









目录
nodejs模块系统简介
Node.js(简称Node)的模块系统非常灵活,除了提供内置的功能模块,还提供良好的扩展能力,使开发者可以编写多种多样的外置模块,这种扩展能力也极大丰富了Node的整个开发者生态。从总体上看,Node就是根植JavaScript语言并设计和实现了一系列库函数的集合,这些库函数根据问题域的不同划分到不同的模块中。因此,深入理解Node模块系统的工作原理对于理解Node的整体运行机制非常有帮助。本文立足于Node内置模块,剖析Node的模块体系以及工作原理。这对于理解外置的模块也同样具有借鉴意义。
Node的内置模块可以分成两类:C++版的native模块和JavaScript版的native模块(没错,Node内部对应的类名就叫做NativeModule),这里的native特指内置于libnode.so(Linux系统,下同)中的模块。这两类模块的组织结构不太相同,本文分别进行分析。
C++版native模块的定义和加载
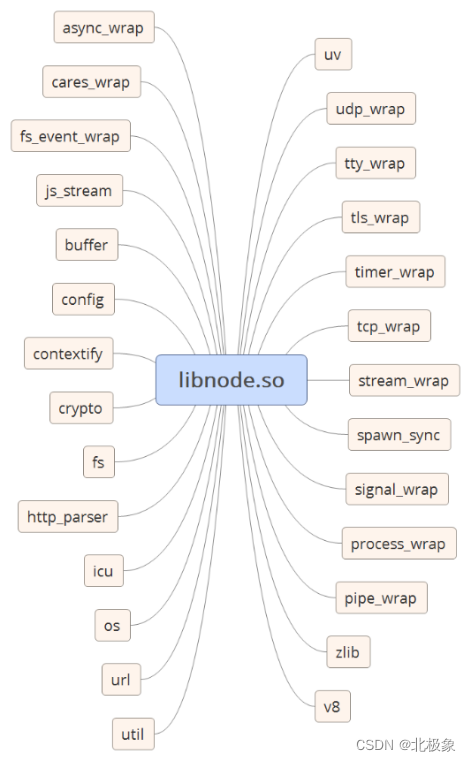
C++版native模块特指采用C++语言开发,内置在libnode.so中的子模块,一共有超过20个C++版的native模块(本节除非特殊说明,一律简称native模块),其编程模式与标准Node Addon的编程模式基本相同,只是没有生成独立的Addon文件,而是采用十分巧妙的方式,将这么多的native模块一起编译到libnode.so模块中。libnode.so充当容器,承载这些native模块,各个模块之间彼此隔离互不影响,并且独立加载,效果与独立的Addon文件几乎一样。因此我们也把这些native模块组成的体系称为Node的微模块系统(Micro native system),简图如下所示:
如何定义
可以参考标准的Node Addon的实现方法,基本代码结构是一致的。以最常用的fs模块为例,其主体代码如下:
// node_file.cc
static void Open(const FunctionCallbackInfo<Value>& args) {
...
int err = uv_fs_open(path, mode);
args.GetReturnValue().Set(err);
}
void InitFs(Local<Object> target, ...) {
Environment* env = Environment::GetCurrent(context);
env->SetMethod(target, "open", Open);
env->SetMethod(target, "read", Read);
...
}
NODE_MODULE_CONTEXT_AWARE_BUILTIN(fs, node::InitFs)
这与标准Node Addon的唯一区别是最后的宏,这里通过NODE_MODULE_CONTEXT_AWARE_BUILTIN这个宏将fs模块定义为Node的微模块系统的一部分。而源文件node_file.cc则通过node.gyp的编译脚本将其编译到libnode.so中。
为了理解Node的微模块系统,我们可以分析宏NODE_MODULE_CONTEXT_AWARE_BUILTIN的定义。从这个宏出发顺藤摸瓜,梳理清楚整个微模块系统的体系结构。这个宏的定义如下:
struct node_module {
int nm_version;
unsigned int nm_flags;
void* nm_dso_handle;
const char* nm_filename;
node::addon_register_func nm_register_func;
node::addon_context_register_func nm_context_register_func;
const char* nm_modname;
void* nm_priv;
struct node_module* nm_link;
};
#define NODE_MODULE_CONTEXT_AWARE_X(modname, regfunc, priv, flags) \ extern "C" { \ static node::node_module _module = \ { \ NODE_MODULE_VERSION, \ flags, \ NULL, \ __FILE__, \ NULL, \ (node::addon_context_register_func) (regfunc), \ NODE_STRINGIFY(modname), \ priv, \ NULL \ }; \ NODE_C_CTOR(_register_ ## modname) { \ node_module_register(&_module); \ } \ }
#define NODE_MODULE_CONTEXT_AWARE_BUILTIN(modname, regfunc) \ NODE_MODULE_CONTEXT_AWARE_X(modname, regfunc, NULL, NM_F_BUILTIN) \
从上述定义不难发现Node维护了一个全局的单向链表用于保存所有注册到微模块系统中的native模块。链表的节点类型是node_module,因此当我们调用NODE_MODULE_CONTEXT_AWARE_BUILTIN(fs, node::InitFs)时,会创建代表fs模块的node_module对象,并将成员变量nm_filename设置为"fs",将成员变量nm_context_register_func设置成fs模块的初始化函数InitFS。然后调用注册函数node_module_register()将该对象插入到全局链表的队首,注册代码如下所示:
// node.cc
static node_module* modlist_builtin;
extern "C" void node_module_register(void* m) {
struct node_module* mp = reinterpret_cast<struct node_module*>(m);
mp->nm_link = modlist_builtin;
modlist_builtin = mp;
}
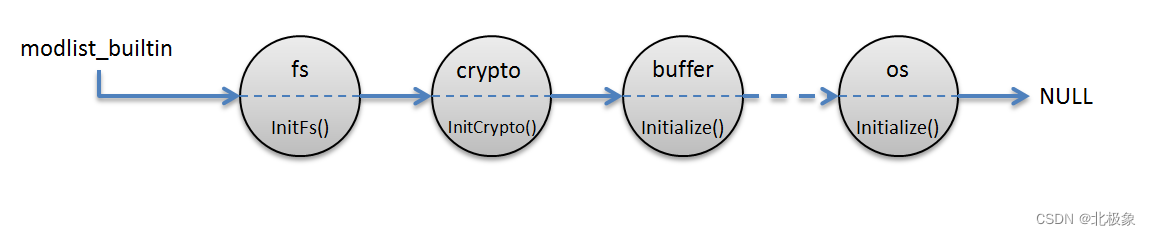
这里的全局静态变量modlist_builtin就是链表的首节点,通过这个变量可以遍历所有注册到微模块系统中的native模块。所有native模块在源文件的最后全都调用宏NODE_MODULE_CONTEXT_AWARE_BUILTIN完成注册工作。
特别指出native模块的注册时机,通过上面的代码分析发现,Node通过宏NODE_C_CTOR将注册函数声明为constructor类型的函数,这意味着该注册函数在libnode.so加载阶段被自动调用。这样可以保证所有native模块都可以在启动阶段完成自动注册。以fs为例,注册相关的宏展开后的完整代码如下:
// 属性constructor可以确保_register_fs()在libnode.so加载阶段被调用。
void _register_fs() attribute((constructor));
void _register_fs() {
node_module_register(&fsMod);
}
通过以上技术手段,当libnode.so模块加载完成之后,所有的native模块全部串联起来,并保存到modlist_builtin链表中。整个链表的结构如下图所示:
加载过程
Native模块的注册只是告诉Node存在这样一个native模块,而并没有真正加载该native模块。真正的加载native模块必须要调用注册时传入的初始化函数(比如fs的InitFS函数)。理解注册和加载的区别十分重要,这样才能弄清楚Node内部如何使用native模块。那么究竟何时真正加载native模块呢?
Node采用”懒加载“的策略:只有在第一次使用某个模块时(通过调用require方法),才真正加载对应的模块,这时才正式调用初始化函数。以fs模块为例,在客户第一次调用require(‘fs’)时,才会执行注册的初始化函数,完成该native模块的加载。
下面以fs模块为例剖析require(‘fs’)的整个过程,讲解Node如何加载native模块,并把功能开放到JavaScript的世界的。
JavaScript接口层
大部分C++版native模块都有对应的JavaScript接口层(也就是下一节介绍的JavaScript版native模块),接口层是对native模块的简单封装。以fs模块为例,当开发者调用require(‘fs’)时,首先会加载名称为"fs.js"的接口文件,后者会利用binding的机制访问对应的C++版native模块。代码示例如下:
// fs.js
const binding = process.binding('fs');
exports.open = function(path, flags, mode, callback_) {
...
binding.open(path, flags, mode, req);
};
fs.js是典型的JavaScript版native模块,通过exports变量对外开放接口,而接口的实现则代理给对应的C++版native模块。其中最关键的一步是如何绑定这两种native模块,这个功能则由万能的process.binding()工具方法实现。
万能的binding机制
Binding机制实现在全局对象process的binding函数中,其主要功能是根据JavaScript模块名查询C++版native模块对象,并把后者通过exports机制开放给JavaScript世界,实现"绑定"目的。
为了做到C++版native模块的懒加载,binding方法采用了cache机制,在cache中保存所有已加载的C++版native模块的接口对象。具体做法是在每次调用"绑定"函数时根据JavaScript模块名优先从cache中查找,如果找到则直接返回缓存的接口对象,如果没有找到,则遍历微模块系统的modlist_builtin链表,找到已经注册了的native模块对象,然后调用初始化函数nm_context_register_func。完成正式的加载工作。最后把native模块的接口对象保存到cache中并将其返回出来。主要代码如下所示:
// node.cc
// process.binding()会调用到该函数。
static void Binding(const FunctionCallbackInfo<Value>& args) {
Environment* env = Environment::GetCurrent(args);
Local<String> module = args[0]->ToString(env->isolate()); // 模块名
node::Utf8Value module_v(env->isolate(), module);
Local<Object> cache = env->binding_cache_object();
// 从cache中查找接口对象,如果找到,直接返回
Local<Object> exports;
if (cache->Has(env->context(), module).FromJust()) {
exports = cache->Get(module)->ToObject(env->isolate());
args.GetReturnValue().Set(exports);
return;
}
// cache没有则从modlist_builtin链表中查找
node_module* mod = get_builtin_module(*module_v);
if (mod != nullptr) {
// 找到内置Native模块,调用初始化函数,完成模块加载
exports = Object::New(env->isolate());
Local<Value> unused = Undefined(env->isolate());
mod->nm_context_register_func(exports, unused, env->context(), mod->nm_priv);
// 把接口对象加入cache中,下次再"绑定"时可以直接返回
cache->Set(module, exports);
}
// 返回接口对象
args.GetReturnValue().Set(exports);
}
JavaScript版native模块的定义和加载
上一节介绍的native模块特指用C++编写的模块。在Node中,除了C++编写的native模块,还有一种是用JavaScript编写的native模块。无论哪种语言编写的native模块,除了编程语言的差别,本质没有太大的区别,首先两者都是Node原生(builtin)模块库的一部分,其次都采用了懒加载的机制。而编程语言上的差异主要表现在两个方面:1),在模块的组织上,C++版的native模块以全局单向链表的形式将模块保存在Node的微模块系统中。而JavaScript版的native模块则相对简单的多,直接把native模块保存在JavaScript的map结构中,map中每个元素的key为模块的ID,也是调用者调用require函数时传入的参数(比如fs,console,vm等),而value则是具体的JavaScript版native模块对象。2),在层次结构上,JavaScript版native模块充当接口层,而C++版native模块则为实现层,前者是后者的封装,负责把用户的调用意图传递给后者。后者则调用操作系统的功能,完成具体的功能实现。
JavaScript版native模块之所以称为native模块,主要原因是这些模块都会在Node的编译阶段借助工具将JavaScript的源码转换成C++字符串,并直接编译到libnode.so中。这个过程称为JavaScript版native模块的打包,借助的技术被称为js2c。打包到libnode.so中的好处是,当用户调用require请求某个JavaScript版native模块时,不需要再从外部文件读入具体的JavaScript源码,而是直接从内存中(libnode.so中)载入经过转换的C++字符串形式的JavaScript源码,然后再进行即时编译和执行。在加载效率上明显提高很多。此外在转换阶段还可以将所有JavaScript源码做合并及混淆处理,这在效率和安全性方面都有一定的好处。
接下来首先介绍精巧的转换技术:js2c。
js2c技术
当你打开Node的源文件"node_javascript.cc"时,可能会发现这个文件包含了一个神秘的头文件"node_natives.h",并使用了其中的全局变量"natives",但你翻遍整个代码库也找不到这个头文件和这个全局变量。带着疑惑进一步扩大搜索范围,终于在"node.gyp"文件中找到了线索,关键的几处代码如下:
// node.gyp
{
'target_name': 'node_js2c',
'actions': [{
'action_name': 'node_js2c',
'inputs': [
'<@(library_files)',
'./config.gypi',
],
'outputs': [
'<(SHARED_INTERMEDIATE_DIR)/node_natives.h',
],
'action': [
'<(python)',
'tools/js2c.py',
'<@(_outputs)',
'<@(_inputs)',
]}}
这段编译脚本的意思是调用"tools/js2c.py"工具,将"@(library_files)“指示的所有JavaScript文件合并及转换成C++的头文件,转换之后的C++头文件名称是"node_natives.h”。注意这里说的转换不是编译,仅仅是简单的"搬运":将JavaScript的源文件内容"搬运"到C++的头文件"node_natives.h"中,JavaScript源码作为C++字符串的形式保存在全局变量"natives"数组中。进一步研究"js2c.py"的实现,可以分析出"node_natives.h"的完整定义,关键代码示例如下:
// node_natives.h
namespace node {
struct _native {
const char* name;
const char* source;
size_t source_len;
};
static const struct _native natives[] = {
{"assert", "<content-of-assert.js", sizeof(<content-of-assert.js>), // assert module
{"fs", "<content-of-fs.js>", sizeof(<content-of-fs.js>), // fs module
...
{ NULL, NULL, 0 }
};
natives数组以"{NULL, NULL, 0}“结尾,方便数组的遍历,其元素类型是”_native"结构体,由三部分组成:“name"表示该模块的ID,调用者在调用require时传入的参数需要和name的值一致,所以在加载这类native模块时只需要传入模块名即可,在模块名之后加上”.js"的后缀反而是错误的,比如"require(‘fs.js’)"是错误的。"source"则是原始JavaScript转换成C++字符串之后的内容。"source_len"表示具体内容的大小。
借助js2c工具,lib目录下的几乎所有的JavaScript文件全部打包到libnode.so中。具体哪些文件被打包可以参考node.gyp中"library_files"的定义。
NativeModule的工作原理
这里直接引用Node内部类名NativeModule特指JavaScript版native模块。
与C++版native模块类似,JavaScript版native模块的加载也遵循两个原则: 1),在Node启动阶段将所有的NativeModule对象缓存到map中,建立模块名到JavaScript代码的映射,但不真正加载模块。2),采用“懒加载”机制,只有当用户调用"require"请求指定模块时才到map中查找到NativeModule对象并执行真正编译工作,完成加载。以下分别阐述这两个阶段。
Node启动时构造NativeModule对象,完成name到source的映射
Node的JavaScript世界的初始化代码实现在"node.js"文件中,并在Node启动阶段执行。该文件定义了"NativeModule"类用以表示JavaScript版native模块的信息,其定义如下:
// node.js
function NativeModule(id) {
this.filename = id + '.js';
this.id = id; // 没有js后缀
this.exports = {};
this.loaded = false;
}
注意其成员变量exports是导出的接口对象,其初始值为空。在Node初始化阶段借助binding机制,载入js2c阶段生成的"natives"对象,保存到NativeModule的类变量_source中,关键代码如下:
NativeModule._source = process.binding(‘natives’);
该调用返回的是map对象,其中key是模块的name,而value是具体的JavaScript源码。具体的实现在node_javascript.cc文件中,关键代码如下:
// node_javascript.cc
#include "node_natives.h"
void DefineJavaScript(Environment* env, Local<Object> target) {
...
for (int i = 0; natives[i].name; i++) {
...
Local<String> name = String::NewFromUtf8(env->isolate(), natives[i].name);
Local<String> source = String::NewFromUtf8(env->isolate(), natives[i].source,String::kNormalString,natives[i].source_len);
target->Set(name, source);
}
}
总而言之,在Node启动结束时,所有的JavaScript版native模块的源码都缓存在"NativeModule._source"这个map中,而在require指定模块之前,NativeModule.exports均为空(表示它们全都没有真正加载)。
懒加载机制
如上所述,Node的native模块不论C++版还是JavaScript版都采用懒加载机制:只有在调用require时才会真正加载指定的模块。具体的说,对于JavaScript版native模块而言,加载的含义是编译并执行JavaScript源码。完整的加载过程定义在NativeModule的require函数中,简单解释如下:
NativeModule.require = function(id) {
...
// 首先从缓存中查找是非存在exports对象,如果有则直接返回
var cached = NativeModule.getCached(id);
if (cached) {
return cached.exports;
}
// 如果require的模块名称不在NativeModule到map对象中,则抛异常
if (!NativeModule.exists(id)) {
throw new Error('No such native module ' + id);
}
process.moduleLoadList.push('NativeModule ' + id);
// 懒加载开始
var nativeModule = new NativeModule(id);
nativeModule.cache();
// 关键的一环节:编译
nativeModule.compile();
return nativeModule.exports;
};
关键代码在compile函数中:
NativeModule.prototype.compile = function() {
var source = NativeModule.getSource(this.id);
source = NativeModule.wrap(source);
var fn = runInThisContext(source, {
filename: this.filename,
lineOffset: 0,
displayErrors: true
});
fn(this.exports, NativeModule.require, this, this.filename);
this.loaded = true;
};
在compile函数中,首先根据id从NativeModule._source中读取对应模块的源码。然后按照Node的标准做法对模块的源码进行包装,举例说明,如果模块的原始内容是:
exports.foo = function() {
return 'Hello World';
};
那么包装之后的内容变换成:
(function (exports, require, module, __filename, __dirname) {
exports.foo = function() {
return 'Hello World';
};
});
包装之后立即调用"runInThisContext"函数,该函数借助V8引擎,即时对包装后的源码进行编译和执行,执行后返回的结果是一个function对象(即上述的包装函数)。最后调用该函数,传入正确的参数列表,这些参数也正是我们编写JavaScript模块时可以直接引用到变量(比如exports等),通常模块内部实现会把需要开放的对象或函数挂在"exports"对象(又称接口对象)上。这样外面调用者就可以直接调用exports下面的变量或函数。这也正是JavaScript模块开放接口的工作原理。
总结
本文重点介绍了Node的内置模块的组织结构以及加载机制。Node的内置模块分成C++版native模块和JavaScript版native模块,实现机制上有一定的区别。因此将两种模块分开介绍和剖析,希望对读者深入理解Node的模块机制有所帮助。而开发者在利用Node的扩展机制开发外置模块时也可以内置模块的原理和机制。
















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











