







GPU中我们通常使用GDDR5内存,它的memory channel宽度是32bit,和DDR3/DDR4 不同(它们的memory channel宽度为64位),但是GDDR5可以实现更多的memory channel,比如一些高阶显卡,它的memory channel通常为16,在前篇教程中,我们知道,Intel i7的cpu端memory channel才为3。近期,一些高级显卡也开始使用HBM内存,HBM内存具有更高的memory channel宽度,通常为128bit,但是相对来说它的有更大的时延。在一些显卡中,也会使用DDR3memory, 比如AMD一些APU显卡。
DDR3 内存DIMM内为8个bank,DDR4通常也为8个bank,但也有16个bank的DDR4,DDR4可以实现比DDR3更高的频率。GDDR5和HBM内存DIMM内则为16个bank,注意HBM内存的Burst length为4,HBM介绍可以参考:http://www.cnblogs.com/mikewolf2002/p/5198271.html
GPU3D渲染通常需要更高的memory带宽,所以memory channel数目会比较多,下面表格给出一些例子。
memory channel宽度和data rate通常对每种类型memory是固定的,mclk和channel number可以变化。
memory pin width = memory channel width * memory channel number, 它是memory bus的位宽。
带宽则为memory能够达到的最大吞吐宽度,它的公式为: memory channel widht/8 * data rate * mclk * channel number /1000, 除以8是把位转化成字节,除以1000,则是转化成GB。从表中,我们可以看到HBM具有很高的带宽。

在上一篇教程中,我们知道CPU或GPU访问的一段buffer,它会保存在DDR memory中,通过特定的地址,可以在memory中读写这些数据。
下面我们来了解一下这些知识, 比如1024KB的数据,它是怎么存入内存中的呢?
GPU和video memory连接通常如下图所示,这里我们把cache0连接到memory chanell 0,……,但实际上的cache和memory channel的连接是有物理设计决定的,通常把cache连接到离它最近的channel,而且如何连接是可以通过寄存器设定的。

比如GPU中的DMA引擎要把1024KB的buffer数据写入物理地址为0的内存中。实际上它并不是把逻辑上连续的buffer全部写入DIMM0中,而是存在一个间隔(interleave) 概念,比如间隔为256Byte,则buffer 0-255的字节被放入cache0中,再通过memory channel 0,放入到 DIMM0中, 256-511的数据被放入cache1 中,依次类推,当最后一个cache中被放入数据后,接下来的数据又会被放到cache0,如此循环,完成所有的数据写入操作。这样做可以是的memory channel并行工作,从而提高memory读写效率。
一个完整的memory物理地址描述大致如下,包括interleave位,channel地址位,bank位,行地址位,列地址位以及rank位。连续的物理地址在实际的DDR中存储是不连续的,具体如何存储,完全是由memory地址库决定的,这样做是为了使得bank,channel等并行操作,提高memory读写效率
![]()
对于一块surface(通常指一块buffer,或者纹理等等),它在内存中的存储顺序如何?通常有两种方式,顺序存储,这种buffer通常叫做线性buffer,另外对于纹理,它的存储方式通常是采用zig-zag的tile方式,因为纹理经常要做滤波操作,需要读取不同行的数据,如果采用线性方式,要频繁切换到不同行读取,memory效率会很低。
下面左边是线性buffer的示例图,右边则是纹理的示例图。


我写了一个简单opengl程序来演示线性buffer和tilebuffer,按上下方向键来显示连续的地址,l,t切换线性地址或者tile地址。

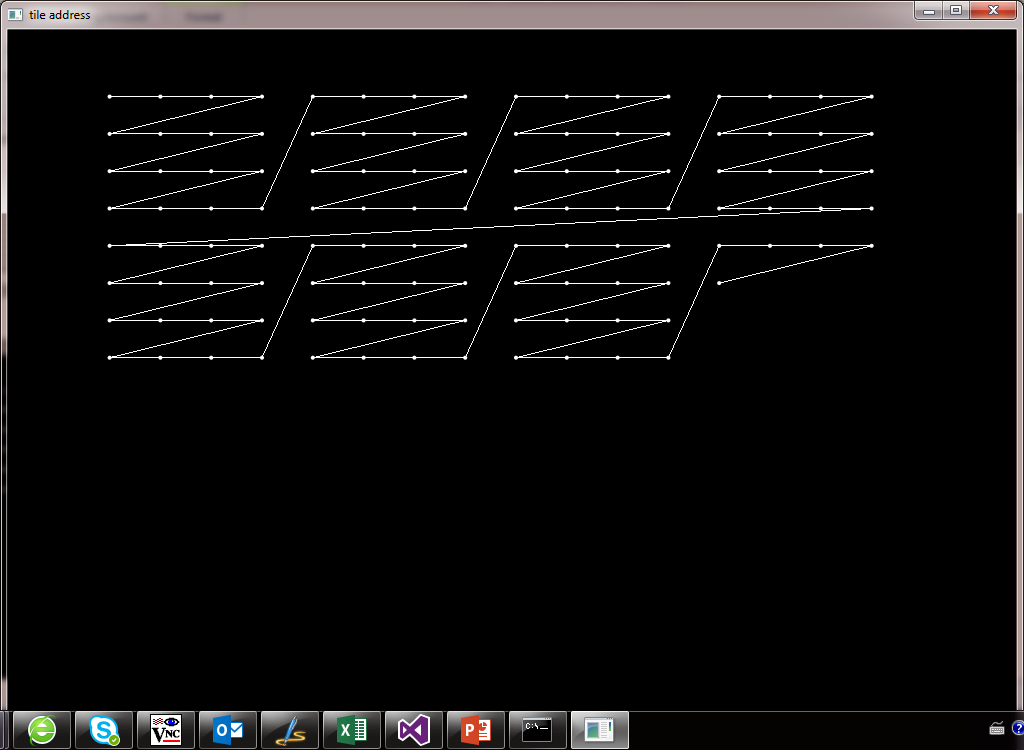
代码如下;
#include <stdio.h>
#include <GL/glew.h>
#include <GL/freeglut.h>
//顶点缓冲对象, vertex buffer object
GLuint VBO;
static int rendercount = 1;
struct Vector3f
{
float x;
float y;
float z;
Vector3f()
{
}
Vector3f(float _x, float _y, float _z)
{
x = _x;
y = _y;
z = _z;
}
};
const int meshx = 16;
const int meshy = 16;
//假设1个元素1个size,只是为了显示方便
static int pitch = meshy * 1;
//tile的宽高
static int th = 4;
static int tw = 4;
Vector3f Vertices[meshx * meshy];
static void RenderSceneCB()
{
//每帧渲染前clear color buffer为黑色
glClear(GL_COLOR_BUFFER_BIT);
//开启顶点属性,0意思是顶点的第一个属性,顶点的第一个属性必须是位置。
glEnableVertexAttribArray(0);
//再次绑定VBO,每次渲染前再次绑定这儿可以改变target
glBindBuffer(GL_ARRAY_BUFFER, VBO);
//void glVertexAttribPointer( GLuint index, GLint size, GLenum type, GLboolean normalized, GLsizei stride,const GLvoid * pointer);
//index 指定要修改的顶点属性的索引值
// size 指定每个顶点属性的元素数量。必须为1、2、3或者4。初始值为4。(如position是由3个(x, y, z)组成,而颜色是4个(r, g, b, a))
// type 指定数组中每个元素的数据类型。可用的符号常量有GL_BYTE, GL_UNSIGNED_BYTE, GL_SHORT, GL_UNSIGNED_SHORT, GL_FIXED, 和 GL_FLOAT,初始值为GL_FLOAT。
// normalized 指定当被访问时,固定点数据值是否应该被归一化(GL_TRUE)或者直接转换为固定点值(GL_FALSE)。
// stride 指定连续顶点属性之间的偏移量。如果为0,那么顶点属性会被理解为:它们是紧密排列在一起的。初始值为0。
// pointer 指定第一个元素在数组的第一个顶点属性中的偏移量。该数组与GL_ARRAY_BUFFER绑定,储存于缓冲区中。初始值为0;
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 0, 0);
//GL_APICALL void GL_APIENTRY glDrawArrays (GLenum mode, GLint first, GLsizei count);
//mode,绘制方式,OpenGL2.0以后提供以下参数:GL_POINTS、GL_LINES、GL_LINE_LOOP、GL_LINE_STRIP、GL_TRIANGLES、GL_TRIANGLE_STRIP、GL_TRIANGLE_FAN。
//first,从数组缓存中的哪一位开始绘制,一般为0。
//count,数组中顶点的数量。
//没有指定颜色属性,默认的颜色输出为白色
glDrawArrays(GL_POINTS, 0, rendercount);
glDrawArrays(GL_LINE_STRIP, 0, rendercount);
//关闭顶点属性,以免引起未知的错误
glDisableVertexAttribArray(0);
//交换前后缓冲,在屏幕上显示出渲染的当前帧图像
glutSwapBuffers();
}
static void SpecialKeyboardCB(int Key, int x, int y)
{
//上下方向键增加减少画的点数
switch (Key)
{
case GLUT_KEY_UP:
{
rendercount++;
if (rendercount > meshx * meshy)
rendercount = meshx * meshy;
}
break;
case GLUT_KEY_DOWN:
{
rendercount--;
if (rendercount < 1)
rendercount = 1;
}
break;
}
RenderSceneCB();
}
static void KeyboardCB(unsigned char Key, int x, int y)
{
switch (Key) {
case 'l':
{
rendercount = 1;
//线性地址
int i, j;
for (i = 0; i < meshx; i++)
{
for (j = 0; j < meshy; j++)
{
float x, y, z;
//缩放到[-0.8,0.8]的范围
y = (1.0 - 2.0 *i / meshx)*0.8;
x = (-1.0 + 2.0 *j / meshy)*0.8;
z = 0.0;
Vertices[i*meshy + j] = Vector3f(x, y, z);
}
}
}
break;
case 't':
{
rendercount = 1;
//tile 地址
int i, j, k;
for (i = 0; i < meshx; i++)
{
for (j = 0; j < meshy; j++)
{
float x, y, z;
//ts = tw*th = 4*4=16
k = tw*th * ((i / th)*(pitch / tw) + (j / tw)) + i % th * tw + j % tw;
//缩放到[-0.8,0.8]的范围
y = (1.0 - 2.0 *i / meshx)*0.8;
x = (-1.0 + 2.0 *j / meshy)*0.8;
z = 0.0;
Vertices[k] = Vector3f(x, y, z);
}
}
}
break;
case 'q':
exit(0);
}
//再次绑定buffer
glBindBuffer(GL_ARRAY_BUFFER, VBO);
//当缓存初始化之后,你可以使用glBufferData()将数据拷贝到缓存对象
//第一个参数target可以为GL_ARRAY_BUFFER或GL_ELEMENT_ARRAY。size为待传递数据字节数量。第三个参数为源数据数组指针,如data为NULL,则VBO仅仅预留给定数据大小的内存空间。
//最后一个参数usage标志位VBO的另一个性能提示,它提供缓存对象将如何使用:static、dynamic或stream、与read、copy或draw。
glBufferData(GL_ARRAY_BUFFER, sizeof(Vertices), Vertices, GL_STATIC_DRAW);
RenderSceneCB();
}
static void InitializeGlutCallbacks()
{
glutDisplayFunc(RenderSceneCB);
//增加了对特殊按键的支持
glutSpecialFunc(SpecialKeyboardCB);
//增加键盘
glutKeyboardFunc(KeyboardCB);
}
static void CreateVertexBuffer()
{
//创建缓存对象并且返回缓存对象的标示符,
//第一个参数为需要创建的缓存数量,第二个为用于存储单一ID或多个ID的GLuint变量或数组的地址
glGenBuffers(1, &VBO);
//当缓存对象创建之后,在使用缓存对象之前,我们需要将缓存对象连接到相应的缓存上。glBindBuffer()有2个参数:target与buffer
//target告诉VBO该缓存对象将保存顶点数组数据还是索引数组数据:GL_ARRAY_BUFFER或GL_ELEMENT_ARRAY。任何顶点属性,如顶点坐标、纹理坐标、法线与颜色分量数组都使用GL_ARRAY_BUFFER。
//用于glDraw[Range]Elements()的索引数据需要使用GL_ELEMENT_ARRAY绑定。注意,target标志帮助VBO确定缓存对象最有效的位置,如有些系统将索引保存AGP或系统内存中,将顶点保存在显卡内存中。
//当第一次调用glBindBuffer(),VBO用0大小的内存缓存初始化该缓存,并且设置VBO的初始状态,如用途与访问属性。
glBindBuffer(GL_ARRAY_BUFFER, VBO);
//当缓存初始化之后,你可以使用glBufferData()将数据拷贝到缓存对象
//第一个参数target可以为GL_ARRAY_BUFFER或GL_ELEMENT_ARRAY。size为待传递数据字节数量。第三个参数为源数据数组指针,如data为NULL,则VBO仅仅预留给定数据大小的内存空间。
//最后一个参数usage标志位VBO的另一个性能提示,它提供缓存对象将如何使用:static、dynamic或stream、与read、copy或draw。
glBufferData(GL_ARRAY_BUFFER, sizeof(Vertices), Vertices, GL_STATIC_DRAW);
}
int main(int argc, char** argv)
{
//初始化glut
glutInit(&argc, argv);
//使用双缓冲,color缓冲像素格式用RGBA格式
glutInitDisplayMode(GLUT_DOUBLE | GLUT_RGBA);
//窗口大小及位置
glutInitWindowSize(1024, 1024);
glutInitWindowPosition(100, 100);
//窗口标题
glutCreateWindow("tile address");
InitializeGlutCallbacks();
// 注意:必须在glut初始化后在调用glew初始化
GLenum res = glewInit();
if (res != GLEW_OK) {
fprintf(stderr, "Error: '%s'\n", glewGetErrorString(res));
return 1;
}
//下面四行代码,设置点的大小,以及启动alpha blend以及多采样,这样可以画圆形的点
glEnable(GL_POINT_SMOOTH);
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
//设置点的size,enable msaa 点边缘比较光滑。
glPointSize(4.0f);
bool msaa = true;
if (msaa)
{
glEnable(GL_MULTISAMPLE_ARB);
printf("msaa on\n");
}
else
{
printf("msaa off\n");
glDisable(GL_MULTISAMPLE_ARB);
}
//设置清除背景颜色为黑色,像素格式RGBA ,该函数指定用来清除color buffer的背景颜色
glClearColor(0.0f, 0.0f, 0.0f, 0.0f);
int i, j, k;
//tile address
//byte address = f(x,y) = surface_base +element_width * {ts * [ int(y/th)*pitch/tw + int(x/tw)] + [y%th*tw+x%tw]}
for (i = 0; i < meshx; i++)
{
for (j = 0; j < meshy; j++)
{
float x, y, z;
//ts = tw*th = 4*4=16
k = tw*th * ((i /th)*( pitch / tw) + (j / tw)) + i % th * tw + j % tw;
//缩放到[-0.8,0.8]的范围
y = (1.0 - 2.0 *i / meshx)*0.8;
x = (-1.0 + 2.0 *j / meshy)*0.8;
z = 0.0;
Vertices[k] = Vector3f(x, y, z);
}
}
//创建顶点缓冲
CreateVertexBuffer();
glutMainLoop();
return 0;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









