







导读
前面几章我们以经介绍了怎么批量对excel和ppt操作今天我们说说对word文档的批量操作
应用
python-docx允许您创建新文档以及对现有文档进行更改。实际上,它只允许您对现有文档进行更改;只是如果您从一个没有任何内容的文档开始,一开始可能会觉得您是从头开始创建一个文档。
这个特性是一个强大的特性。文档的外观很大程度上取决于删除所有内容时留下的部分。样式、页眉和页脚等内容与主要内容分开包含,允许您在起始文档中进行大量自定义,然后出现在您生成的文档中。
让我们逐步完成创建文档的步骤,一次创建一个示例,从您可以对文档执行的两项主要操作开始,将其打开并保存。
我这里做一个简单的演示
还是先定义合并单元格函数,以便后续多次调用。由于处理Word中表格的代码与处理Excel不同,所以函数也要做微调。主要变化就是合并的函数表达,对于word中的表格,表达式是table.cell(row1,col1).merge(table.cell(row2,col2)),意思是将第row1行col1列到row2行col2列之间的表格合并(row2,col2要分别大于等于row1和col1)。需要注意的是cell(0,0)表示第一行第一列的单元格,以此类推。如下函数是在例28的基础上修改的。
#定义合并单元格的函数
def Merge_cells(table,target_list,start_row,col):
'''
table: 是需要操作的表格
target_list: 是目标列表,即含有重复数据的列表
start_row: 是开始行,即表格中开始比对数据的行(需要将标题除开)
col: 是需要处理数据的列
'''
start = 0 #开始行计数
end = 0 #结束行计数
reference = target_list[0] #设定基准,以列表中的第一个字符串开始
for i in range(len(target_list)): #遍历列表
if target_list[i] != reference: #开始比对,如果内容不同执行如下
reference = target_list[i] #基准变成列表中下一个字符串
end = i - 1
table.cell(start+start_row,col).merge(table.cell(end+start_row,col))
start = end + 1
if i == len(target_list) - 1: #遍历到最后一行,按如下操作
end = i
table.cell(start+start_row,col).merge(table.cell(end+start_row,col))
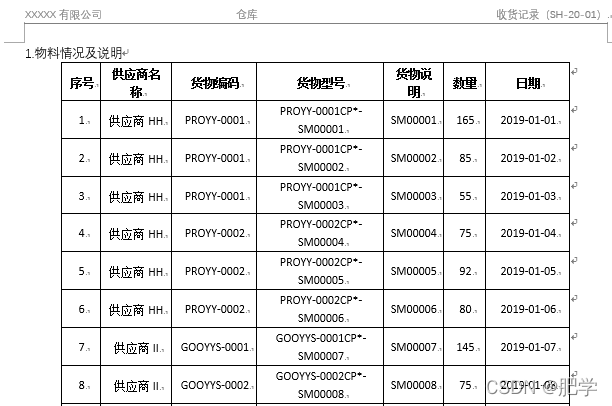
然后需要读取word中相应表格里的数据,并提取出来,以便作为是否合并的判断基础。使用Document打开word文档,先查看一下其中表格的个数,以便我们锁定要处理的表格。由于word里面可能有隐藏表格,或者一个表格中有一段去掉了边框,让人看起来像是两个表格,直接在word中去数表格个数有时会不靠谱。通过len(doc.tables)看到,这个文档里面有2个表格。打开word文档,我们可以看到要处理的表格是第一个,即doc.tables[0]。如果情况较为复杂,我们可以打印表格中第一行单元格的内容进一步确认是否是我们需要处理的表格。确认好表格的序号后,就可以开始读取内容了。
from docx import Document
doc = Document("收货记录.docx")
print("这个工作表有 {} 个表格。\n".format(len(doc.tables))) #查看表格中的个数,以便锁定我们要处理的表格
print("第一个表格的第一行的单元格中的内容如下:")
for i in doc.tables[0].rows[0].cells: #读取第一个表格的第一行的单元格中的内容
print(i.text)
第一个表格的第一行的单元格中的内容如下:
序号
供应商名称
货物编码
货物型号
货物说明
数量
日期
表格:
doc.tables[0].rows[0].cells[0].text
'序号'
接着:
#读取word文档中的第一个表格的第二和第三列除标题和尾部总数行的数据
doc = Document("收货记录.docx")
table = doc.tables[0] #已确定是第一个表格,其索引是0
supplier = [] #存储供应商名称
pn = [] #存储物料编码
max_row = len(table.rows) #获取第最大一行
print("表格共有{}行".format(max_row))
#读取第二行到29行,第2,3列中的数据
for i in range(1,max_row-1):
supplier_name = table.rows[i].cells[1].text #cells[1]指表格第二列
supplier.append(supplier_name)
for i in range(1,max_row-1):
material_pn = table.rows[i].cells[2].text #cells[2]指表格第三列
pn.append(material_pn)
print("获取到{}个供应商名称,{}个物料编码。".format(len(supplier),len(pn)))
表格共有30行
获取到28个供应商名称,28个物料编码。
Merge_cells(table,supplier,1,1) #开始合并行为2,索引为1;供应商名称是在2列,索引为1
Merge_cells(table,pn,1,2) #开始合并行为2,索引为1;物料编码是在3列,索引为2
doc.save("检查.docx")
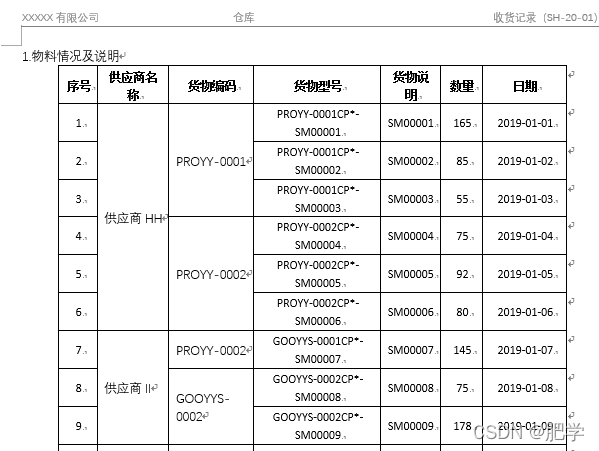
到这一步,合并单元格算是完成了,但结果如下图所示,原单元格中的内容全部集中在一起,造成了重复内容。我们需要重写这些单元格以覆盖掉重复的内容,即可得到我们想要的结果。
结果:
细节介绍
关于python-docx库
链接:传送门
这里有关于操作的详细介绍
特别介绍
📣小白练手专栏,适合刚入手的新人欢迎订阅编程小白进阶
📣python有趣练手项目里面包括了像《机器人尬聊》《恶搞程序》这样的有趣文章,还有关于python自动化办公的库介绍可以让你快乐学python练手项目专栏
📣另外想学JavaWeb进厂的同学可以看看这个专栏:传送们
📣这是个冲刺大厂面试专栏还有算法比赛练习我们一起加油 上岸之路
点击直接资料领取
这里有python,Java学习资料还有有有趣好玩的编程项目,更有难寻的各种资源。反正看看也不亏。
















 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











