






python中文编码问题深入分析(一):字符编码基础
背景:笔者作为一名刚接触python语言的新手,在实际的项目中,遇到过一些中文编码问题,初次遇到这些问题的时候,刚开始显得有些手足无措,也不知从何查起。常言道:有问题,找度娘!当我打开www.baidu.com后,并键入遇到的问题时,才发现这个问题非常泛滥,几乎可以用霸屏来形容(心中窃喜,终于有救了),但是关于python中文编码问题产生的原因和解决方法的描述可谓百花齐放,不够系统和彻底,顿觉空欢喜一场。因此,笔者写下这篇文章,深入分析一下python中文编码问题,第一是想自己与中文编码问题来个了断,提高自己,以后遇到同样的问题,就来查看这篇文档;二来希望能帮助到那些正在身陷python编码囹圄,不可自拔的人士。由于笔者水平有限,文中不免出现错误,希望各位大神不吝指正。
这篇文章主要简要介绍一下字符编码的一些基本知识和python字符编码的基础概念,便于后续章节的展开和论述。
1.字符编码简介
该部分字符编码的介绍主要转自http://www.cnblogs.com/huxi/archive/2010/12/05/1897271.html。
1.1 ASCII编码
ASCII(American Standard Code for Information Interchange),是一种单字节的编码。计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制符号。不过ASCII只用到了其中的一半(\x80以下),这也是MBCS得以实现的基础。
1.2 MBCS编码
然而计算机世界里很快就有了其他语言,单字节的ASCII已无法满足需求。后来每个语言就制定了一套自己的编码,由于单字节能表示的字符太少,而且同时也需要与ASCII编码保持兼容,所以这些编码纷纷使用了多字节来表示字符,如GBxxx、BIGxxx等等,他们的规则是,如果第一个字节是\x80以下,则仍然表示ASCII字符;而如果是\x80以上,则跟下一个字节一起(共两个字节)表示一个字符,然后跳过下一个字节,继续往下判断。
这里,IBM发明了一个叫Code Page的概念,将这些编码都收入囊中并分配页码,GBK是第936页,也就是CP936。所以,也可以使用CP936表示GBK。
MBCS(Multi-Byte Character Set)是这些编码的统称。目前为止大家都是用了双字节,所以有时候也叫做DBCS(Double-Byte Character Set)。必须明确的是,MBCS并不是某一种特定的编码,Windows里根据你设定的区域不同,MBCS指代不同的编码,而Linux里无法使用MBCS作为编码。在Windows中你看不到MBCS这几个字符,因为微软为了更加洋气,使用了ANSI来吓唬人,记事本的另存为对话框里编码ANSI就是MBCS。同时,在简体中文Windows默认的区域设定里,指代GBK。
1.3 Unicode编码
后来,有人开始觉得太多编码导致世界变得过于复杂了,让人脑袋疼,于是大家坐在一起拍脑袋想出来一个方法:所有语言的字符都用同一种字符集来表示,这就是Unicode。
最初的Unicode标准UCS-2使用两个字节表示一个字符,所以你常常可以听到Unicode使用两个字节表示一个字符的说法。但过了不久有人觉得256*256太少了,还是不够用,于是出现了UCS-4标准,它使用4个字节表示一个字符,不过我们用的最多的仍然是UCS-2。
UCS(Unicode Character Set)还仅仅是字符对应码位的一张表而已,比如"汉"这个字的码位是6C49。字符具体如何传输和储存则是由UTF(UCS Transformation Format)来负责。一开始这事很简单,直接使用UCS的码位来保存,这就是UTF-16,比如,"汉"直接使用\x6C\x49保存(UTF-16-BE),或是倒过来使用\x49\x6C保存(UTF-16-LE)。但用着用着美国人觉得自己吃了大亏,以前英文字母只需要一个字节就能保存了,现在大锅饭一吃变成了两个字节,空间消耗大了一倍……于是UTF-8横空出世
1.4 Utf-8编码
UTF-8是一种很别扭的编码,具体表现在他是变长的,并且兼容ASCII,ASCII字符使用1字节表示。然而这里省了的必定是从别的地方抠出来的,你肯定也听说过UTF-8里中文字符使用3个字节来保存吧?4个字节保存的字符更是在泪奔……(具体UCS-2是怎么变成UTF-8的请自行搜索)
另外值得一提的是BOM(Byte Order Mark)。我们在储存文件时,文件使用的编码并没有保存,打开时则需要我们记住原先保存时使用的编码并使用这个编码打开,这样一来就产生了许多麻烦。(你可能想说记事本打开文件时并没有让选编码?不妨先打开记事本再使用文件 -> 打开看看)而UTF则引入了BOM来表示自身编码,如果一开始读入的几个字节是其中之一,则代表接下来要读取的文字使用的编码是相应的编码:
BOM_UTF8 '\xef\xbb\xbf'
BOM_UTF16_LE '\xff\xfe'
BOM_UTF16_BE '\xfe\xff'
并不是所有的编辑器都会写入BOM,但即使没有BOM,Unicode还是可以读取的,只是像MBCS的编码一样,需要另行指定具体的编码,否则解码将会失败。
你可能听说过UTF-8不需要BOM,这种说法是不对的,只是绝大多数编辑器在没有BOM时都是以UTF-8作为默认编码读取。即使是保存时默认使用ANSI(MBCS)的记事本,在读取文件时也是先使用UTF-8测试编码,如果可以成功解码,则使用UTF-8解码。记事本这个别扭的做法造成了一个BUG:如果你新建文本文件并输入"姹塧"然后使用ANSI(MBCS)保存,再打开就会变成"汉a",你不妨试试 :)
2.python2.7中的字符编码
2.1 str 和 unicode
python中有两种数据模型来支持字符串这种数据类型,str和unicode,它们的基类都是basestring。严格意义上说,str其实是字节串,它是unicode经过编码(例k如:unicode编码成utf-8、GBK等)后的字节组成的序列。在python中,str对象可以和unicode对象可以使用decode和encode函数相互转换。
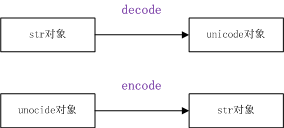
python中str对象和unicode的定义如下:
1 #coding=utf-8
2 str = "测试" #str类型的字符串
3 unStr=u"测试" #unicode类型的字符串:通过字符串前的u标识
2.2 decode()和encode()函数
本小节的示例演示的操作系统环境均为linux下的console。
2.2.1 decode函数:
使用方法:unStr=str.decode(“dec_mode”),意即:按照dec_mode编码方式解析str对象,然后转换成unicode对象,当dec_mode与str对象本身的编码方式不吻合时,容易出现问题。示例源码charDecode.py 如下:
1 #coding=utf-8
2 str = "测试"
3 #unStr=str.decode("utf-8")
4 unStr=str.decode("ascii")
5 print type(str) #打印str的类型
6 print type(unStr) #打印unStr的类型
7 print repr(str)
8 print repr(unStr)
1)此时,以python charDecode.py运行该脚本,会提示如下错误:
Traceback (most recent call last):
File "charDecode.py", line 4, in <module>
unStr=str.decode("ascii");
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128)
2)如果将上述代码中的第4行注释掉,第3行取消注释,再运行,就是正常的,结果如下:
<type 'str'>
<type 'unicode'>
'\xe6\xb5\x8b\xe8\xaf\x95'
u'\u6d4b\u8bd5'
原因就是:代码中的str对象的编码方式是utf-8的(根据python的官方说明,sys.getdefaultencoding()函数,会返回str类型字符串的默认编码方式。本例中调用sys.getdefaultencoding(),返回结果为ascii,但是由于代码中的第1行中,声明了#coding=utf-8:意即指定代码文件中的对象的编码方式为utf-8,因此str的编码格式为utf-8),编码值为'\xe6\xb5\x8b\xe8\xaf\x95'。在1)中,当通过ascii方(取值0-127)解码str对象时,发现超出了127范围,当然就报错了; 而在2)中,str对象自身的编码方式和调用decode指定的编码方式是一致的,因此不会出现问题。
一般遇到UnicodeDecodeError错误,首先检查调用decode时的指定的dec_mode是否和待解码str自身的编码方式是否一致。
2.2.2 encode函数
使用方法:str=unStr.encode(“enc_mode”),意即:按照enc_mode编码转换 unicode对象unStr,得到enc_mode编码格式的str对象。如果enc_mode与unStr不适配,那么也会出现问题(例如:unicode编码成ascii),这个问题会在下一章结合print语句,给出示例和解释。
本章主要介绍了字符串编码和python中字符串的相关知识,下一章会分析一下python中print中文出现编码错误以及显示乱码的原因和解决方案。















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









