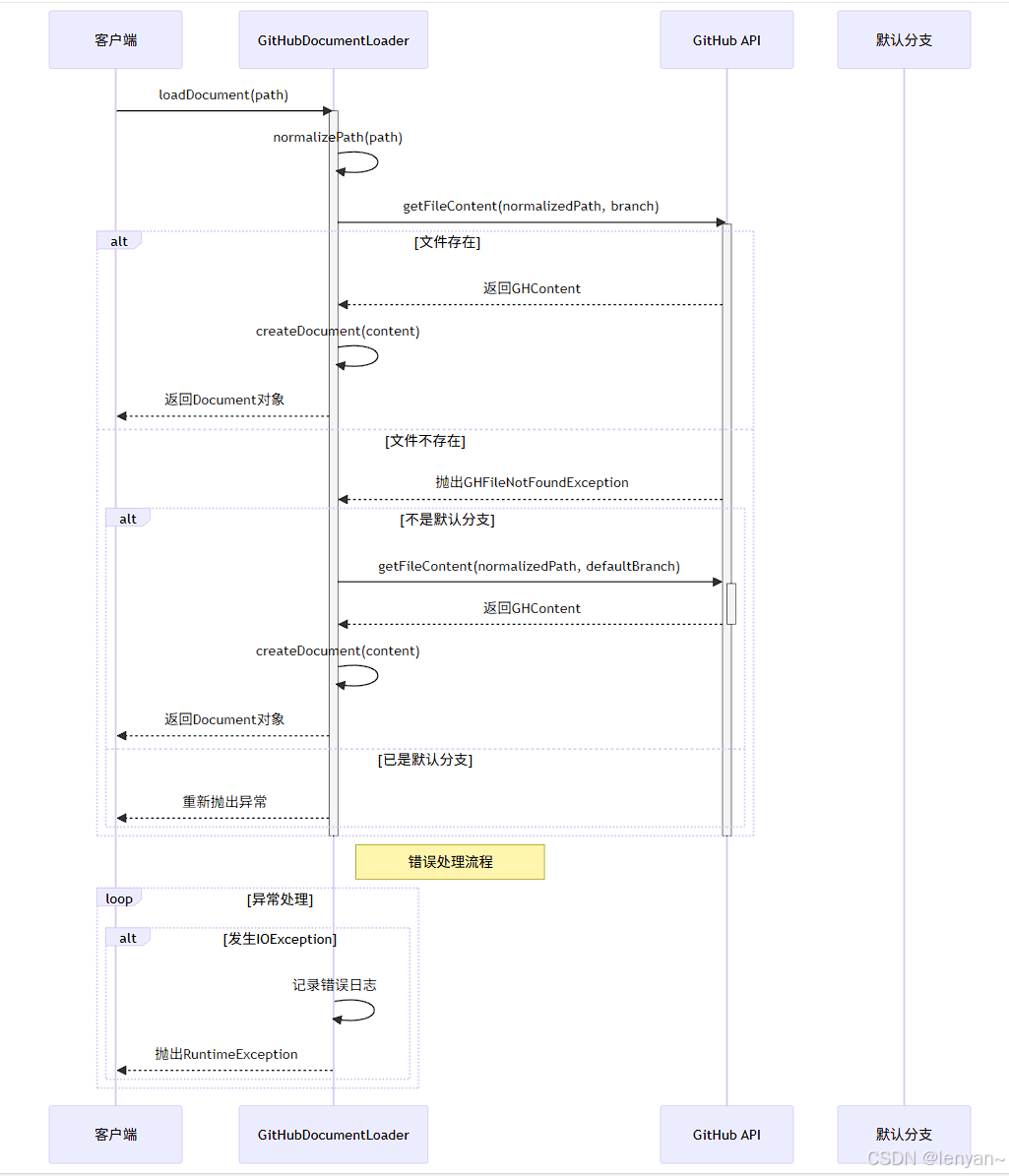
加载单个文件
loadDocument方法用于加载单个文件:
public Document loadDocument(String path) {
String normalizedPath = normalizePath(path);
try {
log.info("从GitHub加载文档: {}, 规范化路径: {}, 分支: {}", path, normalizedPath, branch);
try {
GHContent content = getRepository().getFileContent(normalizedPath, branch);
Assert.isTrue(content.isFile(), "路径必须指向文件");
return createDocument(content);
} catch (GHFileNotFoundException e) {
// 如果找不到指定分支的文件,尝试使用默认分支
String defaultBranch = getDefaultBranch();
if (!branch.equals(defaultBranch)) {
log.warn("在分支'{}'上找不到文件'{}', 尝试使用默认分支'{}'", branch, normalizedPath, defaultBranch);
GHContent content = getRepository().getFileContent(normalizedPath, defaultBranch);
Assert.isTrue(content.isFile(), "路径必须指向文件");
return createDocument(content);
} else {
throw e; // 如果已经是默认分支,则重新抛出异常
}
}
} catch (IOException e) {
log.error("从GitHub加载文档失败: {}, 规范化路径: {}, 分支: {}, 原因: {}",
path, normalizedPath, branch, e.getMessage());
throw new RuntimeException("从GitHub加载文档失败: " + path + ", 原因: " + e.getMessage(), e);
}
}加载目录内容
loadDocuments方法用于递归加载目录下的所有文件:
public List<Document> loadDocuments(String path) {
String normalizedPath = normalizePath(path);
List<Document> documents = new ArrayList<>();
try {
log.info("从GitHub加载目录内容: {}, 规范化路径: {}, 分支: {}", path, normalizedPath, branch);
List<GHContent> contents;
// 获取目录内容,支持分支回退
try {
if (normalizedPath.isEmpty()) {
contents = getRepository().getDirectoryContent("/", branch);
} else {
contents = getRepository().getDirectoryContent(normalizedPath, branch);
}
} catch (GHFileNotFoundException e) {
// 分支回退逻辑...
}
// 处理目录内容
for (GHContent content : contents) {
if (content.isFile()) {
try {
if (isProcessableFile(content)) {
documents.add(createDocument(content));
} else {
log.info("跳过二进制或大型文件: {}", content.getPath());
}
} catch (Exception e) {
log.warn("加载文件失败,跳过: {}, 原因: {}", content.getPath(), e.getMessage());
}
} else if (content.isDirectory()) {
documents.addAll(loadDocuments(content.getPath()));
}
}
} catch (IOException e) {
// 错误处理...
}
return documents;
}错误处理与健壮性
分支回退策略
GitHub文档加载器实现了智能分支回退机制,当指定分支找不到文件时,会自动尝试使用仓库的默认分支。下面是分支回退的流程图:
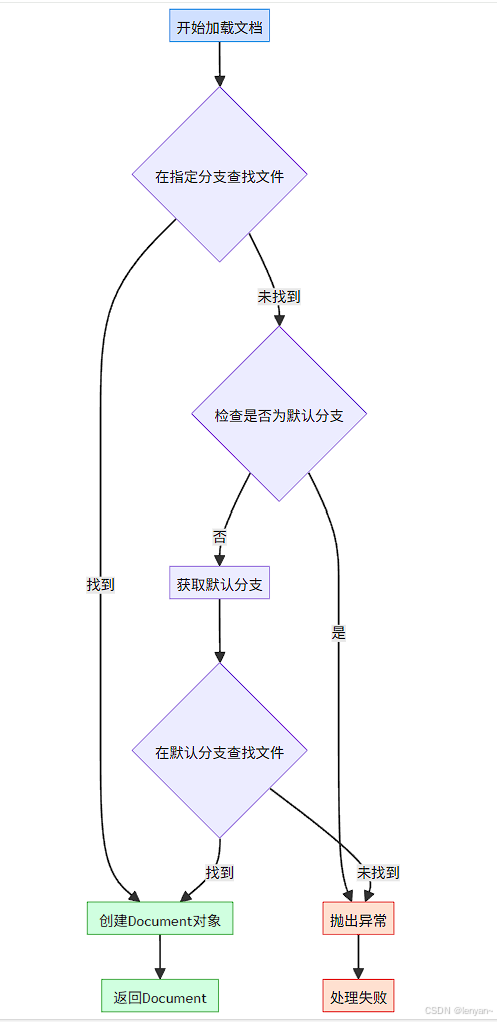
这种分支回退机制确保了代码在面对不同分支名称时的健壮性,特别是当仓库的默认分支名称从master变更为main等情况时。
文件类型和大小限制
为了避免处理不适合的文件,加载器实现了文件过滤机制:
private boolean isProcessableFile(GHContent content) {
// 检查文件大小
if (content.getSize() > MAX_TEXT_FILE_SIZE) {
return false;
}
// 检查文件扩展名
String fileName = content.getName().toLowerCase();
int dotIndex = fileName.lastIndexOf('.');
if (dotIndex > 0) {
String extension = fileName.substring(dotIndex + 1);
return !BINARY_EXTENSIONS.contains(extension);
}
// 没有扩展名的文件假定为文本文件
return true;
}这样可以避免处理二进制文件或过大的文件,提高系统的稳定性和性能。
安全性考虑
SSL证书验证
在测试环境中,我们通常会遇到SSL证书验证问题。GitHubDocumentLoaderTest类实现了一个TrustAllCertsConnector来绕过SSL证书验证:
private static class TrustAllCertsConnector implements HttpConnector {
private final SSLContext sslContext;
private final HostnameVerifier allHostsValid;
public TrustAllCertsConnector() {
try {
// 创建一个信任所有证书的TrustManager
TrustManager[] trustAllCerts = new TrustManager[]{
new X509TrustManager() {
public X509Certificate[] getAcceptedIssuers() {
return new X509Certificate[0];
}
public void checkClientTrusted(X509Certificate[] certs, String authType) {
}
public void checkServerTrusted(X509Certificate[] certs, String authType) {
}
}
};
// 创建一个信任所有证书的SSLContext
sslContext = SSLContext.getInstance("TLS");
sslContext.init(null, trustAllCerts, new SecureRandom());
// 创建一个接受所有主机名的HostnameVerifier
allHostsValid = new HostnameVerifier() {
public boolean verify(String hostname, SSLSession session) {
return true;
}
};
} catch (NoSuchAlgorithmException | KeyManagementException e) {
throw new RuntimeException("初始化TrustAllCertsConnector失败", e);
}
}
@Override
public HttpURLConnection connect(URL url) throws IOException {
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
if (connection instanceof HttpsURLConnection) {
HttpsURLConnection httpsConnection = (HttpsURLConnection) connection;
httpsConnection.setSSLSocketFactory(sslContext.getSocketFactory());
httpsConnection.setHostnameVerifier(allHostsValid);
}
return connection;
}
}重要安全提示:此方法仅适用于测试环境,不应在生产环境中使用,因为它会完全绕过SSL证书验证,从而使连接容易受到中间人攻击。
使用示例
基本使用
// 创建GitHub客户端
GitHub github = new GitHubBuilder().withOAuthToken(githubToken).build();
// 创建文档加载器
GitHubDocumentLoader loader = GitHubDocumentLoader.builder()
.gitHub(github)
.owner("username")
.repo("repository")
.branch("master")
.build();
// 加载单个文件
Document doc = loader.loadDocument("/README.md");
// 获取文档内容
String content = doc.getText();
// 加载目录下的所有文件
List<Document> docs = loader.loadDocuments("/docs");
// 获取仓库信息
Map<String, Object> repoInfo = loader.getRepositoryInfo();测试环境配置
在测试环境中,可以使用自定义的连接器来绕过SSL证书验证:
// 创建忽略SSL证书验证的GitHub客户端
GitHub github = createGitHubClientIgnoringCertificates(githubToken);
// 创建文档加载器
GitHubDocumentLoader loader = GitHubDocumentLoader.builder()
.gitHub(github)
.owner("username")
.repo("repository")
.branch("master")
.build();最佳实践
- 正确指定分支名称
-
- 确保使用仓库的正确分支名称
- 如果不确定,可以先获取仓库信息,查看
defaultBranch
- 处理大型仓库
-
- 对于大型仓库,避免一次性加载所有文件
- 使用特定的路径加载部分内容
- 错误处理
-
- 总是包装和处理可能的异常
- 使用分支回退机制提高代码健壮性
- 安全性考虑
-
- 在生产环境中正确处理SSL证书验证
- 不要在生产代码中使用
TrustAllCertsConnector
- 性能优化
-
- 缓存频繁访问的文档
- 限制递归深度以避免处理过多文件
结论
GitHub文档加载器是一个功能强大的工具,可以方便地从GitHub仓库中加载和处理文档。通过其智能分支回退机制和健壮的错误处理,它能够适应各种环境和场景。在实现自己的知识库系统或RAG应用时,可以充分利用这个工具从开源仓库中提取有价值的信息。
最后我叫 lenyan~ 也会持续学习更进 AI知识。让我们共进 AI 大时代。
作者:lenyan GitHub:lenyanjgk (lenyanjgk) · GitHub CSDN:lenyan~-CSDN博客
觉得有用的话可以点点赞 (/ω\),支持一下。
如果愿意的话关注一下。会对你有更多的帮助。
每周都会不定时更新哦 >人< 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









