







在未开始介绍UCGUI Font之前,先讲解一些背景知识。
首先,计算机的“文本是画出来的”,事实确实是这样。所以我们必须为每一个字准备一个数组以保存他们的信息,而这些就叫做“字模”,这些字模的属性就如同图片的属性一样,分为点阵和矢量两种。
点阵是一点点画出来的,而矢量则是一笔一笔画出来。在保存诸如“王”、“中”、“大”等笔划简单的字时,把它作为矢量字来画速度较快,而且所需的存储容量较小,但在保存诸如“谢”、赢;“餐”等字形复杂的字时,恐怕采用点阵字要简单得多。矢量法还有一个点阵法不能达到的优点:矢量法容易实现汉字的放大缩小。
常见的点阵字有16 * 16 24 * 24等等,分别称之为16点阵、24点阵字。在谈及m*n点阵时,我们假想有一个横m格,竖n格的框子,每一格只有0和1的属性,当为1时,表示画笔工作,否则表示画笔提起。(当然,如果“逆其道而行之”,亦可得到反相的字)。下面为16*16的点阵图“中”。
1. char bit [16][16]=
2. {
3. {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
4. {0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0},
5. {0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0},
6. {0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0},
7. {0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0},
8. {0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0},
9. {0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0},
10. {0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0},
11. {0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0},
12. {0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0},
13. {0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0},
14. {0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0},
15. {0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0},
16. {0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0},
17. {0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0},
18. {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0}
19. };

而作为矢量表示的时候,则起存储是如下面这样的。

我们可以记录各笔划端点的坐标,并且在坐标前用1,0分别标记,表示画笔的工作状态(1=画线,0=不画)。则以上“中”字可以表示为:
0 1 4; 1 1 9; 0 1 4; 1 14 4; 0 13 3; 1 13 9; 0 1 9; 113 9; 0 8 1; 1 8 15;
这样符合笔划的先后顺序,但它完全可以用以下更简单的数据表示:0 14 4; 1 1 4; 1 1 9; 1 13 9; 113 3; 0 8 1; 1 8 15;
详细可参考:白乔原创:DOS时代-汉字的处理技术
其次,关于汉字的显示问题。在PC中文本文件中,汉字以机内码存储,每个汉字占用两个字节,第一个字节为区码,第二个字节为位码。为了区别ASCII码,区位码都是从A1开始,也就是说A1 A1代表着第一个区的第一个字。如果要得到区位码,则只要区位码减去A0 A0则可。
拿个汉字“房”举个例:“房”的机内码为16进制的B7BF,B7代表区码,BF代表位码,所以其区位码为B7 BFH – A0 A0H = 17 1FH,即16进制的23 31,即“房”的点阵位于第23个区的第31个字的位置。相当于在文件HZK16中的位置为 32 * ((23 -1)*94 + (31-1)) 后面的32个字节显示为“房”。(其中32代表着一个汉字占用32个字节,假如16*16按位存储0,1,则16*16/8 = 32。 94代表着一个区内从A1~FF位码可表达有94个汉字),下面为读取代码,ucgui显示的时候通过LCD DRAWBITMAP形式显示出来(SetPixel),具体可参照“计算机汉字显示原理(点阵字)”一文。


那么ucgui是怎么记录和显示这些字体的呢?
Ucgui提供了两种类型的字体,一种是等宽字体(Monospaced Font),,一种均衡字体(Proportional font)。(UCGUI在FONT目录先放着各种字模,以C原件的形式存放在数组中。汉字则保存在HZK16文件中,必须以rb形式打开)

在等宽字体中,因为所有的字都是同一宽度,所以所有的点阵存放在一个数组中,另外,需注意等宽字体的不仅宽度相同,高度也相同。
在UCGUI中,等宽字体相对应着结构体是GUI_FONT_MONO,其中GUI_FONT_TRANSINFO为不止有ASCII,则要有转换



而对于均衡字体,因为每个字体都有独自的宽度,所以需要单独的数组来定义每个字。
在UCGUI中相对应的结构体是GUI_FONT_PROP

其中还需要另一个结构存储字符信息GUI_CHARINFO

另外,其中的pNext指针是指向下一个字模数组。

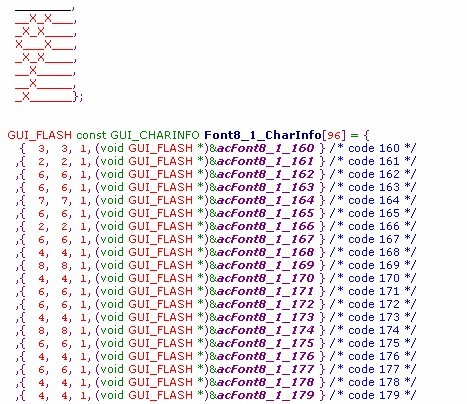


然后又怎么显示呢?
在GUI_FONT结构体中已经注册了显示函数,根据字体的不同,显示函数显示不同,但其原理都是相同,只是根据存储,查找方式不同。
等宽字体显示的函数为GUIMONO_DispChar(U16P c),根据GUI_FONT_MONO结构形式查找,具体的查找显示是这样的:
得出GUI_FONT_MONO结构体,然后根据来的ASCII码看是否在FirstChar和LastChar之间,如果在范围内,则把Data通过DrawBitmap显示出来,如果不在范围内,则查找是不是有外带的转化信息。


对均衡字体来说,则根据GUI_FONT_PROP,和pNext指针找出起字符所在PROP,然后也是通过DrawBitmap方式显示。

http://blog.csdn.net/jacklam200/article/details/5980392















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









