







“不要和我竞争大模型,请用文心一言和别人竞争。“ ——李彦宏
文章目录
前言
2016年是人工智能的元年。2023年是大模型的元年。谁能抢占风口浪尖,谁就能脱颖而出。
chatGPT,文心一言4.0、腾讯混元、通义千问、MiniMax、智谱AI、迅飞星火,群魔乱舞。
文本:ChatGPT, kimi,通义千问,天工
图片:midjourney,leonardo,魔塔社区,天工,Alchemy、PhotoReal,Canva.cn
音乐:Suno, Stable Audio, 天工(真正意义上),文心一言(洛天依),小爱同学
搜索编程:Github Copilot,CodeGeek,天工,kimi
视频生成:Sora, Stable Video Diffusion, Runway, Pika, Haiper, Vidu
数字人:HeyGen,D-iD,SadTalker,文心一言,阿里EMO
国内外主要大模型盘点

几个主要的开源大模型
- 谷歌的Gemma,2B和7B两种规模,并且采用了与Gemini相同的研究和技术构建。历史上,Transformers、TensorFlow、BERT、T5、JAX、AlphaFold和AlphaCode,都是谷歌为开源社区贡献的创新
- Meta的开源大语言模型Llama3
- Qwen1.5-110B
- Alpaca
- Databricks Dolly2.0
- Hugging Face:BLOOM
- MiniGPT4
- Stability AIStableLM
- 元语智能ChatYuan,首个中文开源对话模型
大模型产业
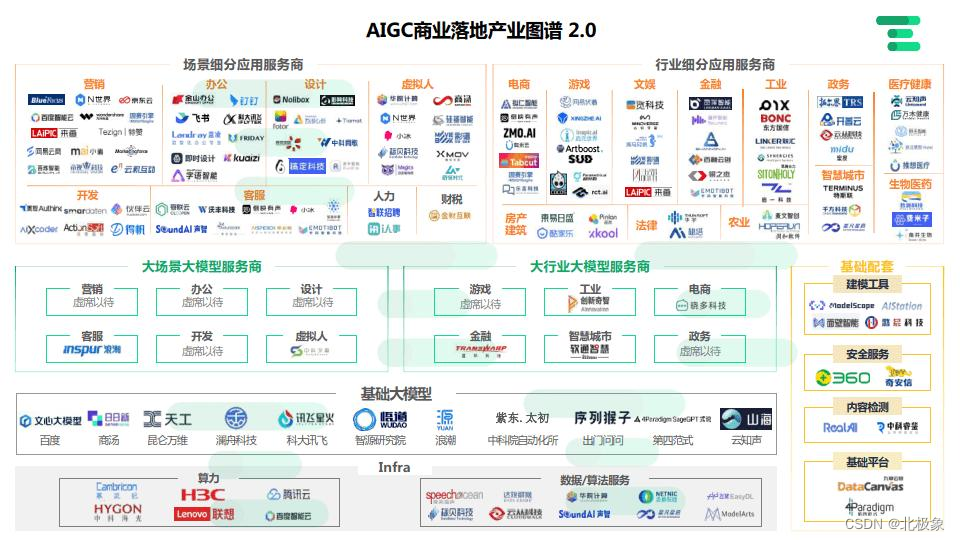
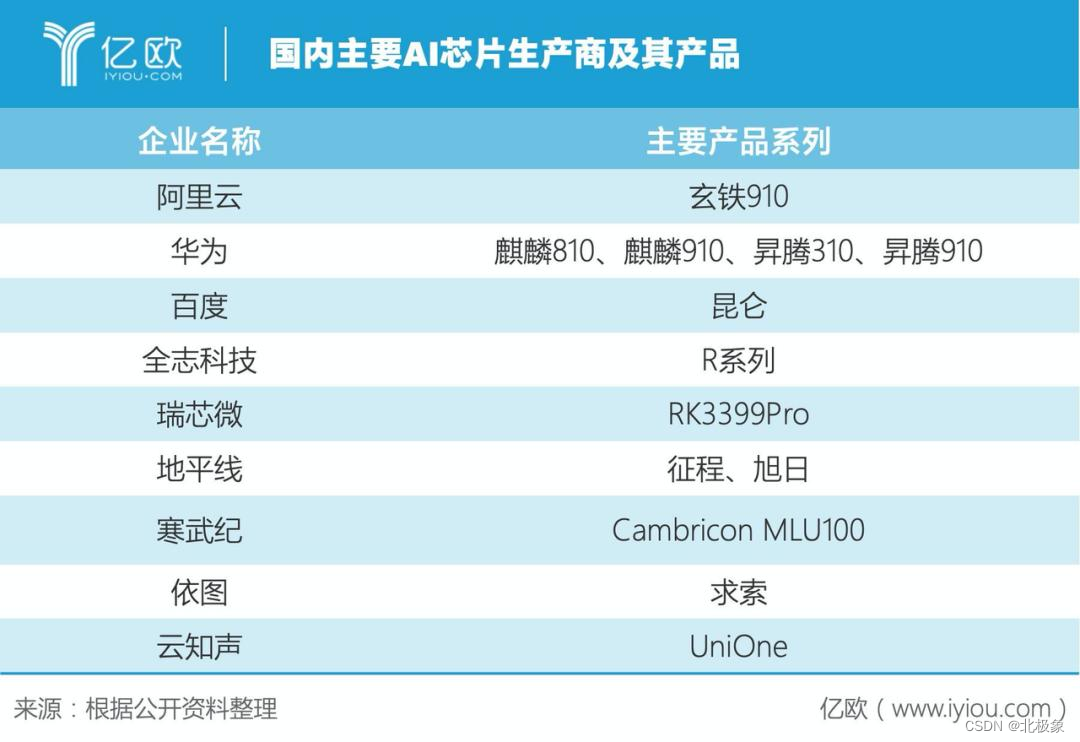
AI编程工具
- GitHub Copilot:由 GitHub 联合 OpenAI 和微软 Azure 团队推出,支持多种语言和 IDE,能快速提供代码建议。
- ChatGPT:ChatGPT对你的工作效率来说可能是一个真正的改变者。例如,它可以提供有用的示例,比如建议一个用于测试的数组或帮助重构代码片段。
- 通义灵码:阿里巴巴团队推出,提供多种编程辅助能力。
- CodeWhisperer:亚马逊 AWS 团队推出,由机器学习技术驱动,可实时提供代码建议。
- CodeGeeX:智谱 AI 推出的开源免费 AI 编程助手,基于 130 亿参数的预训练大模型。
- Cody:Sourcegraph 推出的 AI 代码编写助手,借助强大的代码语义索引和分析能力。
- CodeFuse:蚂蚁集团支付宝团队为国内开发者提供的免费 AI 代码助手。
- Codeium:一个由 AI 驱动的编程助手工具,提供代码建议、重构提示和代码解释。
- TabNine:是一款基于人工智能的代码编辑器自动补全扩展。它通过使用机器学习模型来预测和建议整行或代码块,超越了传统的自动补全功能。用户可以选择免费使用TabNine,但会有一些限制,或者选择订阅Pro版本以获得高级功能。
AI 作画

- MidJourney是一款AI创作图片的工具, 它根据Discord里的描述词,生成精美、创意十足的图片。
- 腾讯的AIDesign自动生成Logo: https://ailogo.qq.com/guide/brandname
- https://github.com/Raadsl/Logo-generator
- https://www.namecheap.com/logo-maker/app/editor
- https://github.com/Slfdspln/Logo-Maker
视频生成

AI生成网站
国外 AI 生成网站,分别是 OpenAI的ChatGPT Playground、ArtBreeder、Jukedeck 和 TalkToTransformer,同时还有一款国内 AI 生成网站「即时灵感」。
AI 创作音乐

AI 写诗
AI 写小说
古文创作
古文相关的NLP任务主要为:
- 古诗分类
- 古文翻译为现代文
- 古文生成,将现代文转成古文
- 对联和古诗、词生成
古文AI写作工具”,【搭画智写】是一款基于AI技术的古文写作工具,可以生成高质量的古文文案和古风小说。
本文所介绍的古文GPT-2模型由国内研究者采用UER开源框架训练而成,训练语料为殆知阁古代文献2.0版语料库,近33亿字。由于该库中75%文本均未标点,研究者采用北京师范大学古诗文断句系统对其进行自动标点,得到了近300万段文本作为训练语料。更多信息,可参考如下链接或论文。
预训练模型有:siku-bert、siku-roberta和bert-ancient-chinese
AI出题和解题
- mathAI
- Codex
- AI狂读arXiv上200万篇论文。
新模型Minerva,基于Pathway架构下的通用语言模型PaLM改造而来。分别在80亿、600亿和5400亿参数PaLM模型的基础上做进一步训练。Minerva做题与Codex的思路完全不同。Codex的方法是把每道数学题改写成编程题,再靠写代码来解决。而Minerva则是狂读论文,硬生生按理解自然语言的方式去理解数学符号。在PaLM的基础上继续训练,新增的数据集有三部分:主要有arXiv上收集的200万篇学术论文,60GB带LaTeX公式的网页,以及一小部分在PaLM训练阶段就用到过的文本。
附录
大模型相关链接
AI编程链接
- codegeex
- gpt-engineer
- https://www.kite.com/
- https://github.com/THUDM/CodeGeeX2
- https://www.shecodes.io/
- GitHub Copilot的开源版本
AI作画
AI出题
古文创作链接
- GPT2-Chinese
- 古文BERT: 古文预训练语言模型
- 古文生成专属入口
- 对联生成专属入口
- 古诗词生成专属入口
- UER框架
- 北师大古诗文断句标点工具
- 小鱼AI写作
- Bert-ancient-chinese模型
- 6.Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
- 7.Zhao Z, Chen H, Zhang J, et al. UER: An Open-Source Toolkit for Pre-training Models[J]. EMNLP 2019, 2019: 241.
- 8.胡韧奋,李绅,诸雨辰.基于深层语言模型的古汉语知识表示及自动断句研究[C].第十八届中国计算语言学大会(CCL 2019).



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











