







文章目录
一、list基本介绍
如下所示,是库里面对list的基本介绍

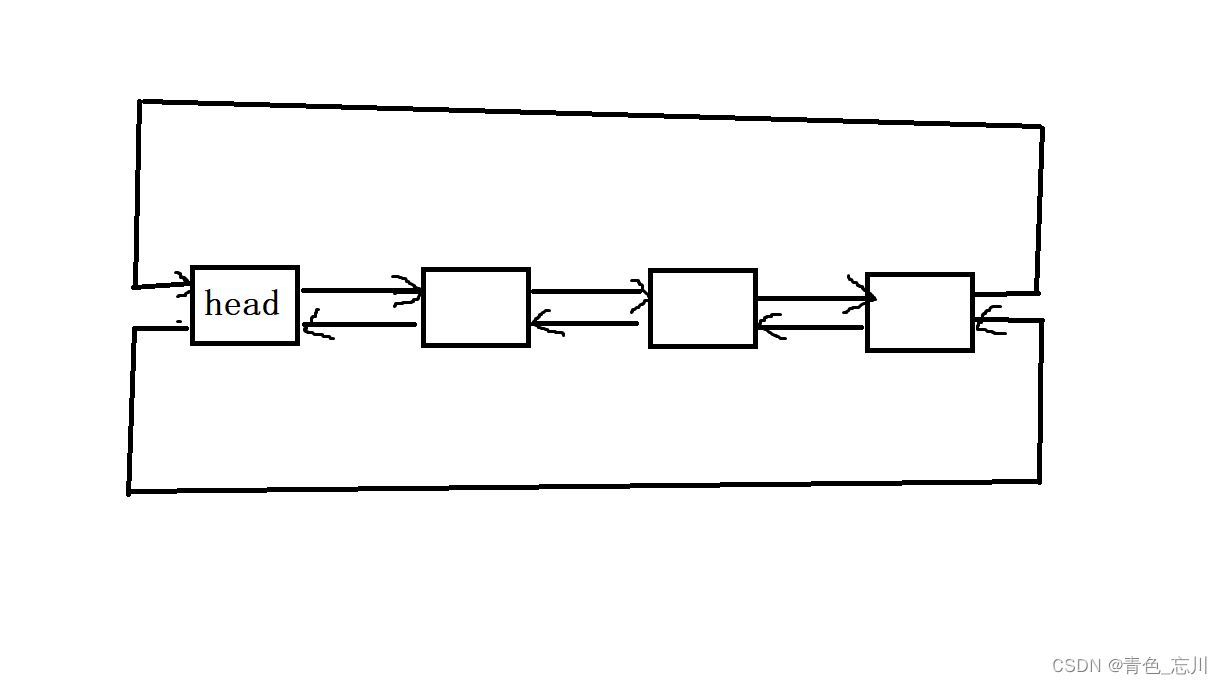
链表是序列容器,允许在序列内的任何位置进行常量时间的插入和擦除操作,以及两个方向的迭代。
链表容器被实现为双链表;双链表可以将它们包含的每个元素存储在不同且不相关的存储位置。排序是通过与前面元素的链接和后面元素的链接的每个元素的关联在内部保持的。
它们与forward_list非常相似:主要区别在于forward_list对象是单链表,因此它们只能向前迭代,以换取更小和更高效。
与其他基本标准序列容器(array、vector和deque)相比,链表在容器内的任何位置插入、提取和移动元素(迭代器已经获得)方面通常表现更好,因此在大量使用链表的算法(如排序算法)中也表现更好。
与其他序列容器相比,列表和forward_lists的主要缺点是它们无法通过位置直接访问元素;例如,要访问链表中的第六个元素,必须从已知位置(如开始或结束)迭代到该位置,这需要在两者之间的距离上花费线性时间。它们还消耗一些额外的内存来保存与每个元素相关联的链接信息(对于包含小元素的大型列表来说,这可能是一个重要因素)。
二、list基本使用
我们先简单的使用一下一下list,list的使用与vector基本是一致的,需要注意的是,对于list是没有[]运算符去访问的,因为其底层是一个双向带头循环链表。
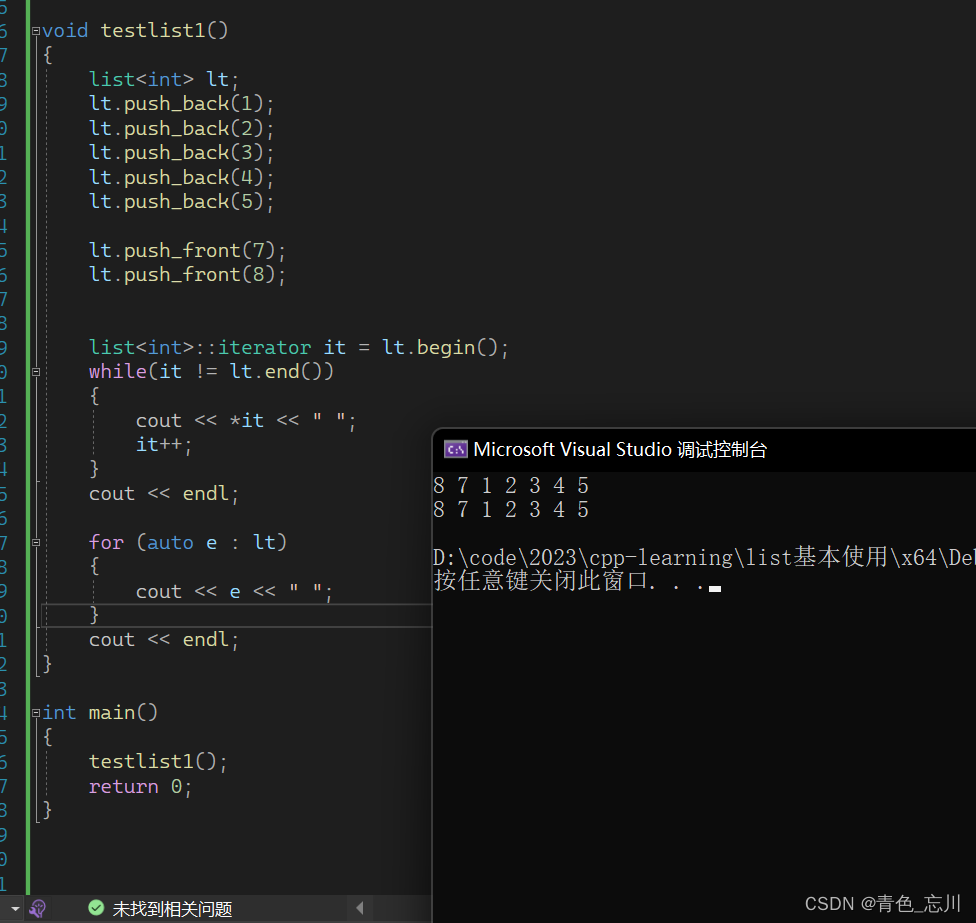
1.尾插头插接口使用
void testlist1()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
lt.push_front(7);
lt.push_front(8);
list<int>::iterator it = lt.begin();
while(it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
2.insert接口使用
从下面,我们已经看出来,对于list它的接口已经全部是迭代器去访问了,可以是在某个迭代器处插入一个值,可以是插入n个val,也可以是插入一个迭代器区间

在这里需要注意的是,由于list本身是一个链表的特性,所以如果想要在第五个位置插入一个值,以下写法是错误的。如果是vector确实可以这样插入
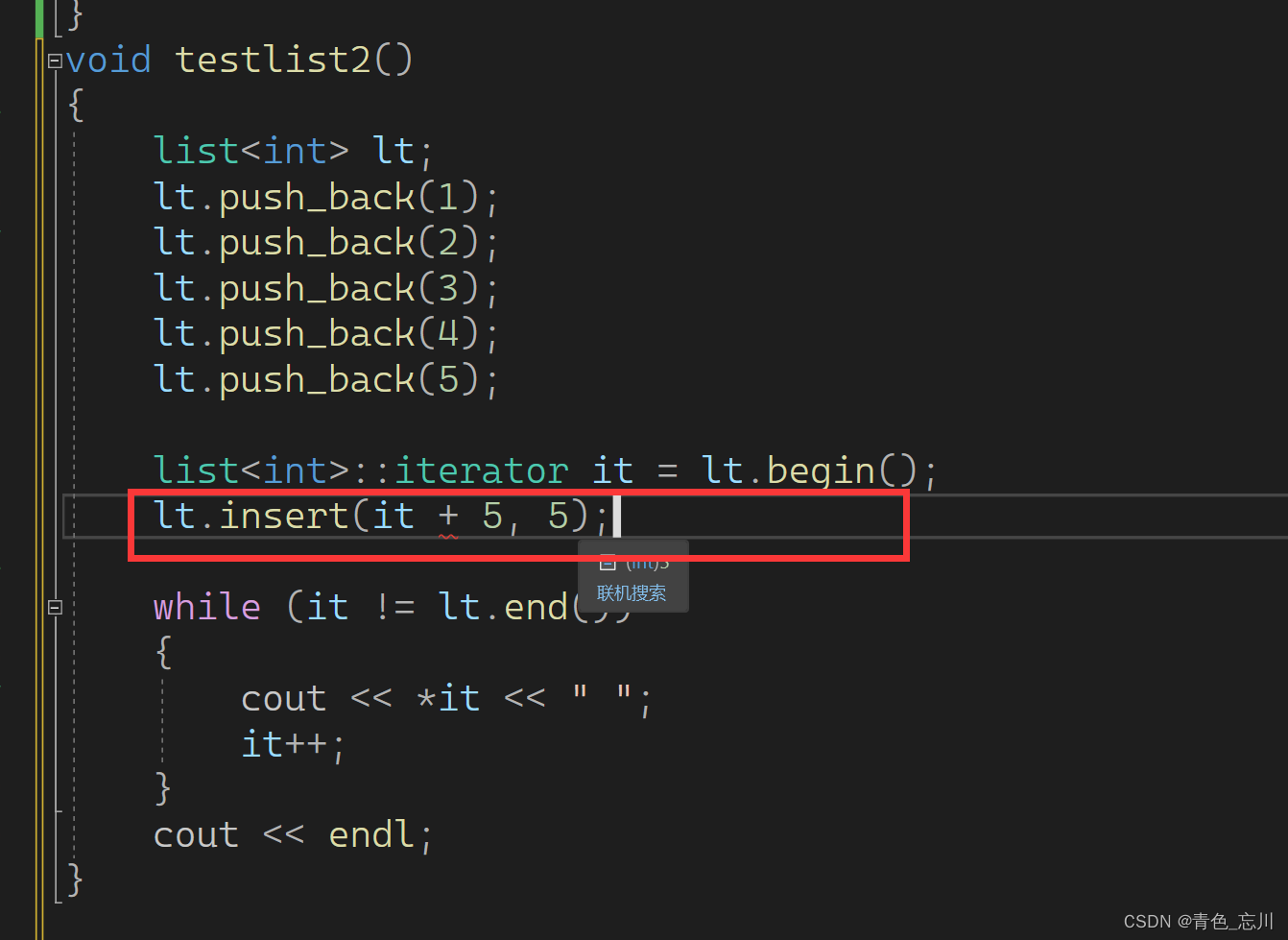
如果是我们自己去写这个list的话,我们可以加上这个运算符重载,但是库里面觉得这个代价太大,所以没有加
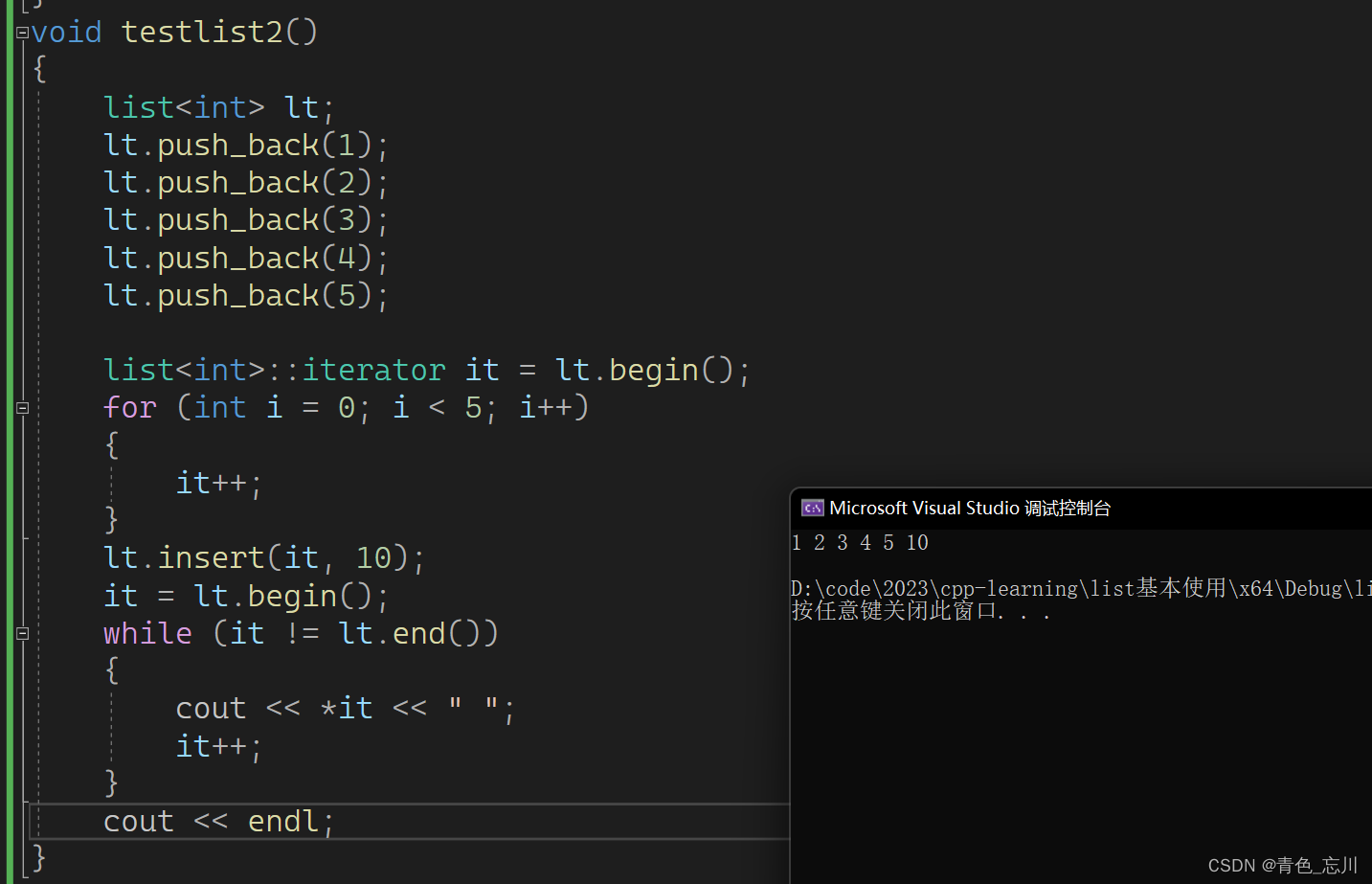
但是如果非要在第五个位置处插入,我们可以这样写,这样直接插入的代价是比较低的,因为其只需要改变连接关系即可
void testlist2()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int>::iterator it = lt.begin();
for (int i = 0; i < 5; i++)
{
it++;
}
lt.insert(it, 10);
it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
3.查找某个值所在的位置
其实在C++中list并没有直接提供这个接口,这是因为C++中是将容器和算法进行了分离。而这两个是通过迭代器进行连接起来的。
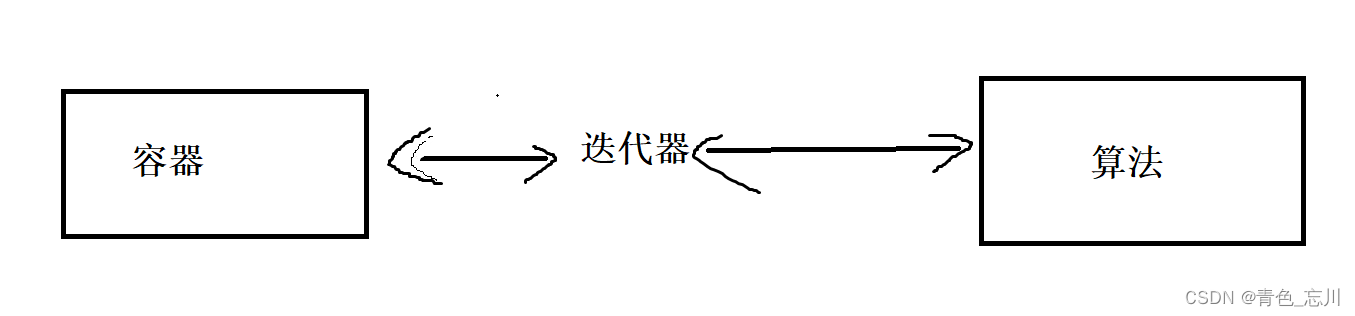
因为迭代器并不暴露容器底层的细节。就能让算法直接访问容器里面的元素。
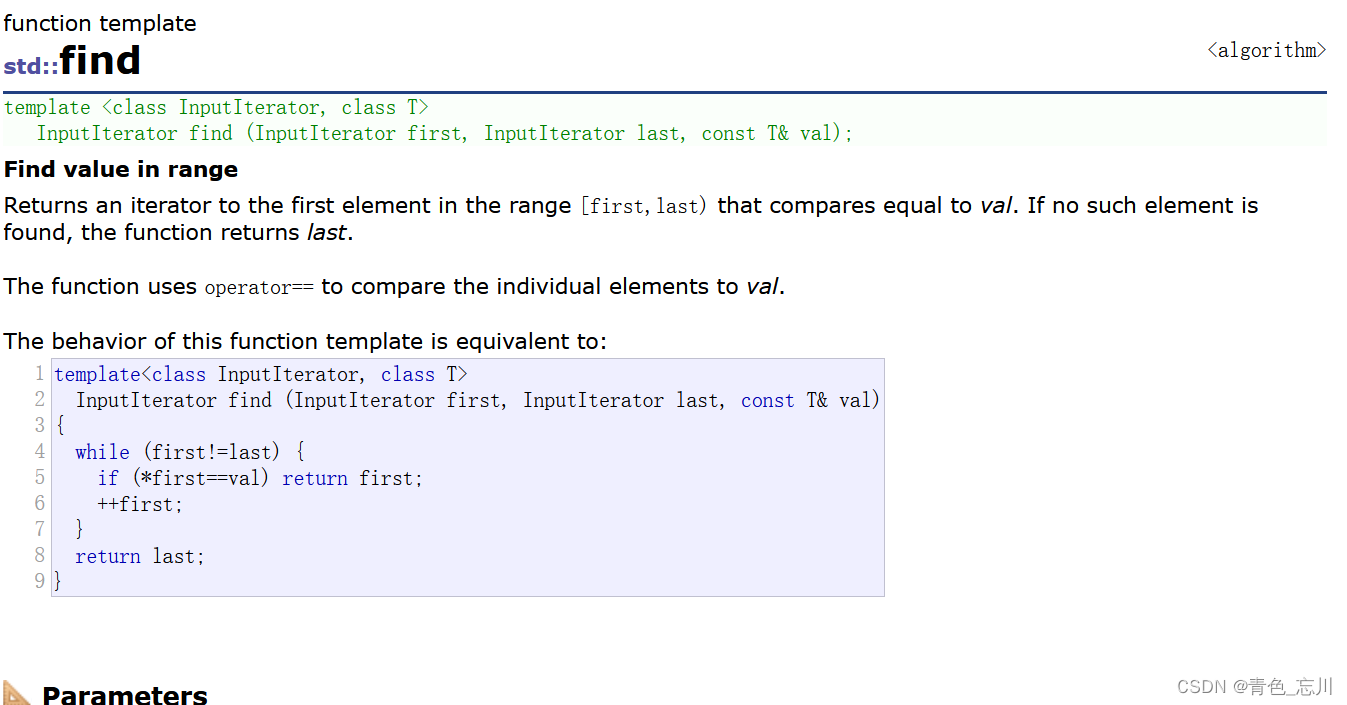
注意库里面使用的是不等于,而非小于,这是为了适应其他各种各样的容器而设置的
比如list容器中,如果不采用这种设计结构,那么由于本来每个地址都是离散的,并不能确保每个结点的地址究竟是如何的,而产生严重的错误。
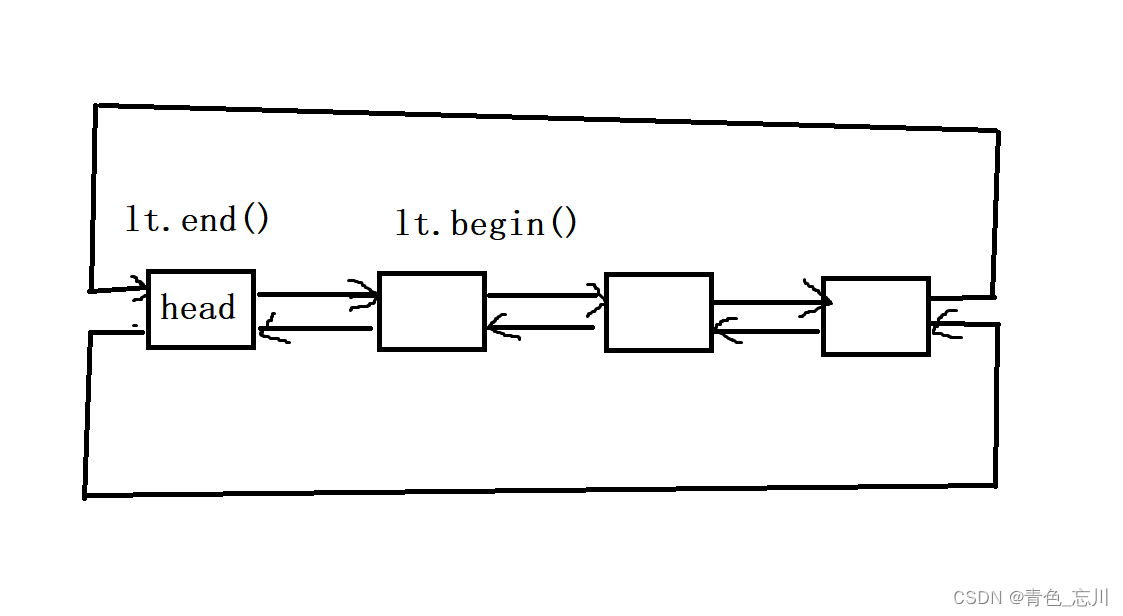
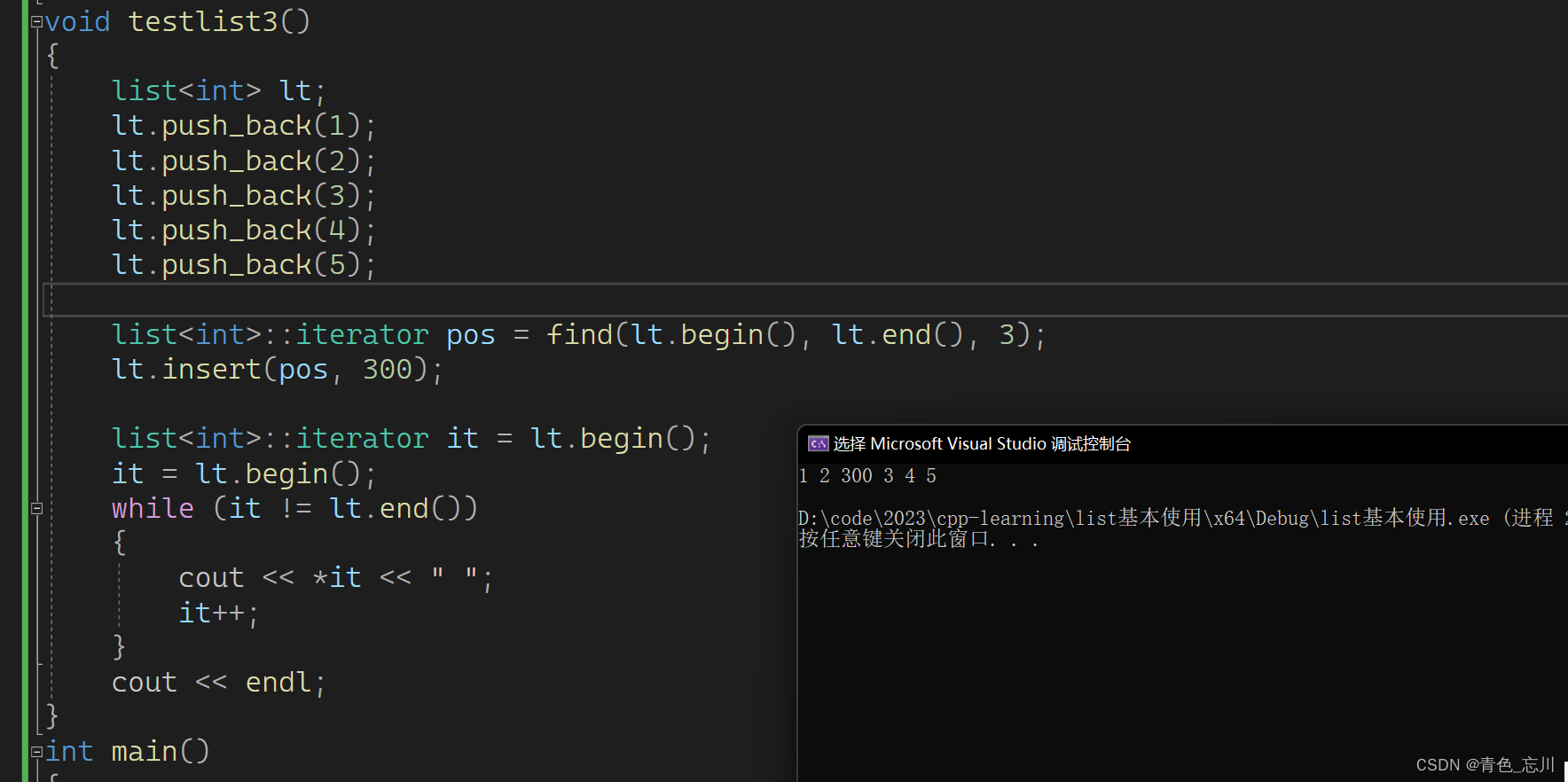
我们现在来使用一下
void testlist3()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int>::iterator pos = find(lt.begin(), lt.end(), 3);
lt.insert(pos, 300);
list<int>::iterator it = lt.begin();
it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
那么我们现在再来探讨一下,vector里使用insert后会存在失效问题,那么链表中还有吗。
我们可以测试一下
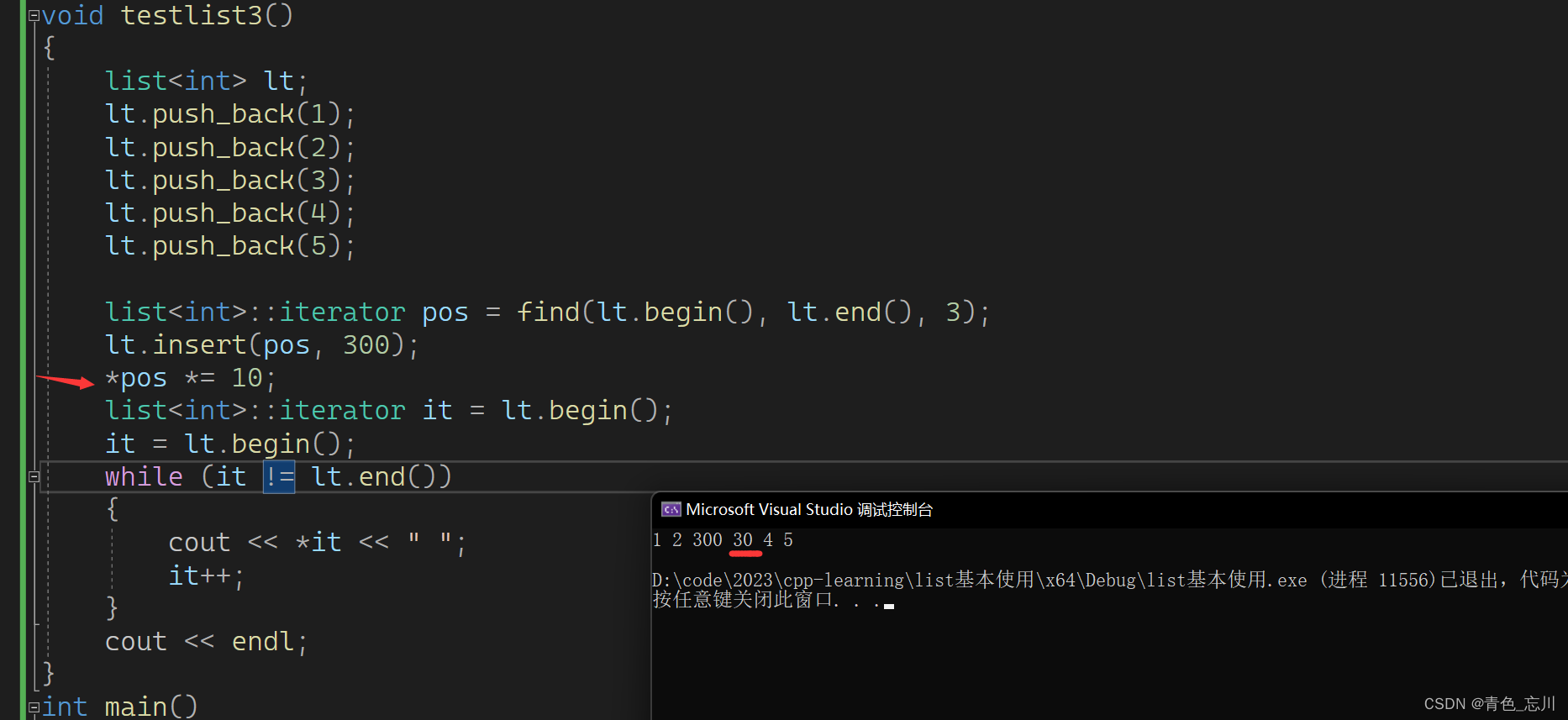
测试结果显示,迭代器并未失效,其实这里也挺好理解的,因为list的insert中它是一个结点一个结点的插入进去。而vector里则是看容量的,容量不够扩容时候,需要整体将空间移动位置,才导致的迭代器失效。而list不存在扩容问题。是不会将之前的数据都给换位置的。故而不导致迭代器失效。
4.erase接口使用以及迭代器失效
如下所示,erase可以删除某个迭代器位置的值,也可以删除某一个迭代器区间。
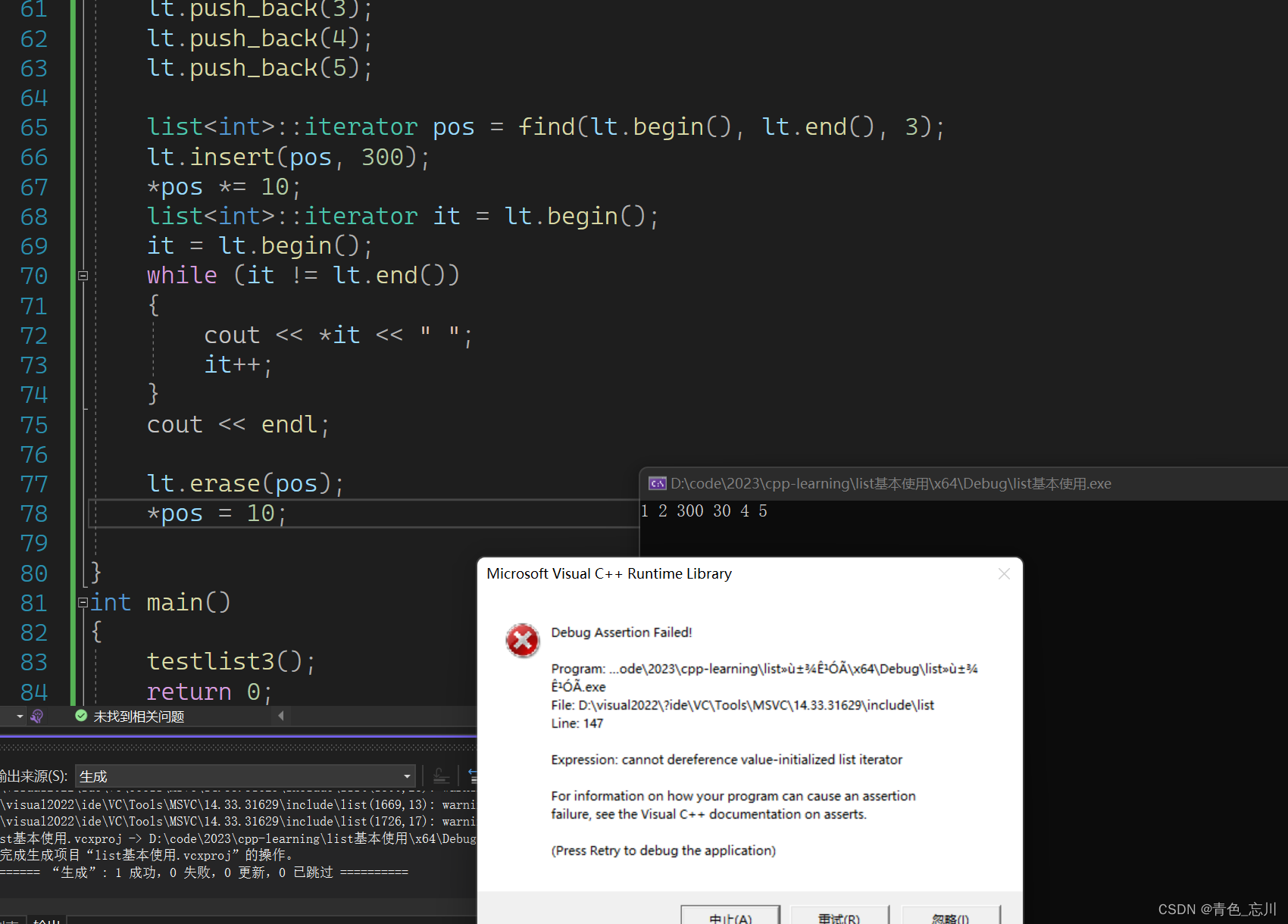
erase的使用很简单,我们这里主要研究以下,erase是否存在迭代器失效问题呢?其实是存在的,因为erase删除某一个结点后,由于list是离散的,所以之前的那个pos已经无法找到其他的结点的,这个迭代器已经是一个野指针了。故而失效。但是同样的库里面的解决方法就是增加一个返回值,返回已删除元素的下一个元素迭代器。
当我们想要删除所有的偶数的时候,我们也很容易的可以写出以下代码
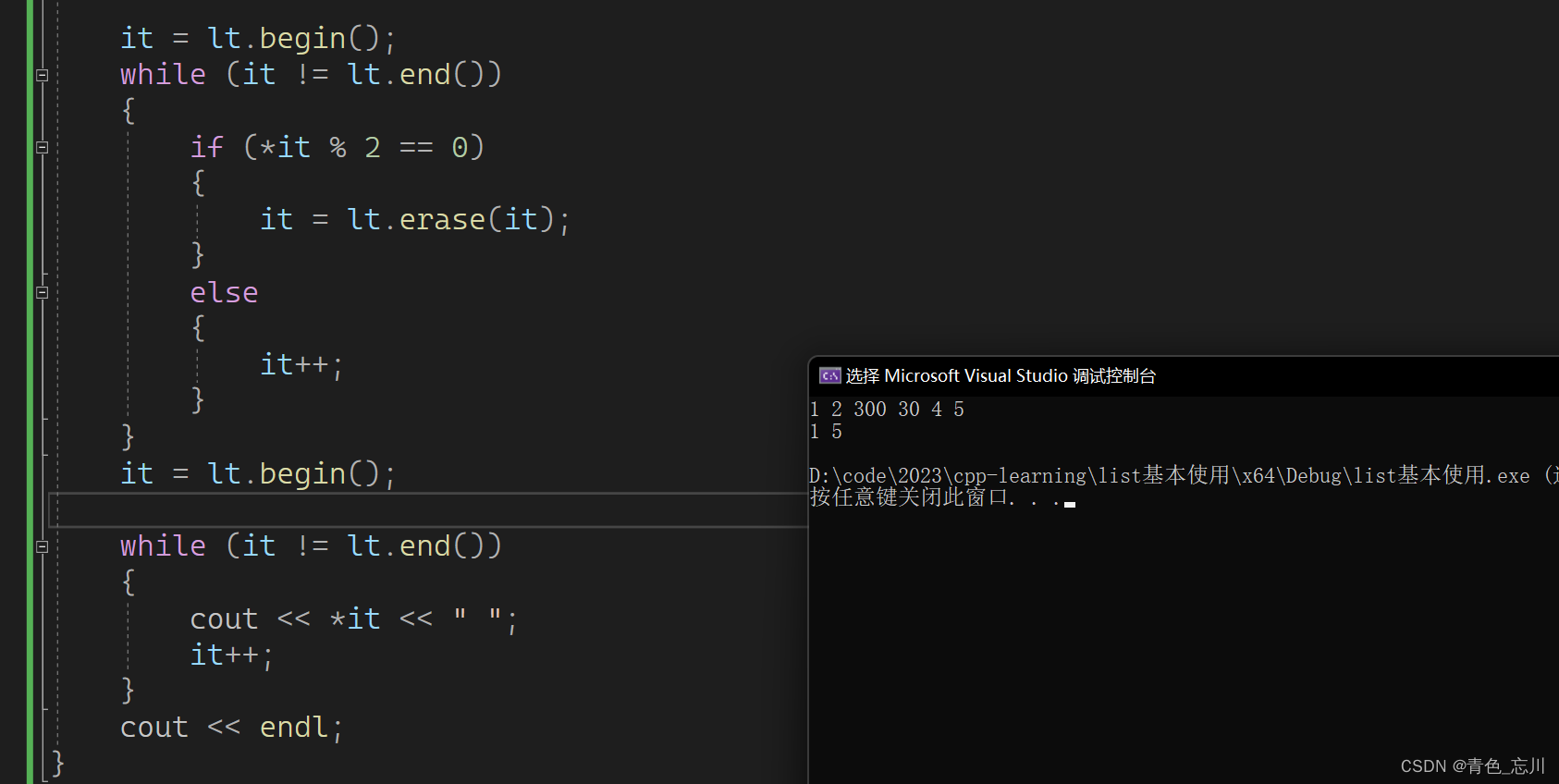
5.reverse
注意了啊,这里是逆置,不是reserve(扩容)
这个接口的作用就是逆置链表
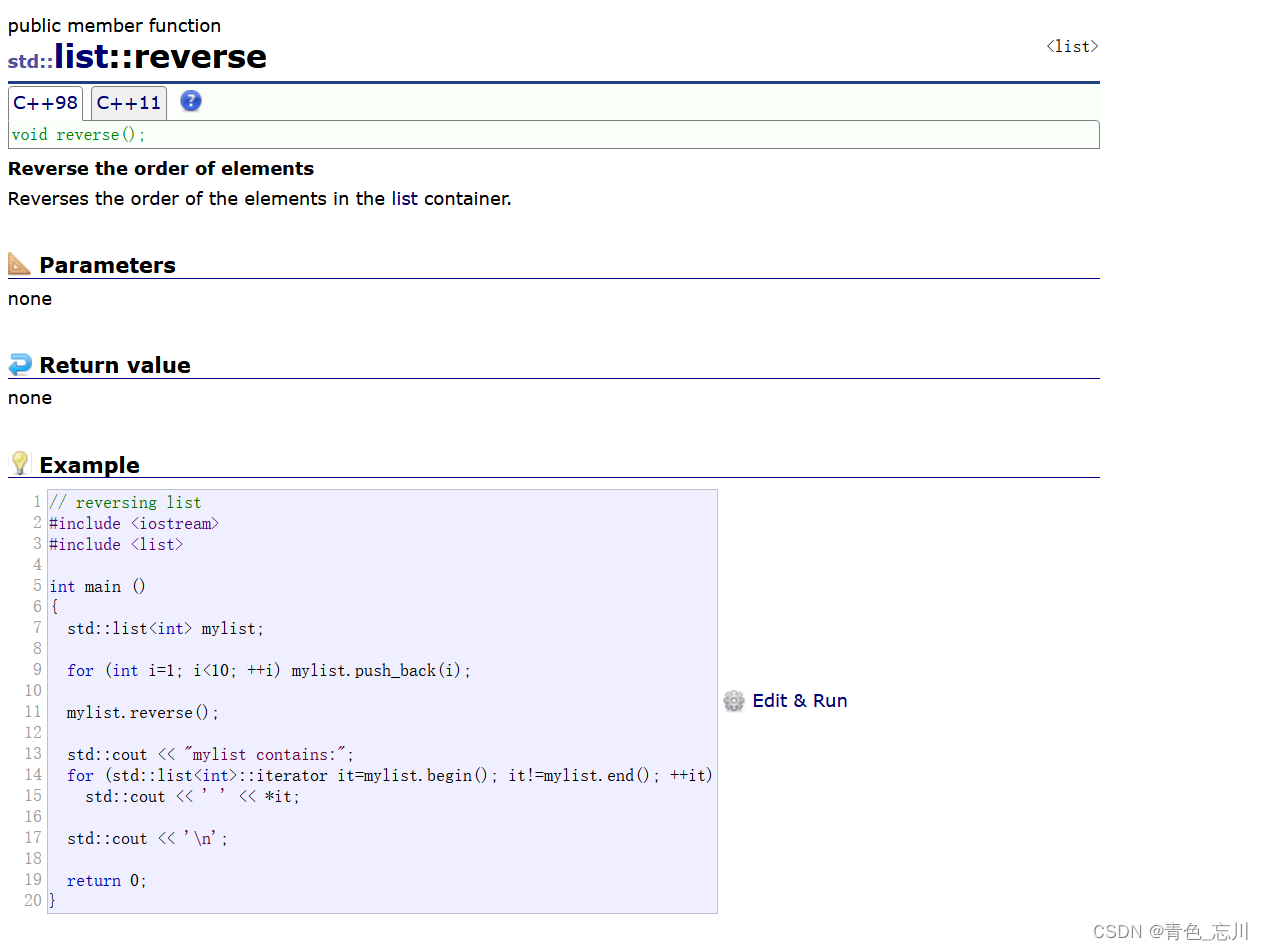
list里面虽然设计了这个接口,但是事实上这个接口是没有必要涉及的,有一点冗余,因为在算法库里面也设计了这个算法。而且这两个算法的思路是一模一样的
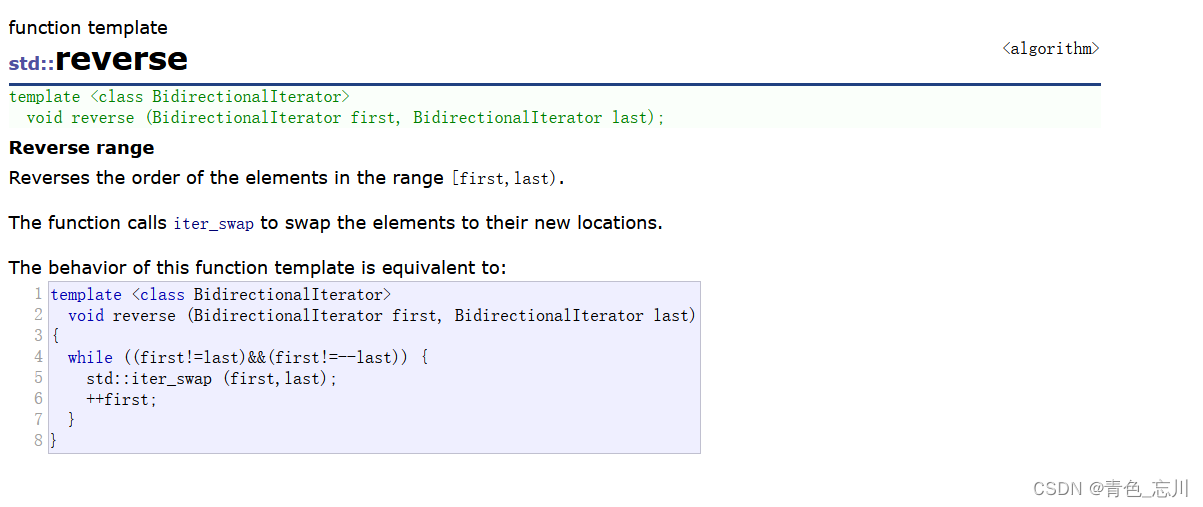
如下是测试代码
void testlist4()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
lt.reverse();
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
reverse(lt.begin(), lt.end());
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
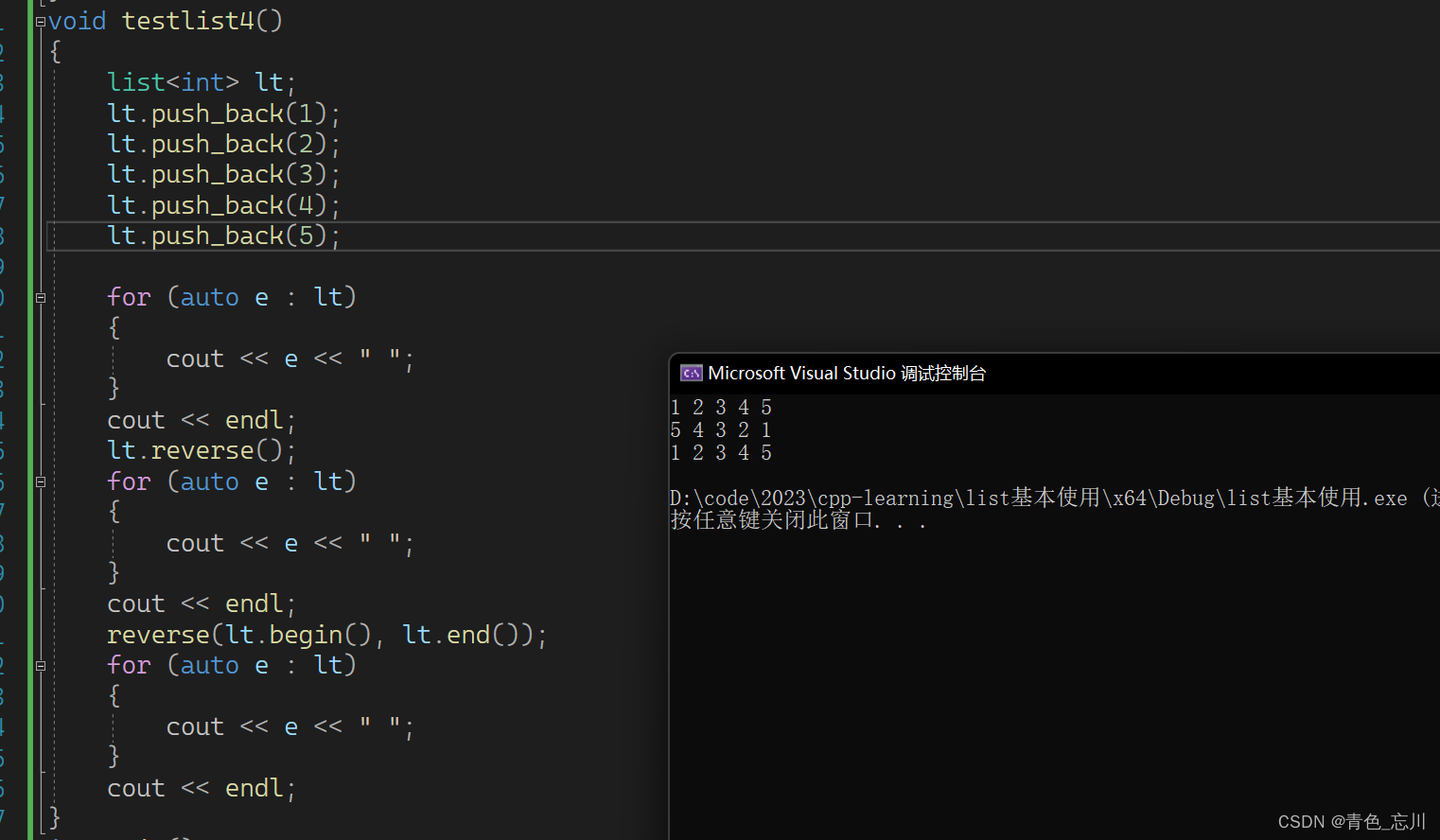
6.sort
如下是list里面的sort,可以直接排升序或者降序,使用很方便
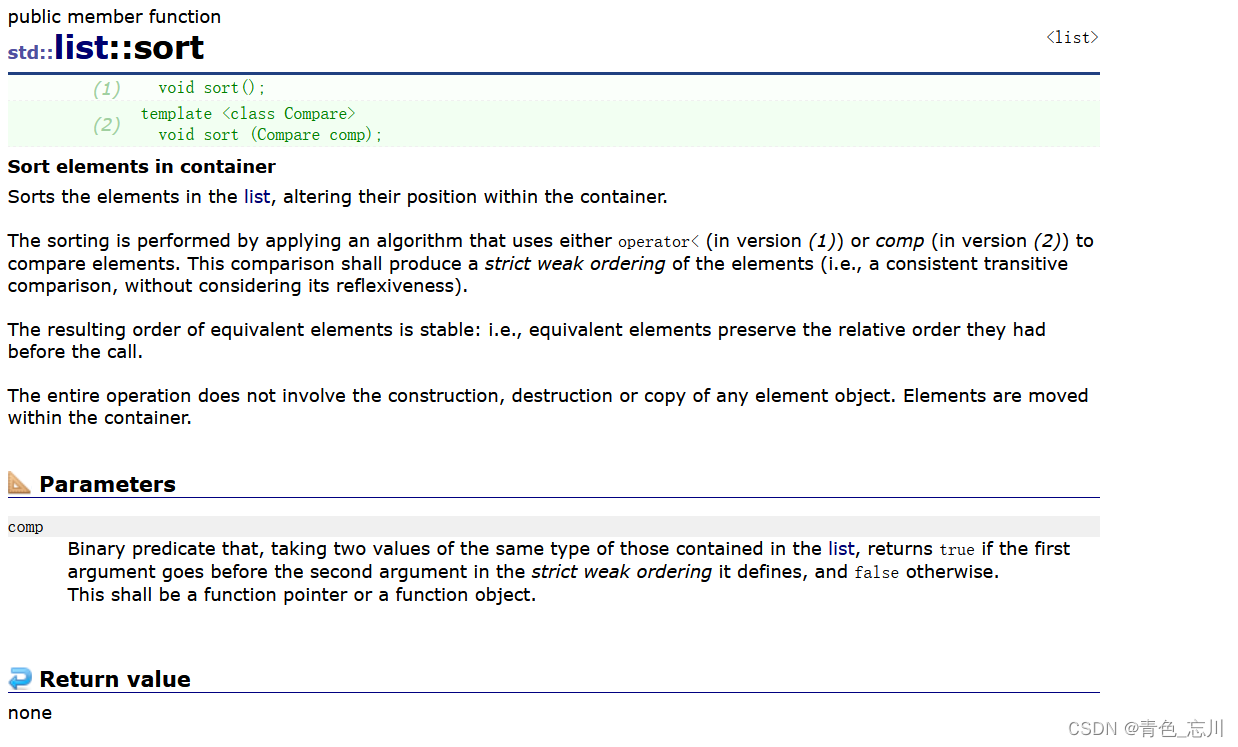
但是算法库里面也设计了一个sort,但是这个是冗余的吗?先说结论,算法库里面的sort对于list而言是用不了的。会直接报错
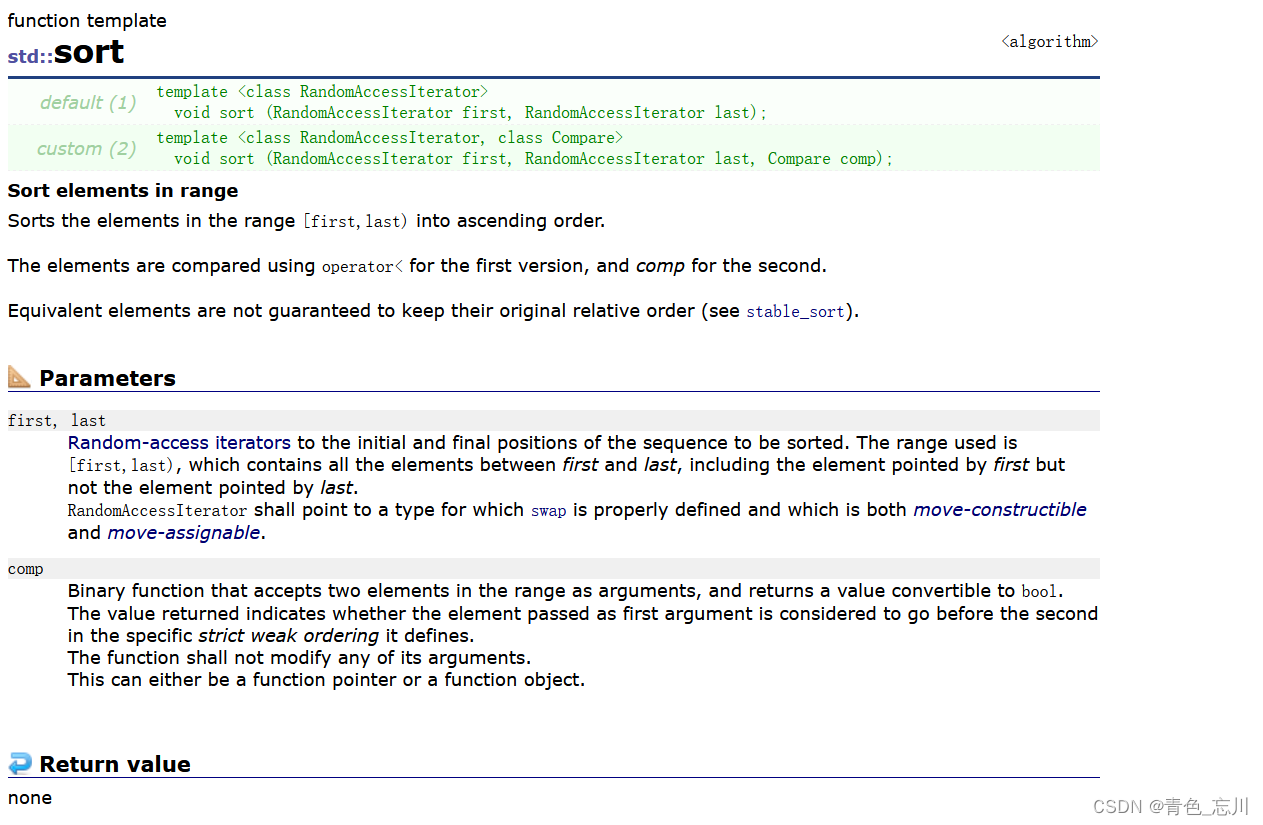
不相信的话,我们可以测试一下
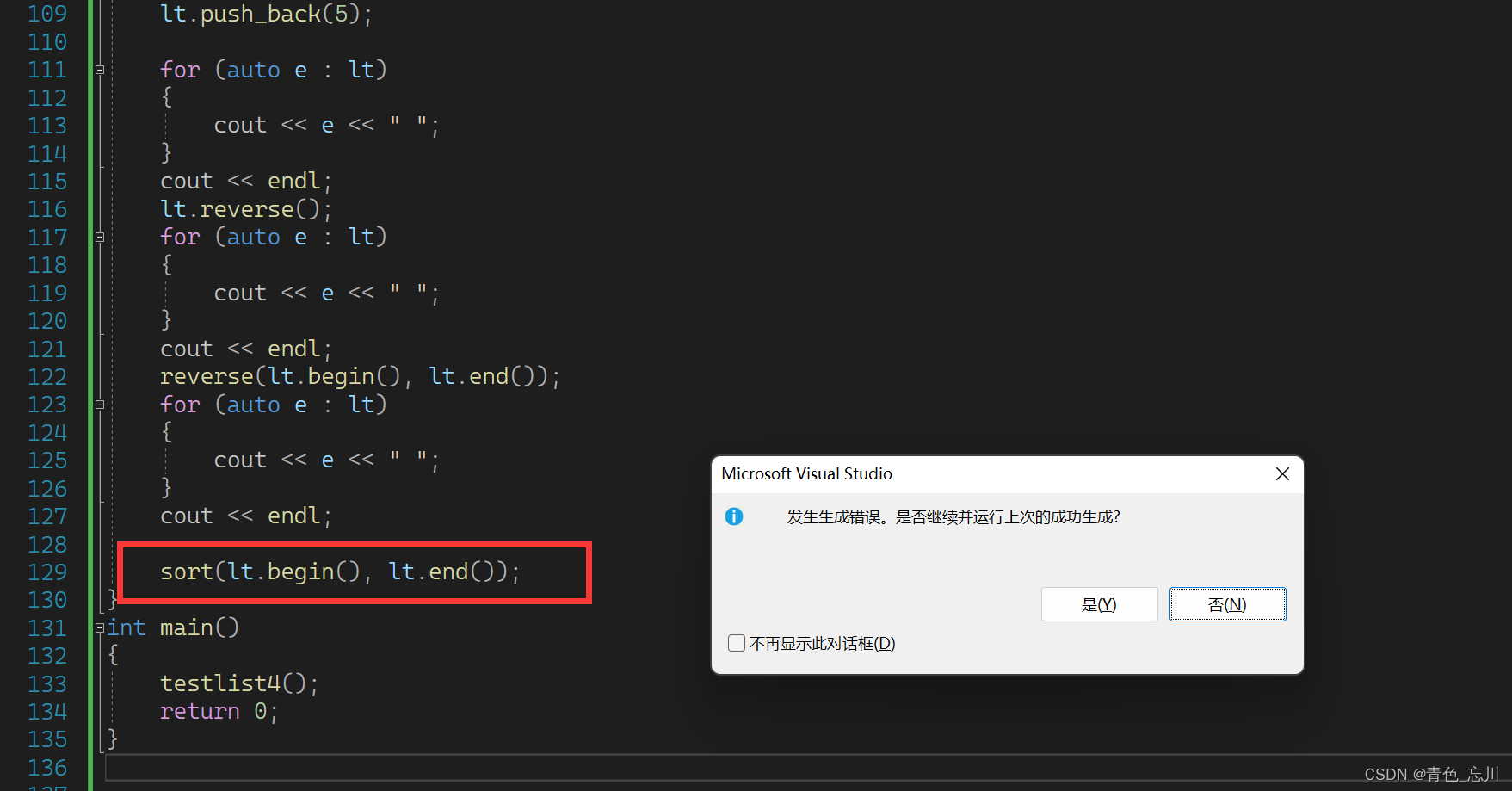
那么为什么用不了呢?我们可以深入去查看一下
我们从错误列表里面可以定位到是这里报错了
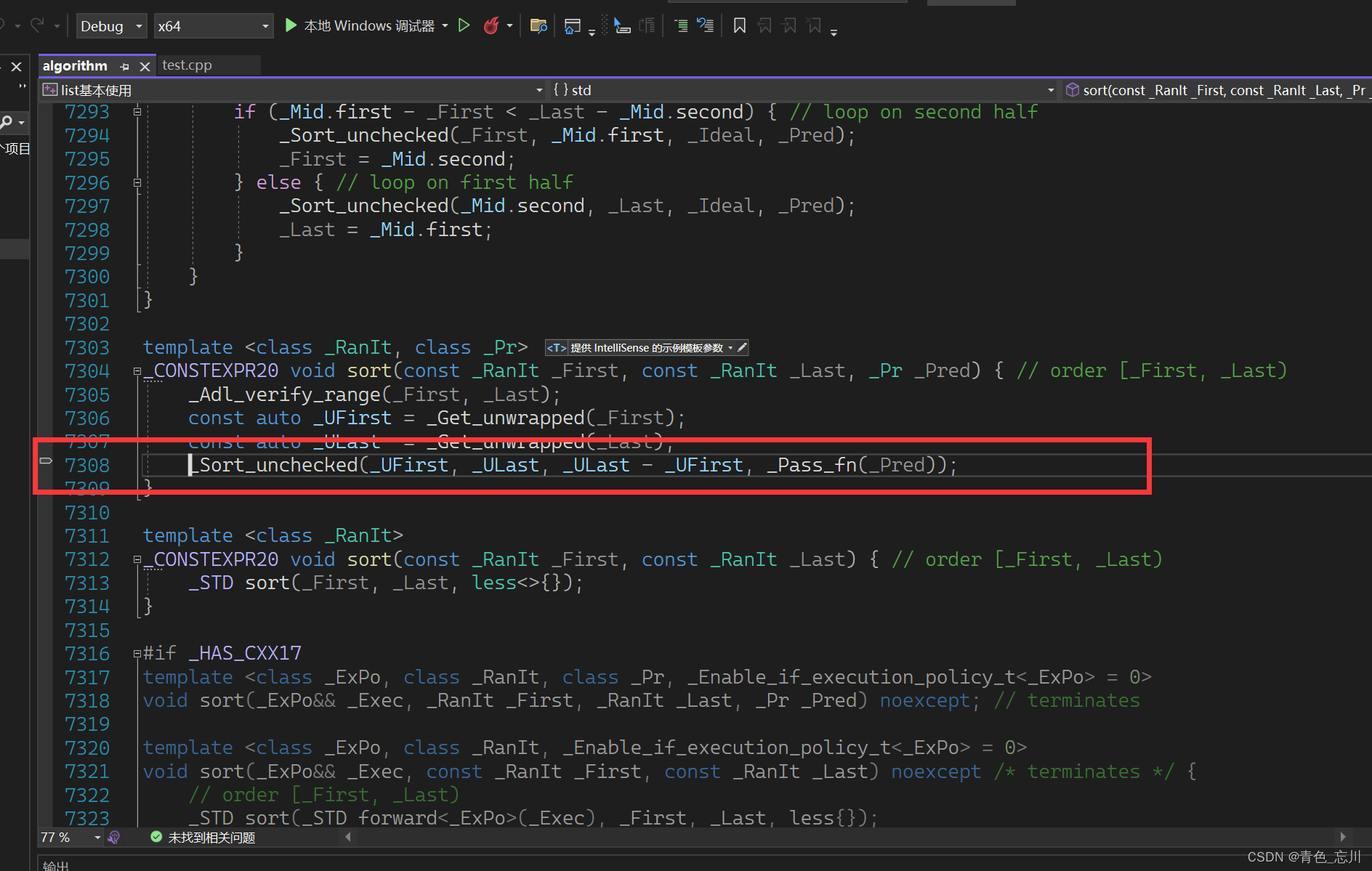
算法库里面使用的是快排,快排是无法适应list里面的这个场景的。
事实上,我们不难注意到,在算法库中,虽然每个算法都是一个函数模板,但是函数模板的迭代器名字有所差异

事实上,这是因为我们对迭代器从功能上进行了分类。注意这里的是由迭代器的性质(容器的底层结构决定的),从而进行的划分。他是一个隐式的划分

而上面的模板参数中对于迭代器的分类其实也显而易见了,Input就是所有迭代器都可以去用的。Bid这种迭代器就适合双向的迭代器去调用。Radom就适合随机迭代器去使用。
所以list适合双向迭代器,用不了随机的。
那么我们怎么知道哪个容器是哪种类型的呢?其实库里面已经全部说了
下面是list的迭代器

注意上面的不是彻底定死了,比如vector是随机迭代器,但他可以认为是特殊的双向迭代器。所以也是可以调用reverse接口的。

下面是vector的迭代器

再比如库里面也有单链表,forward_list,就是一个典型的单向迭代器

所以现在我们就清楚了为什么不能使用算法库里面的sort了,所以链表里面的sort就有点意义了。
当然呢,也只是有点意义罢了,其实也没有多大意义,为什么这么说呢?因为如果我们把list的数据拷贝给一个vector,然后用vector去排序,我们会发现,vector的效率远远高于list的效率
我们可以用如下代码去测试一下:注意需要在release环境下去测试,因为debug下有很多调试信息会影响两个的实际速度
void testlist5()
{
srand(time(0));
const int N = 1000000;
vector<int> v;
v.reserve(N);
list<int> lt1;
list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand();
lt2.push_back(e);
lt1.push_back(e);
}
// 拷贝到vector排序,排完以后再拷贝回来
int begin1 = clock();
// 先拷贝到vector
for (auto e : lt1)
{
v.push_back(e);
}
// 排序
sort(v.begin(), v.end());
// 拷贝回去
size_t i = 0;
for (auto& e : lt1)
{
e = v[i++];
}
int end1 = clock();
int begin2 = clock();
lt2.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
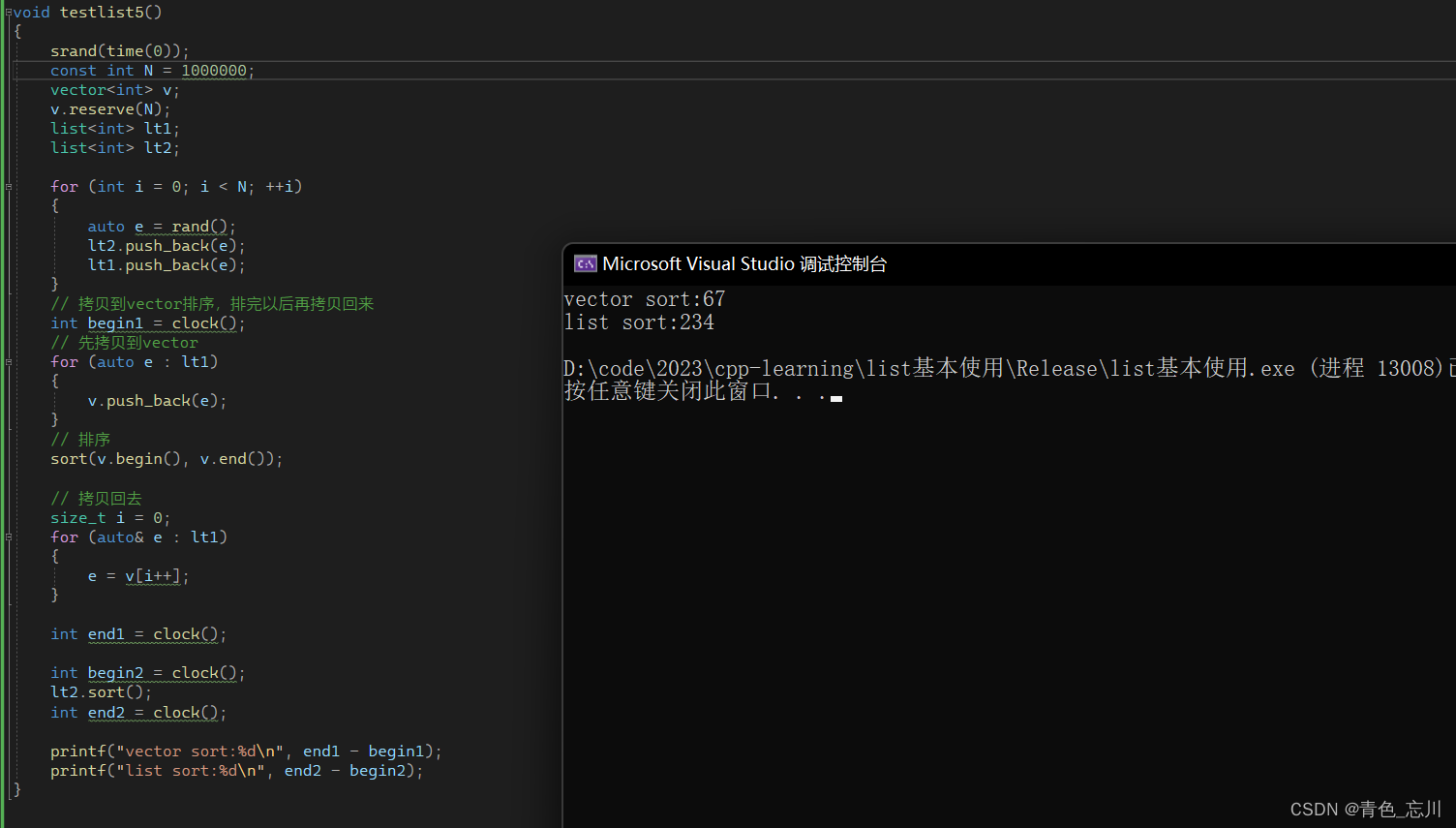
可见确实vector要优于list。因为库里面用的是快排,list里面用的是归并。快排还是要稍微优于归并一点的。
7.merge
如下所示,它的作用其实就是两个链表进行归并,注意归并前必须先进行排序
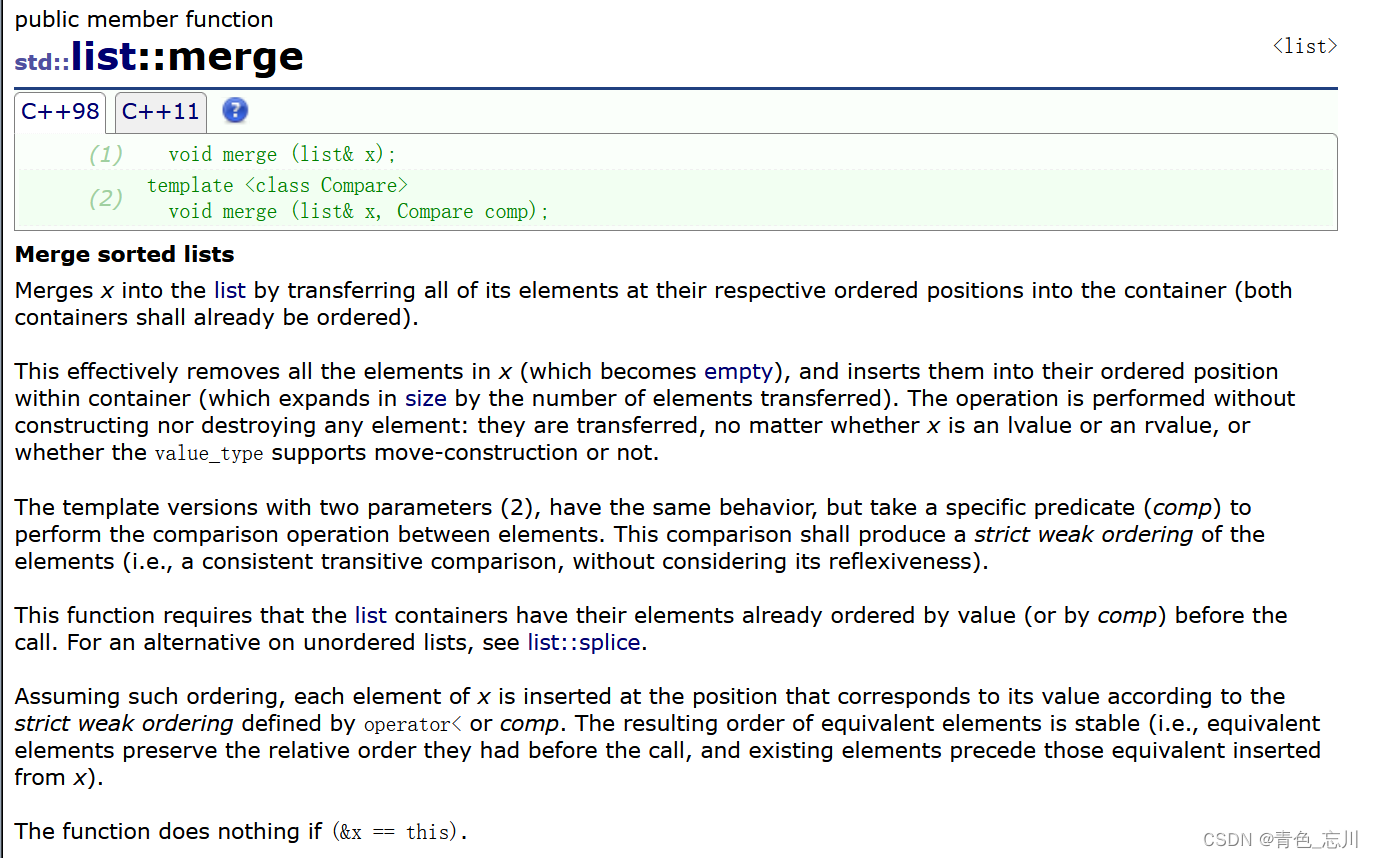
// list::merge
#include <iostream>
#include <list>
// compare only integral part:
bool mycomparison(double first, double second)
{
return (int(first) < int(second));
}
int main()
{
std::list<double> first, second;
first.push_back(3.1);
first.push_back(2.2);
first.push_back(2.9);
second.push_back(3.7);
second.push_back(7.1);
second.push_back(1.4);
first.sort();
second.sort();
first.merge(second);
// (second is now empty)
second.push_back(2.1);
for (auto e : second)
{
std::cout << e << " ";
}
std::cout << std::endl;
first.merge(second, mycomparison);
std::cout << "first contains:";
for (std::list<double>::iterator it = first.begin(); it != first.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
}
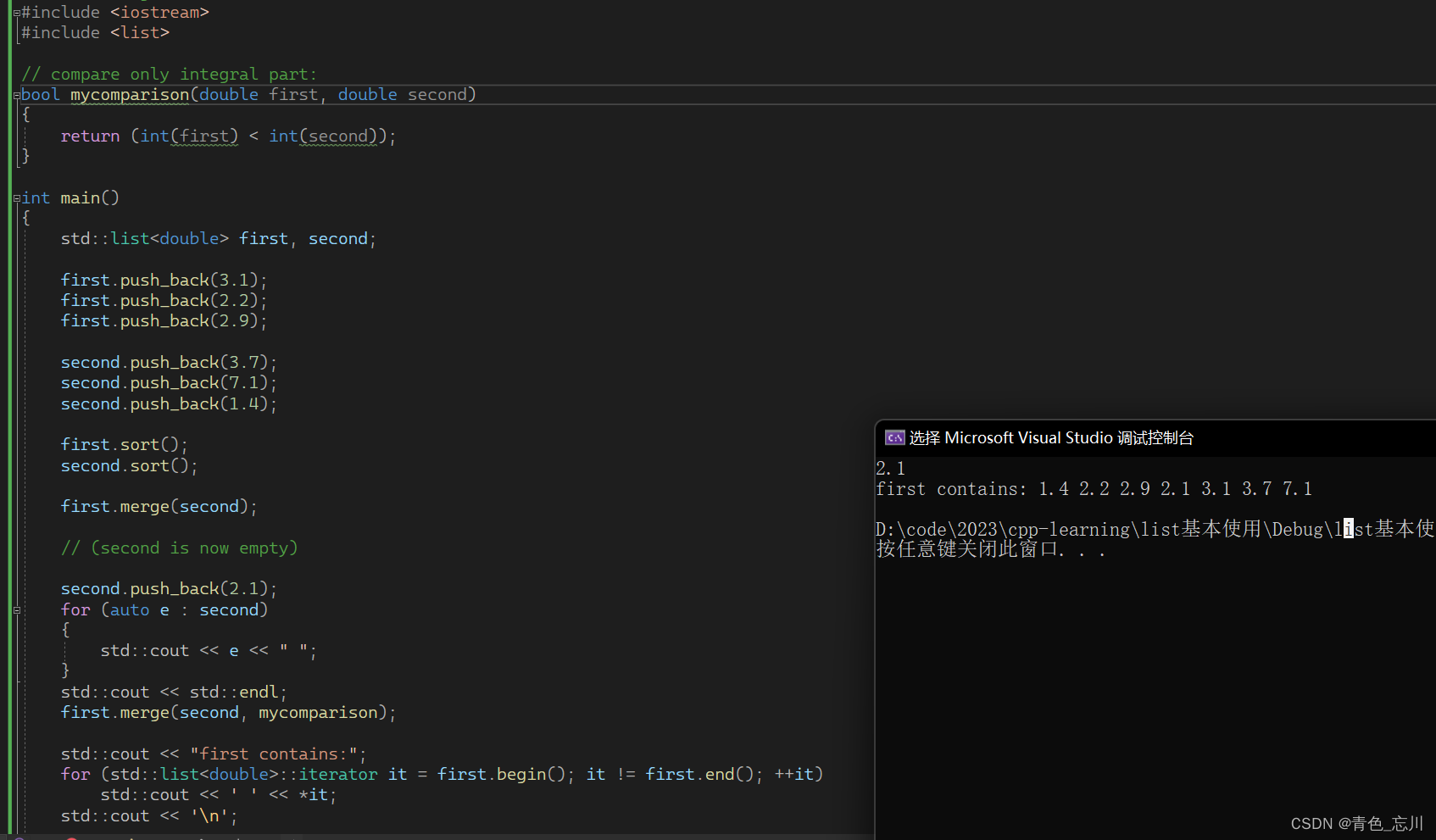
如下是运行结果,我们可以发现一些现象,首先是归并之后,second的结点都被归并走了,它里面也就没有数据了。
注意,在第二次合并中,函数mycomparison没有考虑2.1比2.2或2.9低,因为进行了强制类型转换,所以它被插入到它们之后,在3.1之前。
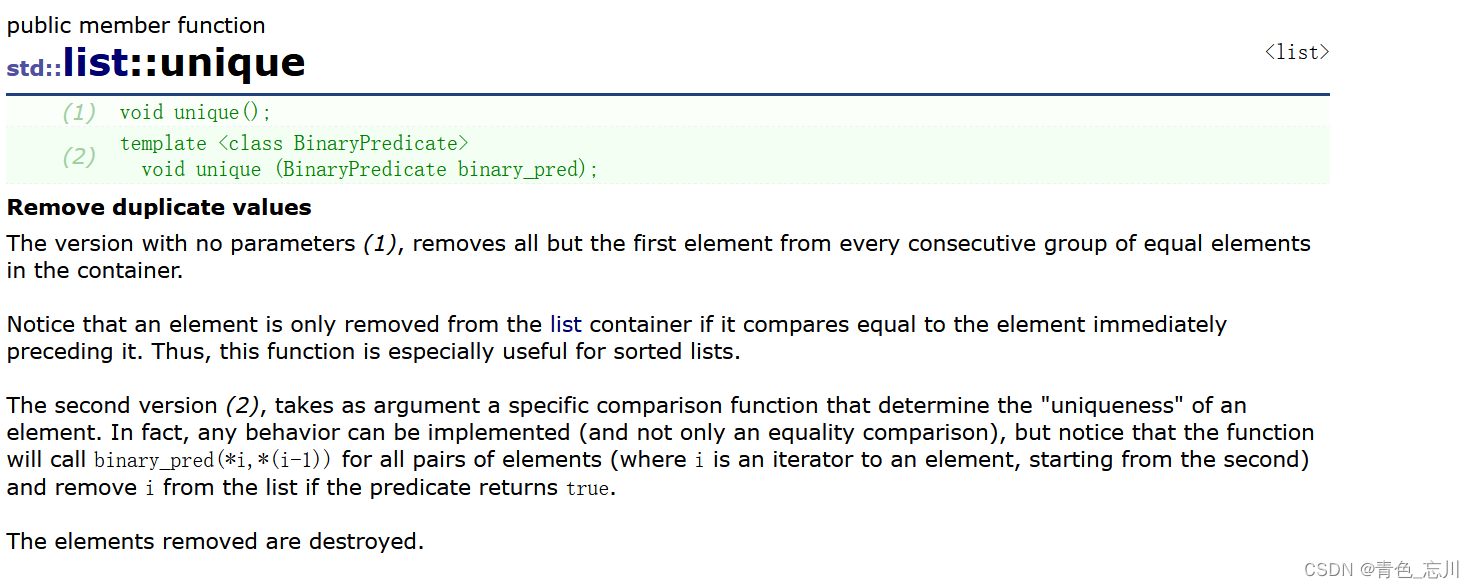
8.unique
这个函数的功能是去重,但是要注意首先得先进行排序,才能进行去重。否则效率极低
9.remove
remove其实相当于find+erase。先找到要移除的结点,然后删除掉。
 如下代码所示
如下代码所示
void testlist6()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
lt.remove(3);
lt.remove(10);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
找到3以后,移除掉这个结点,如果这个值不存在,即找不到,就什么也不做。

11.splice
这个是粘接、转移的意思,它可以将一个链表的某个结点拿走,交给另外一个链表

这三个函数的意思分别是,第一个函数是,将x链表全部转移到该链表的pos位置之前,第二个函数是将x链表的i结点转移到pos之前,第三个函数是,将x链表的某个迭代器区间,转移到pos之前。
如下代码所示,是该函数可以使用的情形
void testlist7()
{
list<int> lt1;
lt1.push_back(1);
lt1.push_back(2);
lt1.push_back(3);
list<int> lt2;
lt2.push_back(10);
lt2.push_back(20);
lt2.push_back(30);
list<int> lt3;
lt3.push_back(100);
lt3.push_back(200);
lt3.push_back(300);
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
for (auto e : lt2)
{
cout << e << " ";
}
cout << endl;
list<int>::iterator it = lt1.begin();
it++;
lt1.splice(it, lt2);
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
list<int>::iterator it3 = lt3.begin();
it3++;
lt1.splice(it, lt3, it3);
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
lt1.splice(it, lt3, lt3.begin(), lt3.end());
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
it = lt1.begin();
lt1.splice(it, lt1, ++lt1.begin(), lt1.end());
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
}
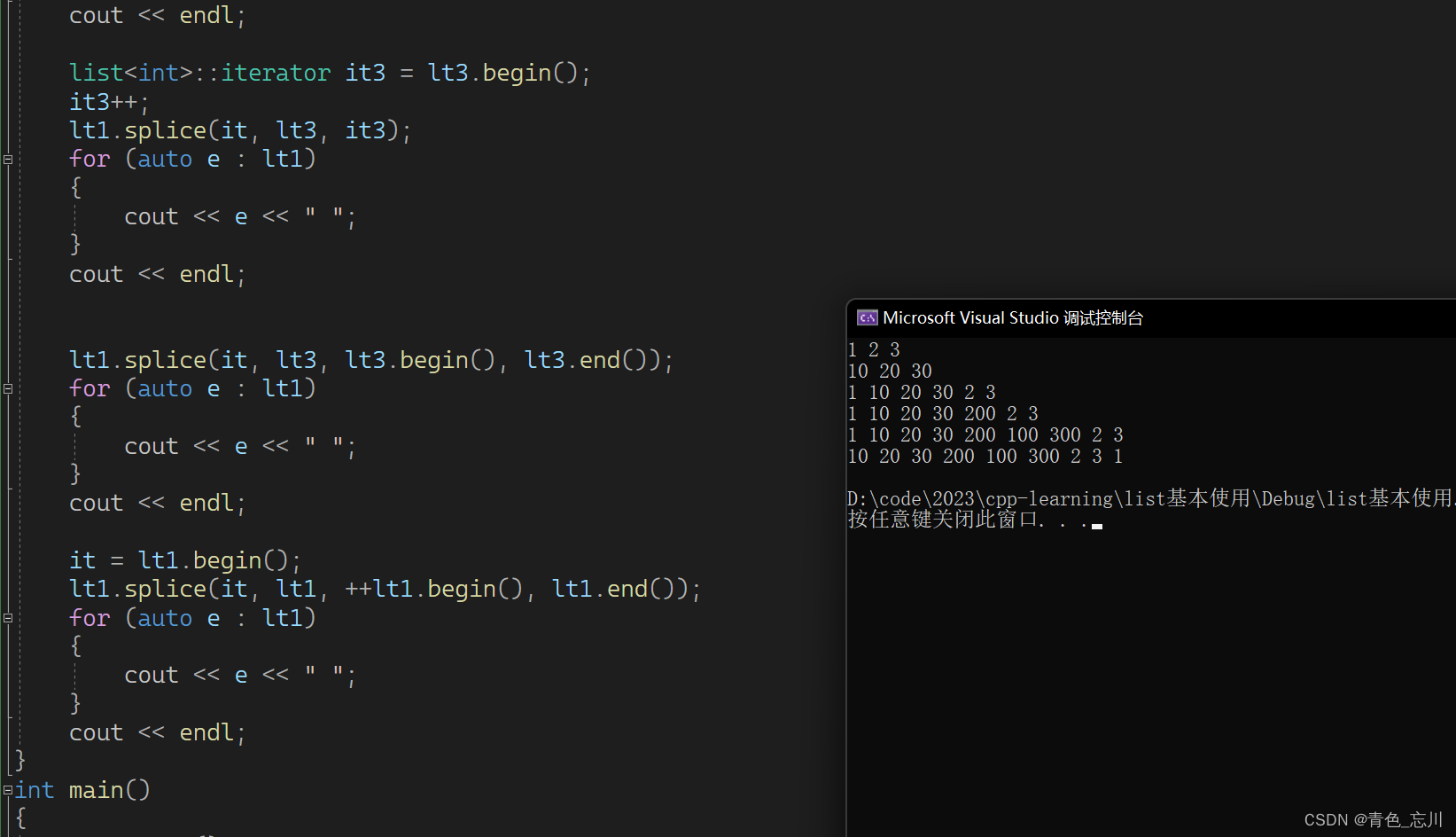
三、list基本使用完整代码
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<algorithm>
#include<list>
#include<vector>
using namespace std;
void testlist1()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
lt.push_front(7);
lt.push_front(8);
list<int>::iterator it = lt.begin();
while(it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
void testlist2()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int>::iterator it = lt.begin();
for (int i = 0; i < 5; i++)
{
it++;
}
lt.insert(it, 10);
it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
void testlist3()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int>::iterator pos = find(lt.begin(), lt.end(), 3);
lt.insert(pos, 300);
*pos *= 10;
list<int>::iterator it = lt.begin();
it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
//lt.erase(pos);
//*pos = 10;
it = lt.begin();
while (it != lt.end())
{
if (*it % 2 == 0)
{
it = lt.erase(it);
}
else
{
it++;
}
}
it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
void testlist4()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
lt.reverse();
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
reverse(lt.begin(), lt.end());
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
//sort(lt.begin(), lt.end());
}
void testlist5()
{
srand(time(0));
const int N = 1000000;
vector<int> v;
v.reserve(N);
list<int> lt1;
list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand();
lt2.push_back(e);
lt1.push_back(e);
}
// 拷贝到vector排序,排完以后再拷贝回来
int begin1 = clock();
// 先拷贝到vector
for (auto e : lt1)
{
v.push_back(e);
}
// 排序
sort(v.begin(), v.end());
// 拷贝回去
size_t i = 0;
for (auto& e : lt1)
{
e = v[i++];
}
int end1 = clock();
int begin2 = clock();
lt2.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
void testlist6()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
lt.remove(3);
lt.remove(10);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
void testlist7()
{
list<int> lt1;
lt1.push_back(1);
lt1.push_back(2);
lt1.push_back(3);
list<int> lt2;
lt2.push_back(10);
lt2.push_back(20);
lt2.push_back(30);
list<int> lt3;
lt3.push_back(100);
lt3.push_back(200);
lt3.push_back(300);
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
for (auto e : lt2)
{
cout << e << " ";
}
cout << endl;
list<int>::iterator it = lt1.begin();
it++;
lt1.splice(it, lt2);
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
list<int>::iterator it3 = lt3.begin();
it3++;
lt1.splice(it, lt3, it3);
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
lt1.splice(it, lt3, lt3.begin(), lt3.end());
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
it = lt1.begin();
lt1.splice(it, lt1, ++lt1.begin(), lt1.end());
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
testlist7();
return 0;
}
//
// list::merge
//#include <iostream>
//#include <list>
//
// compare only integral part:
//bool mycomparison(double first, double second)
//{
// return (int(first) < int(second));
//}
//
//int main()
//{
// std::list<double> first, second;
//
// first.push_back(3.1);
// first.push_back(2.2);
// first.push_back(2.9);
//
// second.push_back(3.7);
// second.push_back(7.1);
// second.push_back(1.4);
//
// first.sort();
// second.sort();
//
// first.merge(second);
//
// (second is now empty)
//
// second.push_back(2.1);
// for (auto e : second)
// {
// std::cout << e << " ";
// }
// std::cout << std::endl;
// first.merge(second, mycomparison);
//
// std::cout << "first contains:";
// for (std::list<double>::iterator it = first.begin(); it != first.end(); ++it)
// std::cout << ' ' << *it;
// std::cout << '\n';
//
// return 0;
//}
好了,本期内容就到这里了
如果对你有帮助的话,不要忘记点赞加收藏哦!!!
















 2544
2544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











