






一、基础介绍
1.什么是机器翻译
机器翻译(Machine Translation,MT)是指利用计算机软件自动将一种自然语言文本翻译成另一种自然语言文本的过程。

二、关于环境配置
1.环境:
环境配置是新手比较头疼的问题。以下是运行基于transformer的机器翻译系统的环境配置,可供大家参考。
python:3.8
torch: 1.11.0+cu113
torchvision: 0.12.0+cu113
torchaudio: 0.11.0
numpy: =1.20.0
matplotlib: =3.4.0
scikit-learn: =0.24.0
pandas: =1.3.0
jupyterlab: =3.2.0
tqdm: =4.62.0
sentencepiece:0.1.91
torchtext:0.6.0
如果创建了虚拟环境,已经下载了某个库,运行时仍然报错Not Found该库
(1)在终端先用下列语句查看该库的安装路径(以torch为例)
pip show torch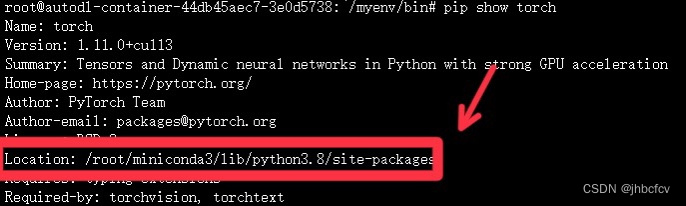
(2)再用以下语句在终端查看当前下载路径
which python
若1,2地址不符,则将路径1中的torch文件复制到路径2中,即可解决问题
2.gpu配置
(1)用自己电脑配置gpu:
注意:电脑显存需大于8G
(2)租用云服务器:
我使用的是AutoDL云服务器,如何使用可参考下面这篇文章:
【新手小白如何租用GPU云服务器跑深度学习 - CSDN App】http://t.csdnimg.cn/OZz5u
三、基于规则的机器翻译
1.基于规则的机器翻译(Rule-Based Machine Translation,RBMT):利用词典和语言规则进行翻译,主要依赖语言学家编写的规则。
优点:直观、直接表达语言学共识, 规则比较灵活,系统理论上比较可控
缺点:主观性强、覆盖性差、维护成本高; 引入新的规则容易造成冲突;人工编写,工作量大
开发成本高,一个语言对应一个系统;(语义障碍)自然语言的歧义无法解决
2.简单的例子
#1.制定几条简单的规则
translation_rules = {
'dog': 'chien',
'cat': 'chat',
'is': 'est',
'eating': 'mange',
'running': 'court',
'fast': 'vite'
}
#2.翻译函数
def translate_to_french(sentence):
words = sentence.split()
translated_sentence = []
for word in words:
if word in translation_rules:
translated_sentence.append(translation_rules[word])
else:
translated_sentence.append(word) # 如果找不到匹配的词汇,保持原样
return ' '.join(translated_sentence)
#3.测试用例
english_sentence = "The dog is eating fast."
french_translation = translate_to_french(english_sentence)
print(french_translation)
输出:Le chien est mange vite.
四、基于统计的机器翻译
1.基于统计的机器翻译(Statistical Machine Translation,SMT):基于统计模型和大规模双语语料库,利用概率和统计方法进行翻译。
2.1993 年 IBM提出基于词对齐的翻译模型 ,标志着现代统计机器翻译方法的诞生
2003 年,基于短语的翻译模型和最小错误率训练方法的提出标志着统计机器翻译的崛起
3.优缺点
优点:适应力强;可以上下文感知
缺点:假设多,建模能力低;无法捕捉语言的抽象语义
五、基于神经网络的机器翻译
1.基于神经网络的机器翻译(Neural Machine Translation,NMT):
利用深度学习和神经网络模型进行翻译,目前最为先进和常用的技术。
2.机器翻译的工作原理
- 预处理:对源语言文本进行分词、词性标注、去除噪音等处理。
- 编码:将源语言文本编码为计算机可处理的格式(如词嵌入)。
- 翻译模型:使用预训练的机器翻译模型对编码后的源语言文本进行翻译生成目标语言文本。
- 解码:将翻译模型生成的目标语言文本解码为人类可读的格式。
- 后处理:对目标语言文本进行拼写检查、语法修正等处理。
3.编码器与解码器
Encoder-Decoder结构:
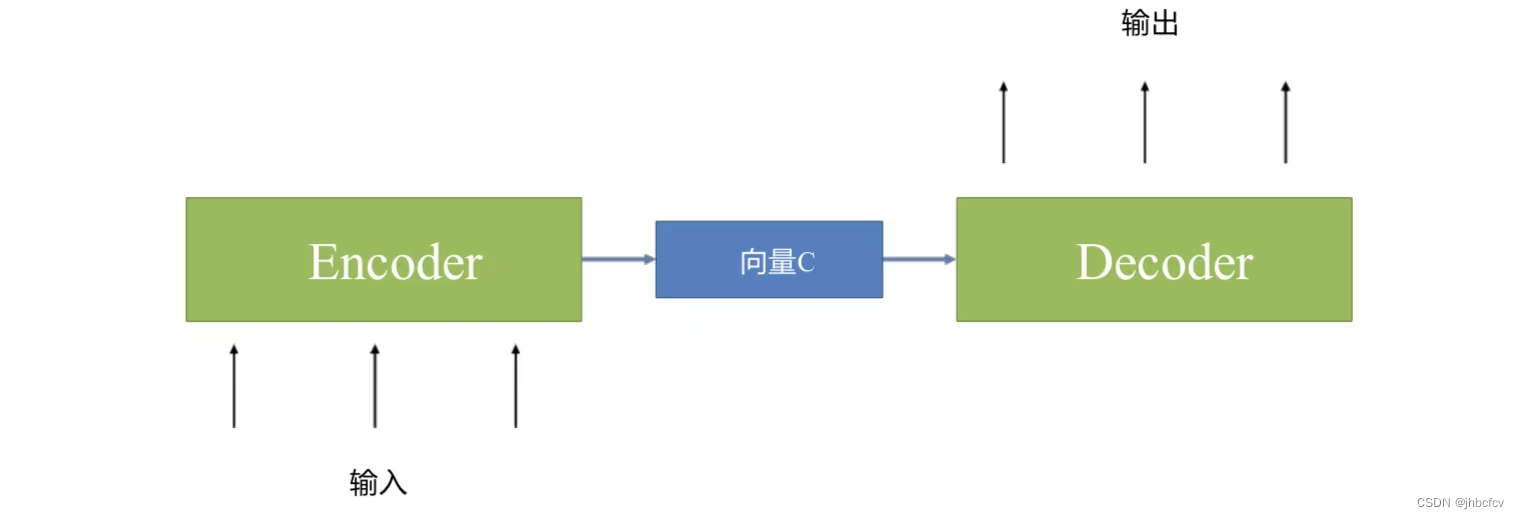
编码器(Encoder):负责将输入序列(比如一段文本)编码成一个中间表示(或者叫做上下文向量),捕捉输入序 列的语义信息并将其转换为一个固定⻓度的向量表示。
解码器(Decoder):接收编码器生成的中间表示,然后将其解码为输出序列(比如另一种语言的文本),逐步生成 目标序列的每个元素。
优势:Encoder-Decoder结构可以处理不定⻓的输入和输出序列,适用于各种序列到序列的NLP任务。
根据不同的任务可以选择不同的编码器和解码器
1)循环神经网络 :RNN、LSTM、GRU
2)卷积神经网络:CNN
3)注意力机制:Attention、 Transformer
4.带有注意力机制的编码器-解码器结构

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









