







二、基本的机器学习算法:
1. 线性回归算法 Linear Regression
回归分析(Regression Analysis)是统计学的数据分析方法,目的在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型以便观察特定变量来预测其它变量的变化情况。
线性回归算法(Linear Regression)的建模过程就是使用数据点来寻找最佳拟合线。公式,y = m_x + c,其中 y 是因变量,x 是自变量,利用给定的数据集求 m 和 c 的值。
线性回归又分为两种类型,即_ 简单线性回归(simple linear regression),只有 1 个自变量;*多变量回归(multiple regression),至少两组以上自变量。
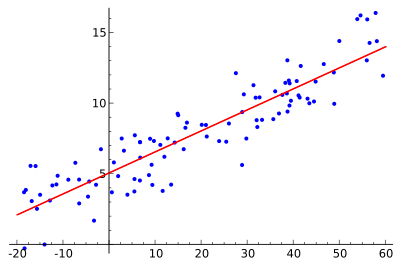
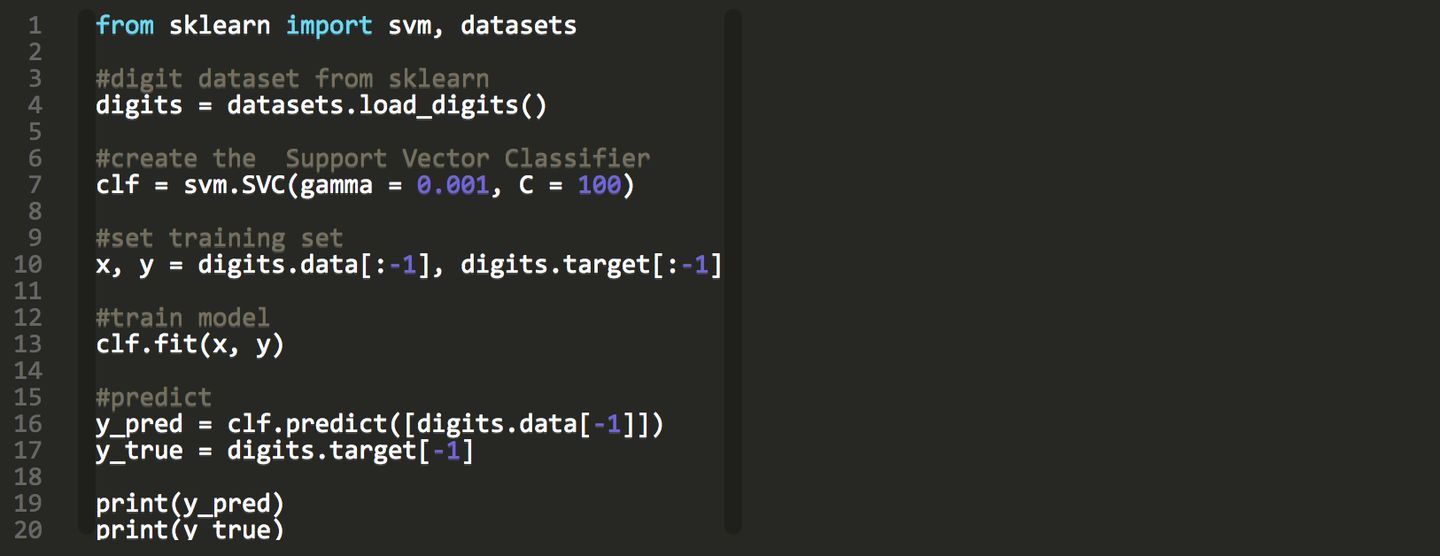
下面是一个线性回归示例:基于 Python scikit-learn 工具包描述。
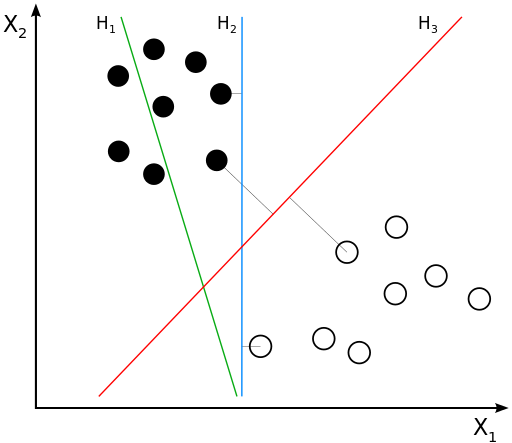
2. 支持向量机算法(Support Vector Machine,SVM)
支持向量机/网络算法(SVM)属于分类型算法。SVM模型将实例表示为空间中的点,将使用一条直线分隔数据点。需要注意的是,支持向量机需要对输入数据进行完全标记,仅直接适用于两类任务,应用将多类任务需要减少到几个二元问题。
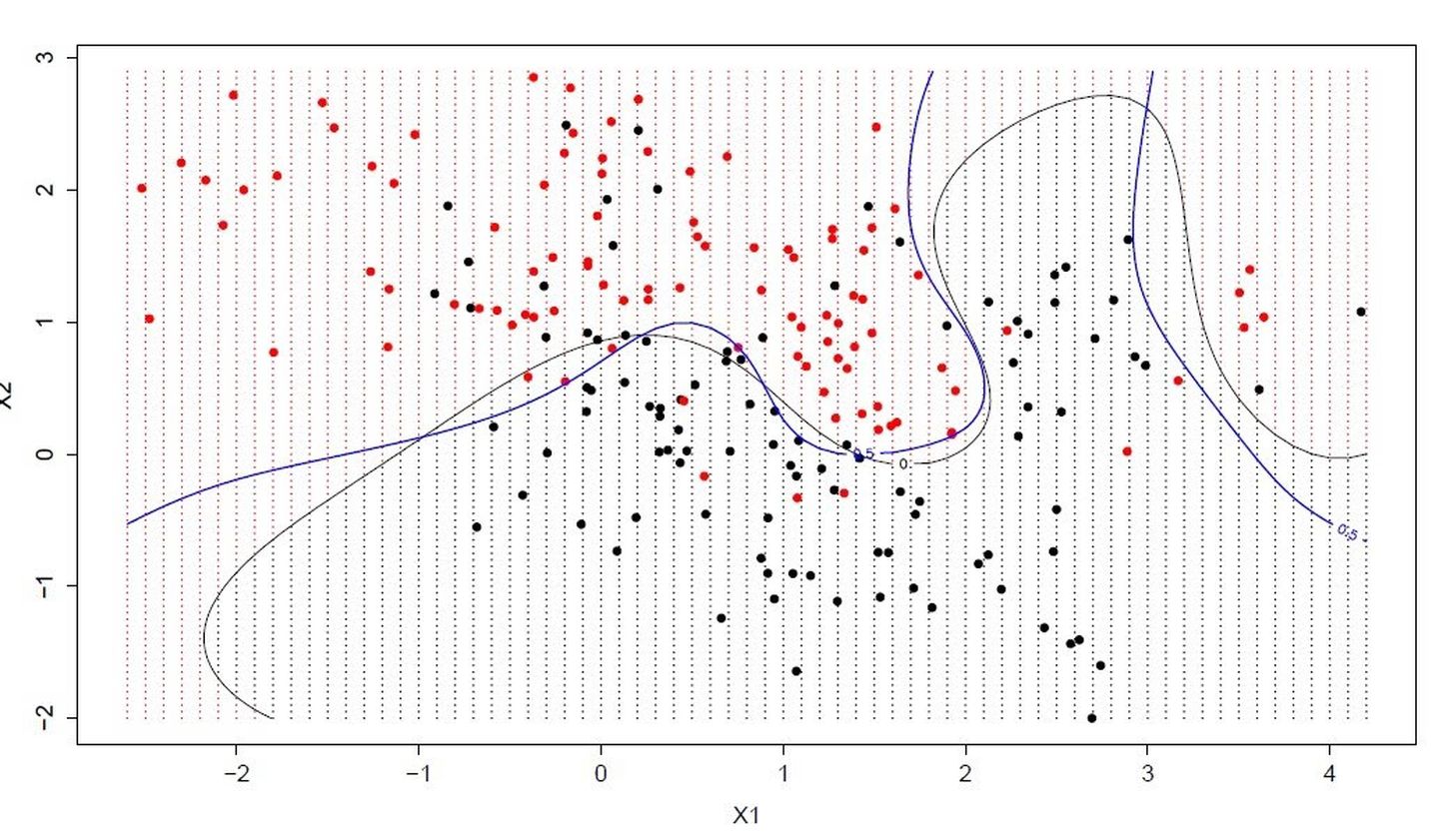
3. 最近邻居/k-近邻算法 (K-Nearest Neighbors,KNN)
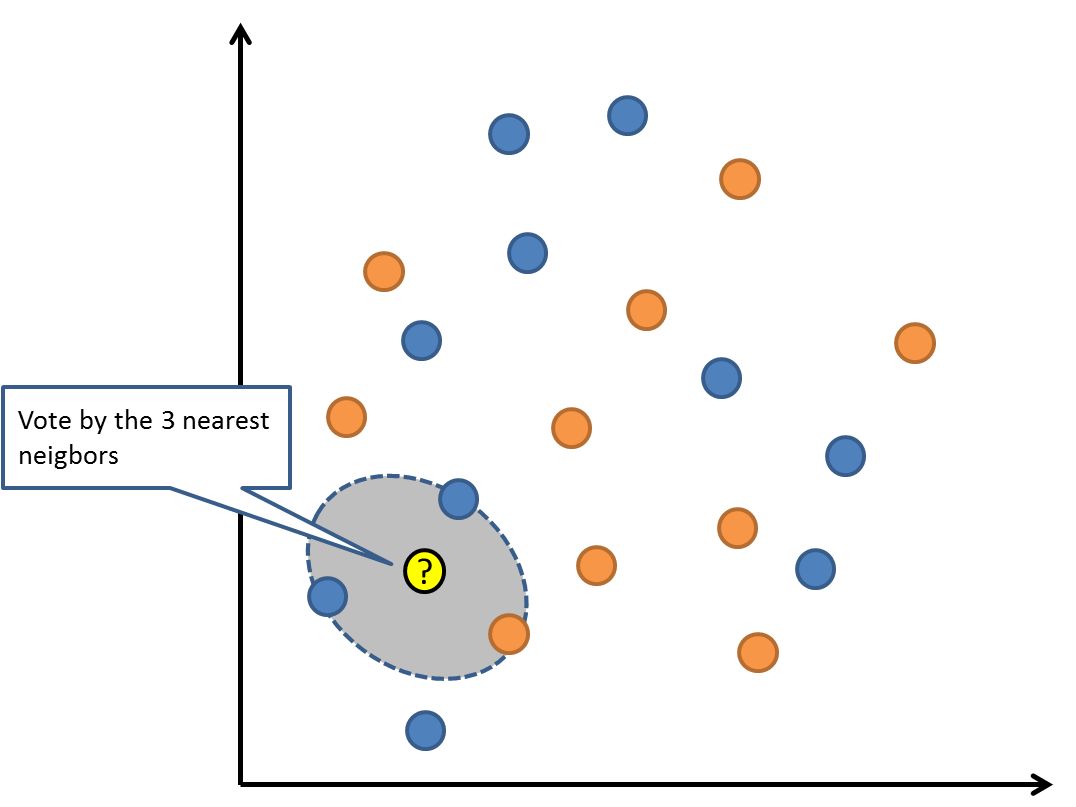
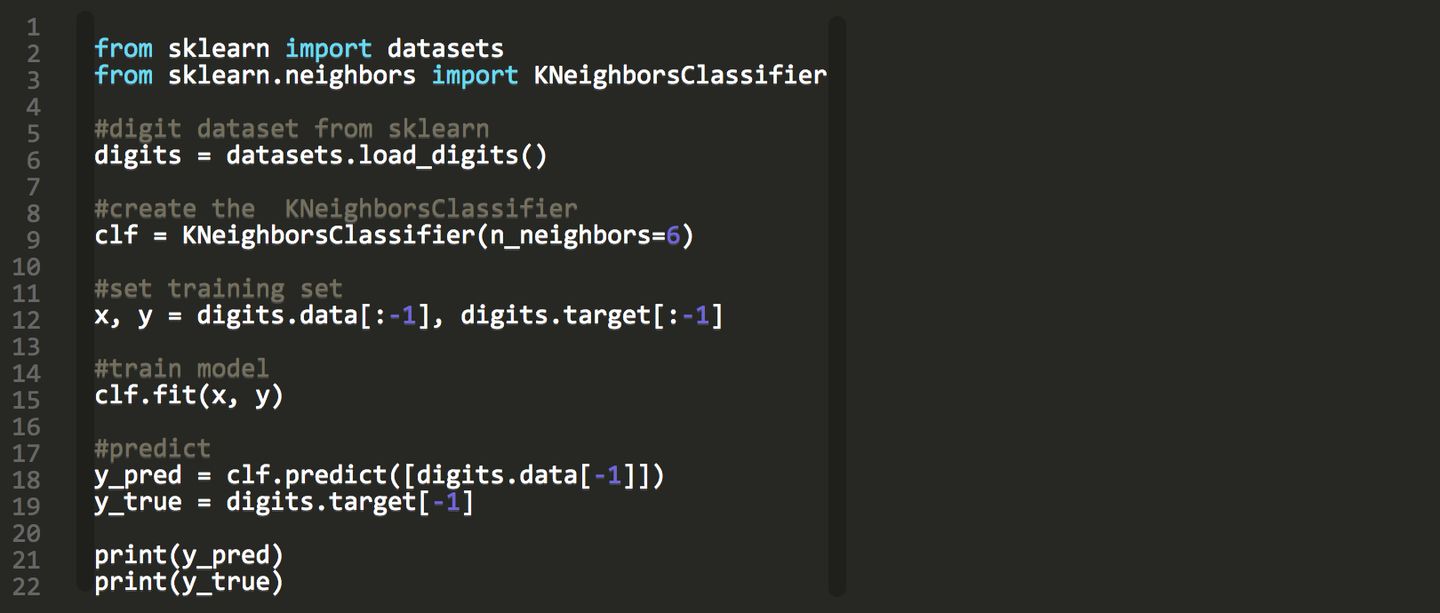
KNN算法是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。用最近的邻居(k)来预测未知数据点。k 值是预测精度的一个关键因素,无论是分类还是回归,衡量邻居的权重都非常有用,较近邻居的权重比较远邻居的权重大。
KNN 算法的缺点是对数据的局部结构非常敏感。计算量大,需要对数据进行规范化处理,使每个数据点都在相同的范围。

延伸:KNN 的一个缺点是依赖于整个训练数据集,学习向量量化(Learning Vector Quantization,LVQ)是一种监督学习的人神经网络算法,允许你选择训练实例。LVQ 由数据驱动,搜索距离它最近的两个神经元,对于同类神经元采取拉拢,异类神经元采取排斥,最终得到数据的分布模式。如果基于 KNN 可以获得较好的数据集分类效果,利用 LVQ 可以减少存储训练数据集存储规模。典型的学习矢量量化算法有LVQ1、LVQ2和LVQ3,尤以LVQ2的应用最为广泛。
4. 逻辑回归算法 Logistic Regression
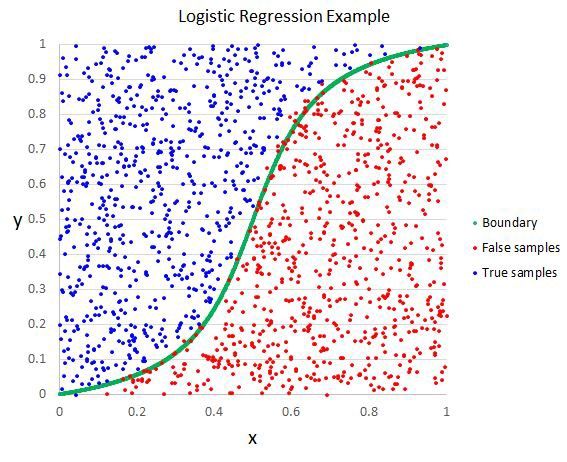
逻辑回归算法(Logistic Regression)一般用于需要明确输出的场景,如某些事件的发生(预测是否会发生降雨)。通常,逻辑回归使用某种函数将概率值压缩到某一特定范围。
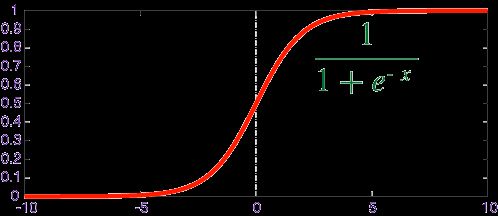
例如,Sigmoid 函数(S 函数)是一种具有 S 形曲线、用于二元分类的函数。它将发生某事件的概率值转换为 0, 1 的范围表示。
Y = E ^(b0+b1 x)/(1 + E ^(b0+b1 x ))
以上是一个简单的逻辑回归方程,B0,B1是常数。这些常数值将被计算获得,以确保预测值和实际值之间的误差最小。
5. 决策树算法 Decision Tree
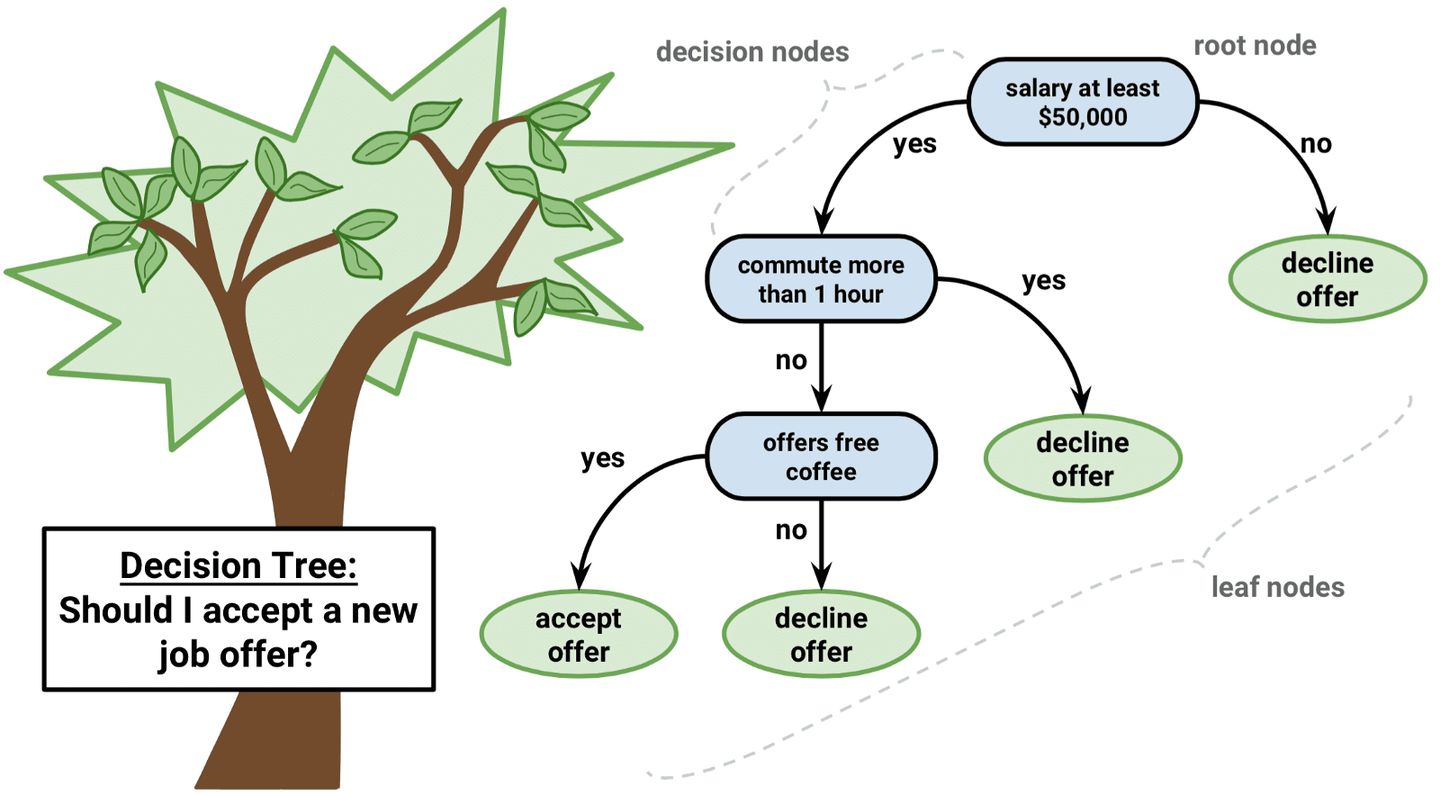
决策树(Decision tree)是一种特殊的树结构,由一个决策图和可能的结果(例如成本和风险)组成,用来辅助决策。机器学习中,决策树是一个预测模型,树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,通常该算法用于解决分类问题。
一个决策树包含三种类型的节点:
-
决策节点:通常用矩形框来表示
-
机会节点:通常用圆圈来表示
-
终结点:通常用三角形来表示
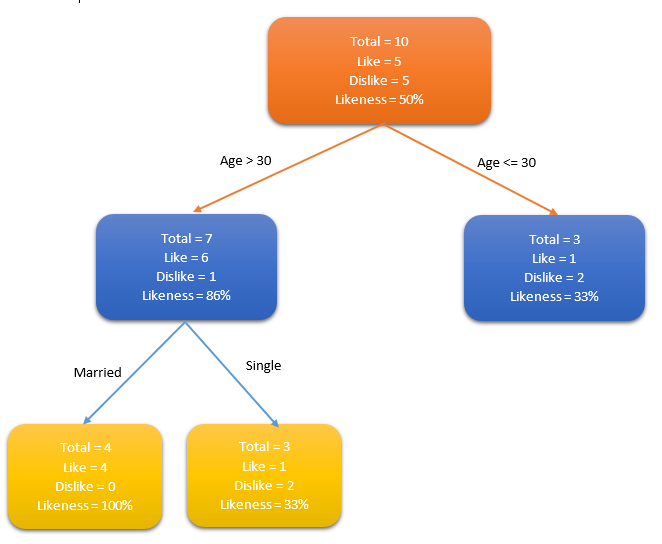
简单决策树算法案例,确定人群中谁喜欢使用信用卡。考虑人群的年龄和婚姻状况,如果年龄在30岁或是已婚,人们更倾向于选择信用卡,反之则更少。
通过确定合适的属性来定义更多的类别,可以进一步扩展此决策树。在这个例子中,如果一个人结婚了,他超过30岁,他们更有可能拥有信用卡(100% 偏好)。测试数据用于生成决策树。
注意:对于那些各类别样本数量不一致的数据,在决策树当中信息增益的结果偏向于那些具有更多数值的特征。
6. k-平均算法 K-Means
k-平均算法(K-Means)是一种无监督学习算法,为聚类问题提供了一种解决方案。
K-Means 算法把 n 个点(可以是样本的一次观察或一个实例)划分到 k 个集群(cluster),使得每个点都属于离他最近的均值(即聚类中心,centroid)对应的集群。重复上述过程一直持续到重心不改变。

7. 随机森林算法 Random Forest
随机森林算法(Random Forest)的名称由 1995 年由贝尔实验室提出的random decision forests 而来,正如它的名字所说的那样,随机森林可以看作一个决策树的集合。
随机森林中每棵决策树估计一个分类,这个过程称为“投票(vote)”。理想情况下,我们根据每棵决策树的每个投票,选择最多投票的分类。
总结
就写到这了,也算是给这段时间的面试做一个总结,查漏补缺,祝自己好运吧,也希望正在求职或者打算跳槽的 程序员看到这个文章能有一点点帮助或收获,我就心满意足了。多思考,多问为什么。希望小伙伴们早点收到满意的offer! 越努力越幸运!
金九银十已经过了,就目前国内的面试模式来讲,在面试前积极的准备面试,复习整个 Java 知识体系将变得非常重要,可以很负责任的说一句,复习准备的是否充分,将直接影响你入职的成功率。但很多小伙伴却苦于没有合适的资料来回顾整个 Java 知识体系,或者有的小伙伴可能都不知道该从哪里开始复习。我偶然得到一份整理的资料,不论是从整个 Java 知识体系,还是从面试的角度来看,都是一份含技术量很高的资料。

责任的说一句,复习准备的是否充分,将直接影响你入职的成功率。但很多小伙伴却苦于没有合适的资料来回顾整个 Java 知识体系,或者有的小伙伴可能都不知道该从哪里开始复习。我偶然得到一份整理的资料,不论是从整个 Java 知识体系,还是从面试的角度来看,都是一份含技术量很高的资料。**
[外链图片转存中…(img-RIkVEpRD-1714729918782)]















 1258
1258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









