







总结
无论是哪家公司,都很重视高并发高可用的技术,重视基础,重视JVM。面试是一个双向选择的过程,不要抱着畏惧的心态去面试,不利于自己的发挥。同时看中的应该不止薪资,还要看你是不是真的喜欢这家公司,是不是能真的得到锻炼。其实我写了这么多,只是我自己的总结,并不一定适用于所有人,相信经过一些面试,大家都会有这些感触。
最后我整理了一些面试真题资料,技术知识点剖析教程,还有和广大同仁一起交流学习共同进步,还有一些职业经验的分享。

strItem.setLength(0);//清空
strItem.append(sc);//追加新的字母 期待下一次连续
continue;
}
if(isCaseStart==false &&isCase(sc)){
//非字母开头,且当前字符是字母 意味着一个子串结束 当字符需要保留
strItem.append(sc);
if(strItem.length()>=2){
strList.add(strItem.toString());
}
isCaseStart=true;//这回字符开头了
strItem.setLength(0);//清空
strItem.append(sc);//追加新的字母 期待下一次连续
continue;
}
strItem.append(sc);
//最后一位是数字时 必须首字符是字母
if(i==singleCases.length-1&&isCaseStart){
if(strItem.length()>=2){
strList.add(strItem.toString());
}
}
}
int max=-1;
for(String item:strList){
if(item.length()>max){
max=item.length();
}
}
System.out.println("满足条件最大子串:"+max);
}
public static boolean isCase(char item){
return (item<='z'&&item>='a') ||(item<='Z'&&item>='A');
}
}
### 6.字符串分割
**题目描述**
>
> 给定一个非空字符串S,其被N个‘-’分隔成N+1的子串,给定正整数K,要求除第一个子串外,其余的子串每K个字符组成新的子串,并用‘-’分隔。
> 对于新组成的每一个子串,如果它含有的小写字母比大写字母多,则将这个子串的所有大写字母转换为小写字母;
> 反之,如果它含有的大写字母比小写字母多,则将这个子串的所有小写字母转换为大写字母;大小写字母的数量相等时,不做转换。
>
>
>
**输入描述**
>
> 输入为两行,第一行为参数K,第二行为字符串S。
>
>
>
**输出描述**
>
> 输出转换后的字符串
>
>
>
| 输入1 | 输入2 | 输出 | 说明 |
| --- | --- | --- | --- |
| 3 | 12abc-abCABc-4aB@ | 12abc-abc-ABC-4aB-@ | |
| 12 | 12abc-abCABc-4aB@ | 12abc-abCABc4aB@ | |
**源码和解析**
解析:
>
> 依据题意 第一个子串不做变化,可以另外保存
> 将第一个子串外的其他子串合并为为一个字符串,再根据长度拆分为新的子串
> 判断新的子串中字符的大小写情况来来做大小写变化
>
>
>
示例代码:
import java.util.ArrayList;
import java.util.List;
public class T6 {
public static void main(String[] args) {
int number = 6;// 拆分数
String input = “12abc-abCABc-4aB@a”; // 输入的子串
String[] strArr = input.split(“-”);
String tempStr = “”;// 临时子串
for (int i = 1; i < strArr.length; i++) {
tempStr += strArr[i];// 产生新的子串
}
// 按拆分数重新分配子串
List strList = new ArrayList();
strList.add(strArr[0]);
System.out.println(tempStr);
if (tempStr.length() < number) {
strList.add(tempStr);
} else {
while (tempStr.length() > 0) {
if (tempStr.length() >= number) {
String item = tempStr.substring(0, number);
strList.add(item);
tempStr = tempStr.replaceFirst(item, “”);
} else {
if (tempStr.length() > 0) {
strList.add(tempStr);
tempStr = “”;
}
}
}
}
// 针对每个子串进行大小写判断 并产生新的子串
String result = strArr[0];
for (String item : strList) {
if (!item.equals(strArr[0])) {
// 开始判断
result += “-” + trans(item);
}
}
// System.out.println(strList);
System.out.println(result);
}
// 字符串的变化处理
static String trans(String key) {
int bigNumber = 0;
int littleNumber = 0;
char chArr[] = key.toCharArray();
for (char c : chArr) {
if (c >= 'a' && c <= 'z')
littleNumber++;
if (c >= 'A' && c <= 'Z')
bigNumber++;
}
if (bigNumber > littleNumber) {
key = key.toUpperCase();
} else if (bigNumber < littleNumber) {
key = key.toLowerCase();
}
return key;
}
}
### 7.一种字符串压缩表示的解压
**题目描述**
>
> 有一种简易压缩算法:针对全部由小写英文字母组成的字符串,将其中连续超过两个相同字母的部分压缩为连续个数加该字母,其他部分保持原样不变。
> 例如:字符串“aaabbccccd”经过压缩成为字符串“3abb4cd”。
> 请您编写解压函数,根据输入的字符串,判断其是否为合法压缩过的字符串,
> 若输入合法则输出解压缩后的字符串,否则输出字符串“!error” 来报告错误
>
>
>
**输入描述**
>
> 输入一行,为一个ASCII字符串,长度不会超过100字符,用例保证输出的字符串长度也不会超过100字符。
>
>
>
**输出描述**
>
> 若判断输入为合法的经过压缩后的字符串,则输出压缩前的字符串;若输入不合法,则输出字符串“
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| 4dff | ddddff | 4d扩展为dddd,故解压后的字符串为ddddff。 |
| 2dff | !error | 两个d不需要压缩,故输入不合法。 |
| 4d@A | !error | 全部由小写英文字母组成的字符串压缩后不会出现特殊字符@和大写字母A,故输入不合法。 |
**源码和解析**
解析:
>
> 按照题意可知:
> 1.合法的压缩字串只应包含数字和小写字母 包含其他字符则为不合法的,且数字必须大于2,否则也是不合法的。例如dd压缩为2d 其字符数并未减少,达不到压缩的效果。数字后必须出现字符,否则也是不合法的数据。最后一位是数字也不行
> 2.解决这个题,首先得判读是否合法,若合法,则再进行还原
> 3.还原时遇见数字n,则可以使用循环,来产生n个数字后出现的字符。
>
>
>
import java.util.ArrayList;
public class T7 {
public static void main(String[] args) {
String input = “4dff”;
if (!check(input)) {
System.out.println(“!error”);
System.exit(0);
}
char chArr[] = input.toCharArray();
// 重组字符 a15dff3d=> [1,15,d,f,f,3,d]
ArrayList chList = new ArrayList<>();
String item = “”;
boolean isNumber = false;
StringBuilder result = new StringBuilder();
for (char c : chArr) {
if (isNumberic©) {
// 当前是数字
if (isNumber) {
// 前一个字符也是数字
item += c;
} else {
// 前一个字符不是数字
item = c + “”;
isNumber = true;
}
} else {
// 是字符
if (isNumber) {
// 前面的是数字
chList.add(item);
item = “”;
isNumber = false;
}
chList.add(c + “”);
}
}
boolean flag = false;// 前一位是否是数字
for (int j = 0; j < chList.size(); j++) {
String n = chList.get(j);
if (n.length() == 1) {
// 单字符 可能是数字 也可能是字母
if (isNumberic(n.charAt(0))) {
// 是数字
int len = Integer.parseInt(n);
if (len <= 2) {
System.out.println(“!error”);
System.exit(0);
}
for (int i = 0; i < len; i++) {
result.append(chList.get(j + 1));
}
flag = true;
} else {
// 是字符
if (flag == false) {
// 前一位是字符 直接拼接
result.append(n);
}
flag = false;
}
} else {
// 肯定是数字
int len = Integer.parseInt(n);
flag = true;
for (int i = 0; i < len; i++) {
result.append(chList.get(j + 1));
}
}
}
// System.out.println(chList);
System.out.println(result);
}
// 判断单字符是否是数字
static boolean isNumberic(char c) {
int chr = c;// 转为ASCII码来判断 48位0
if (chr >= 48 && chr <= 57) { // (int)'0' ==>48
return true;
}
return false;
}
// 检查只包含数字和小写字母(未来过滤2及以下数字)
static boolean check(String param) {
char chArr[] = param.toCharArray();
// 最后一位是数字也不行
if (isNumberic(chArr[chArr.length - 1])) {
return false;
}
boolean flag = true;
for (char c : chArr) {
if (c >= 'a' && c <= 'z') {
continue;
}
int chr = c;// 转为ASCII码来判断 48位0
if (chr >= 48 && chr <= 57) { // (int)'0' ==>48
continue;
}
flag = false;
break;
}
return flag;
}
}
### 8.矩阵最大值
**题目描述**
>
> 给定一个仅包含0和1的N\*N二维矩阵,请计算二维矩阵的最大值,计算规则如下:
> 1.每行元素按下标顺序组成一个二进制数(下标越大越排在低位),二进制数的值就是该行的值。矩阵各行值之和为矩阵的值。
> 2.允许通过向左或向右整体循环移动每行元素来改变各元素在行中的位置。
> 比如:
> [1,0,1,1,1]向右整体循环移动2位变为[1,1,1,0,1],二进制数为11101,值为29。
> [1,0,1,1,1]向左整体循环移动2位变为[1,1,1,1,0],二进制数为11110,值为30。
>
>
>
**输入描述**
>
> 1、输入的第一行为正整数,记录了N的大小,0 < N <= 20。
> 2、输入的第2到N+1行为二维矩阵信息,行内元素边角逗号分隔。
>
>
>
**输出描述**
>
> 矩阵的最大值
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| 5 1,0,0,0,10,0,0,1,10,1,0,1,01,0,0,1,11,0,1,0,1 | 122 | 第一行向右整体循环移动1位,得到本行的最大值[1,1,0,0,0],二进制值为11000,十进制值为24。第二行向右整体循环移动2位,得到本行的最大值[1,1,0,0,0],二进制值为11000,十进制值为24。第三行向左整体循环移动1位,得到本行的最大值[1,0,1,0,0],二进制值为10100,十进制值为20。第四行向右整体循环移动2位,得到本行的最大值[1,1,1,0,0],二进制值为11100,十进制值为28。第五行向右整体循环移动1位,得到本行的最大值[1,1,0,1,0],二进制值为11010,十进制值为26。因此,矩阵的最大值为122。 |
**源码和解析**
解析:
>
> 对每行的数据进行n次右移,就可以得到最大的可能。求出每行的最大值即可
>
>
>
示例代码:
public class T8 {
public static void main(String[] args) {
int number = 5;
int[][] numArr = { { 1, 0, 0, 0, 1 }, { 0, 0, 0, 1, 1 },
{ 0, 1, 0, 1, 0 }, { 1, 0, 0, 1, 1 }, { 1, 0, 1, 0, 1 } };
// number = 3;
// int[][] numArr ={{1,0,1},{0,1,0},{0,0,1}};
int sum = 0;// 最后的和
for (int[] arr : numArr) {
int[] tmpArr = arr;
int max = 0;
for (int i = 0; i < arr.length; i++) {
tmpArr = toRight(tmpArr, number);
String binStr = “”;
for (int j = 0; j < tmpArr.length; j++) {
// System.out.print(tmpArr[j] + “,”);
binStr += tmpArr[j];
}
int num = Integer.parseUnsignedInt(binStr, 2);
if (max < num) {
max = num;
}
System.out.println(“单行最值:” + max);
}
sum += max;// 每行的最大值相加
System.out.println(“_________”);
}
System.out.println(“矩阵的最大值为:” + sum);
}
public static int[] toRight(int[] arr, int n) {
// 右移一位
int tempArr[] = arr.clone();
for (int i = 1; i < arr.length - 1; i++) {
tempArr[i] = arr[i - 1];
}
tempArr[0] = arr[arr.length - 1];
tempArr[arr.length - 1] = arr[arr.length - 2];
return tempArr;
}
}
### 9.单词接龙
**题目描述**
>
> 单词接龙的规则是:
> 可用于接龙的单词首字母必须要与前一个单词的尾字母相同;
> 当存在多个首字母相同的单词时,取长度最长的单词,如果长度也相等,则取字典序最小的单词;已经参与接龙的单词不能重复使用。
> 现给定一组全部由小写字母组成单词数组,并指定其中的一个单词作为起始单词,进行单词接龙,
> 请输出最长的单词串,单词串是单词拼接而成,中间没有空格。
>
>
>
**输入描述**
>
> 输入的第一行为一个非负整数,表示起始单词在数组中的索引K,0 <= K < N ;
> 输入的第二行为一个非负整数,表示单词的个数N;
> 接下来的N行,分别表示单词数组中的单词。
> 备注:
> 单词个数N的取值范围为[1, 20];
> 单个单词的长度的取值范围为[1, 30];
>
>
>
**输出描述**
>
> 输出一个字符串,表示最终拼接的单词串。
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| 06worddddadcdwordd | worddwordda | 先确定起始单词word,再接以d开头的且长度最长的单词dword,剩余以d开头且长度最长的有dd、da、dc,则取字典序最小的da,所以最后输出worddwordda。 |
| 46worddddadcdwordd | dwordda | 先确定起始单词dword,剩余以d开头且长度最长的有dd、da、dc,则取字典序最小的da,所以最后输出dwordda。 |
**源码和解析**
解析:
>
> 将输入字符装入列表之中,取出索引对应位置的内容,并将其从列表之中移出
> 遍历集合,类似于找最值的方式 找出最优的那个字符进行接龙,接龙后将字符从列表移出
> 接龙后产生新的目标串和后缀,再从列表中进行查找最优子串接龙
> 直到找不到接龙的子串为止
>
>
>
import java.util.ArrayList;
import java.util.Scanner;
public class T9 {
public static void main(String[] args) {
System.out.println(“请输入开始索引:”);
Scanner scanner = new Scanner(System.in);
int startIndex = Integer.parseInt(scanner.nextLine());
System.out.println(“请输入单词数:”);
int number = Integer.parseInt(scanner.nextLine());
ArrayList strList = new ArrayList<>();
for (int i = 0; i < number; i++) {
strList.add(scanner.nextLine());
}
String result = strList.get(startIndex);
strList.remove(startIndex);// 移出第一个
String rString = getDrog(strList, result.charAt(result.length() - 1));
while (rString != null) {
result += rString;
strList.remove(rString);
rString = getDrog(strList, result.charAt(result.length() - 1));
}
System.out.println(result);
// System.out.println(strList);
}
public static String getDrog(ArrayList<String> strList, char suffix) {
ArrayList<String> tempList = new ArrayList<>();
for (String item : strList) {
if (item.startsWith(suffix + "")) {
tempList.add(item);
}
}
String objStr = "";
int maxLength = 0;// 最大长度
if (tempList.size() == 0) {
return null;
}
for (String item : tempList) {
if (item.length() > maxLength) {
maxLength = item.length();
objStr = item;
continue;
}
if (item.length() == maxLength) {
if (objStr.compareTo(item) > 0) {
objStr = item;// 修改了
}
}
}
return objStr.equals("") ? null : objStr;
}
}
### 10.找出符合要求的字符串子串
**题目描述**
>
> 给定两个字符串,从字符串2中找出字符串1中的所有字符,去重并按照ASCII值从小到大排序。
> 输入字符串1:长度不超过1024
> 输入字符串2:长度不超过1000000\n\n字符范围满足ASCII编码要求,按照ASCII的值由小到大排序
>
>
>
**输入描述**
>
> bach
> bbaaccedfg
>
>
>
**输出描述**
>
> abc
> 输入字符串1 为给定字符串bach,输入字符串2 bbaaccedfg
> 从字符串2中找出字符串1的字符,去除重复的字符,并且按照ASCII值从小到大排序,得到输出的结果为abc。
> 字符串1中的字符h在字符串2中找不到不输出。
>
>
>
| 输入1 | 输入2 | 输出 | 说明 |
| --- | --- | --- | --- |
| fach | bbaaccedfg | acf | 无 |
**源码和解析**
解析:
>
> 去除重复字符 可以使用set集合
> 如果字符串2中 包含字符串1中的单个字符,那么那个字符就是目标字符。其他字符则不需保留
>
>
>
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class T10 {
public static void main(String[] args) {
String input1 = “fach”;
String input2 = “bbaaccedfg”;
Set characters = new HashSet<>();
for (char c : input1.toCharArray()) {
characters.add©;
}
;
Set characters2 = new HashSet<>();
for (char c : input2.toCharArray()) {
characters2.add©;
}
;
// 求两个集合的交集
List cList = new ArrayList();
for (char c : characters) {
// 不包含的就移出掉
if (characters2.contains©) {
cList.add©;
}
}
cList.sort(new Comparator() {
@Override
public int compare(Character o1, Character o2) {
if (o1 < o2)
return -1;
if (o1 > o2)
return 1;
return 0;
}
});
for (Character c : cList) {
System.out.print©;
}
}
}
### 11.字符串加密
**题目描述**
>
> 给你一串未加密的字符串str,通过对字符串的每一个字母进行改变来实现加密,加密方式是在每一个字母str[i]偏移特定数组元素a[i]的量,数组a前三位已经赋值:a[0]=1,a[1]=2,a[2]=4。
> 当i>=3时,数组元素a[i]=a[i-1]+a[i-2]+a[i-3]。
> 例如:原文 abcde 加密后 bdgkr,其中偏移量分别是1,2,4,7,13。
>
>
>
**输入描述**
>
> 第一行为一个整数n(1<=n<=1000),表示有n组测试数据,每组数据包含一行,原文str(只含有小写字母,0<长度<=50)。
>
>
>
**输出描述**
>
> 每组测试数据输出一行,表示字符串的密文。
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| 1 xy | ya | 第一个字符x偏移量是1,即为y,第二个字符y偏移量是2,即为a。 |
**源码和解析**
解析:
>
> 字符加密后会产生偏移。这种其实是最简单的加密,只需要通过ASCII码进行转换即可
>
>
>
import java.util.ArrayList;
import java.util.Scanner;
public class T11 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println(“请输入测试字符数:”);
int number = Integer.parseInt(scanner.nextLine());
ArrayList strList = new ArrayList<>();
ArrayList pianYiList = new ArrayList<>();
pianYiList.add(1);
pianYiList.add(2);
pianYiList.add(4);
// 初始化数据
for (int i = 0; i < number; i++) {
System.out.println(“请输入第” + (i + 1) + “个字符:”);
strList.add(scanner.nextLine());
}
for (int i = 0; i < strList.size(); i++) {
char chArr[] = strList.get(i).toCharArray();
StringBuilder secretStr = new StringBuilder();
for (int j = 0; j < chArr.length; j++) {
// 偏移量集合中的数据不够 字符去便宜的
// System.out.println(j+“_”+pianYiList.size()+“”+());
if (j > (pianYiList.size() - 1) && j >= 3) {
pianYiList.add(pianYiList.get(j - 1)
+ pianYiList.get(j - 2) + pianYiList.get(j - 3));
}
int c = chArr[j];
c = c + pianYiList.get(j);
c = c > (int) ‘z’ ? c % (int) ‘z’ + 96 : c; // 96是小写字符a的前一位
// 若z+1则结果为a
secretStr.append((char) c);
}
System.out.println(secretStr.toString());
}
}
}
### 12.英文输入法
**题目描述**
>
> 主管期望你来实现英文输入法单词联想功能。
> 需求如下:
> 依据用户输入的单词前缀,从已输入的英文语句中联想出用户想输入的单词,按字典序输出联想到的单词序列,
> 如果联想不到,请输出用户输入的单词前缀。
> 注意:
> 英文单词联想时,区分大小写
> 缩略形式如”don’t”,判定为两个单词,”don”和”t”
> 输出的单词序列,不能有重复单词,且只能是英文单词,不能有标点符号
>
>
>
**输入描述**
>
> 输入为两行。
> 首行输入一段由英文单词word和标点符号组成的语句str;
> 接下来一行为一个英文单词前缀pre。
> 0 < word.length() <= 20
> 0 < str.length <= 10000
> 0 < pre <= 20
>
>
>
**输出描述**
>
> 输出符合要求的单词序列或单词前缀,存在多个时,单词之间以单个空格分割
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| I love youHe | He | 从用户已输入英文语句”I love you”中提炼出“I”、“love”、“you”三个单词,接下来用户输入“He”,\n\n从已输入信息中无法联想到任何符合要求的单词,因此输出用户输入的单词前缀。 |
| The furthest distance in the world, Is not between life and death, But when I stand in front of you, Yet you don’t know that I love you.f | front furthest | 从用户已输入英文语句”The furthestdistance in the world, Is not between life and death, But when I stand in frontof you, Yet you dont know that I love you.”中提炼出的单词,符合“f”作为前缀的,有“furthest”和“front”,按字典序排序并在单词间添加空格后输出,结果为“front furthest”。 |
**源码和解析**
解析:
>
> 1.获取输入的所有字符,并拆分成子串数组(按空格) 注意处理缩略词don’t 为don和t
> 2.分别判断子串是否以用户输入的前缀开始
>
>
>
示例代码:
import java.util.ArrayList;
import java.util.Scanner;
public class T12 {
public static void main(String[] args) {
System.out.println(“请输入单词库(空格隔开):”);
Scanner scanner = new Scanner(System.in);
String input1 = scanner.nextLine();
System.out.println(“请输入单词前缀:”);
String input2 = scanner.nextLine();
ArrayList wordList = new ArrayList<>();
StringBuilder word = new StringBuilder();
for (int i = 0; i < input1.length(); i++) {
char c = input1.charAt(i);
// 字符过滤
if (!((c <= ‘z’ && c >= ‘a’) || (c <= ‘Z’ && c >= ‘A’))) {
if (word.length() > 0) {
wordList.add(word.toString());
word.setLength(0);
}
continue;
}
;
if (c == ’ ‘) {
if (word.length() > 0) {
wordList.add(word.toString());
word.setLength(0);
}
continue;
}
if (c == ‘’’) {
if (word.length() > 0) {
wordList.add(word.toString());
word.setLength(0);
}
continue;
}
word.append©;
if (i == input1.length() - 1) {
if (word.length() > 0) {
wordList.add(word.toString());
word.setLength(0);
}
}
}
boolean flag = false;// 是否找到
for (String wd : wordList) {
if (wd.startsWith(input2)) {
flag = true;
System.out.print(wd + " ");
}
}
if (flag == false) {
System.out.println(input2);
}
}
}
### 13.按索引范围翻转文章片段
**题目描述**
>
> 输入一个英文文章片段,翻转指定区间的单词顺序,标点符号和普通字母一样处理。
> 例如输入字符串”I am a developer. “,区间[0,3],则输出”developer. a am I”。
>
>
>
**输入描述**
>
> 使用换行隔开三个参数
> 第一个参数为英文文章内容即英文字符串
> 第二个参数为翻转起始单词下标(下标从0开始)
> 第三个参数为结束单词下标
>
>
>
**输出描述**
>
> 翻转后的英文文章片段所有单词之间以一个半角空格分隔进行输出。
>
>
>
| 输入 | 开始下标 | 结束下标 | 输出 | 说明 |
| --- | --- | --- | --- | --- |
| I am a developer | 1 | 2 | I a am developer. | |
| hello world! | 0 | 1 | world! hello | 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。 |
| I am a developer. | 0 | 3 | developer. a am I | 如果两个单词见有多余的空格,将反转后单词间的空格减少到只含一个。 |
| Hello! | 0 | 3 | EMPTY | 指定反转区间只有一个单词,或无有效单词则统一输出EMPTY。 |
**源码和解析**
解析:
>
> 1.获取输入字符 按空格拆分。符号按字母处理,那么就不用识别字符
> 2.指定反转区间只有一个单词,或无有效单词则统一输出EMPTY。
> 3.单词中的多余空格需要处理
> 4.按索引区间进行反转。若结束下标超过单词索引,那么就翻转到单词集最后一位
>
>
>
import java.util.ArrayList;
public class T13 {
public static void main(String[] args) {
String input = “I am a developer.”;
int startIndex = 0;// 开始下标
int endIndex = 3; // 结束下标
String[] wordArr = input.split(" “);
ArrayList reverseList = new ArrayList<>();// 待反转数组
for (int i = 0; i < wordArr.length; i++) {
if (!wordArr[i].equals(” ")) {
reverseList.add(wordArr[i]);
}
}
if (endIndex > reverseList.size())
endIndex = wordArr.length - 1;
if (reverseList.size() <= 1) {
System.out.println(“EMPTY”);
return;
}
int count = 0;
for (int i = 0; i < reverseList.size(); i++) {
// 开始索引前和结束索引后的
if (i < startIndex || i > endIndex) {
System.out.print(reverseList.get(i) + " ");
continue;
}
System.out.print(reverseList.get(endIndex - count) + " ");
count++;
}
}
}
### 14. TLV解析Ⅰ
**题目描述**
>
> TLV编码是按[Tag Length Value]格式进行编码的,一段码流中的信元用Tag标识,Tag在码流中唯一不重复,Length表示信元Value的长度,Value表示信元的值。
> 码流以某信元的Tag开头,Tag固定占一个字节,Length固定占两个字节,字节序为小端序。
> 现给定TLV格式编码的码流,以及需要解码的信元Tag,请输出该信元的Value。
> 输入码流的16进制字符中,不包括小写字母,且要求输出的16进制字符串中也不要包含小写字母;码流字符串的最大长度不超过50000个字节。
>
>
>
**输入描述**
>
> 输入的第一行为一个字符串,表示待解码信元的Tag;
> 输入的第二行为一个字符串,表示待解码的16进制码流,字节之间用空格分隔。
>
>
>
**输出描述**
>
> 输出一个字符串,表示待解码信元以16进制表示的Value。
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| 31 32 01 00 AE 90 02 00 01 02 30 03 00 AB 32 31 31 02 00 32 33 33 01 00 CC | 32 33 | 需要解析的信元的Tag是31,从码流的起始处开始匹配,第一个信元的Tag是32,信元长度为1(01 00,小端序表示为1);第二个信元的Tag是90,其长度为2;第三个信元的Tag是30,其长度为3;第四个信元的Tag是31,其长度为2(02 00),所以返回长度后面的两个字节即可,即32 33。 |
**源码和解析**
解析:
>
> 这个题首先要理解题目还是挺难的。小编拿到这个题读了三五遍还是理解不了题目要我们做个啥。后面也是参考别人的博客理解的题意。
> 首先要理解的一个概念就是 **小端序**
> 字节的排列方式有两个通用规则:
>
>
> **大端序Big-Endian**: 将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。
> **小端序Little-Endian**: 将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序。小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。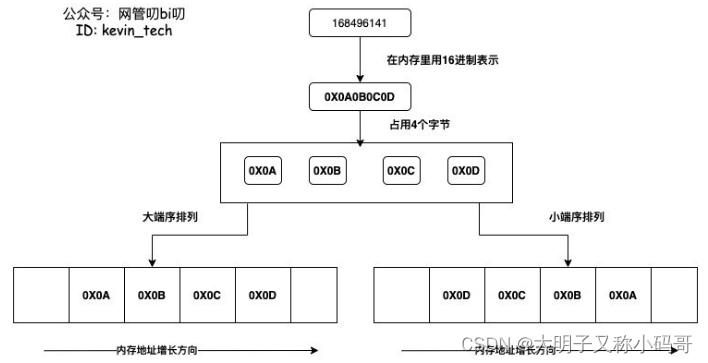
> 也就是说 小端序的排列方式 Len的两个字节需要交换顺序才能得到值的长度
> 比如02 00 = 其长度表示应该为 0002 也就是2位长度
> 示例中的码流可以做如下解析:
> 
> 也就是每个tag对应的值 长度是变化的。**我们需要依据tag后的两个字节长度推出后面的值**。
>
>
>
示例代码:
public class T14 {
public static void main(String[] args) {
String objTag=“31”;
String input=“32 01 00 AE 90 02 00 01 02 30 03 00 AB 32 31 31 02 00 32 33 33 01 00 CC”;
String[] chArr = input.split(" “);
for(int i=0;i<chArr.length;){
String tag=chArr[i];
int len=Integer.parseInt(chArr[i+2]+chArr[i+1]);// 小端序排列 还原长度时要交换位置
StringBuilder value=new StringBuilder();
i+=2;// tag 移动完
for(int j=1;j<=len;j++){
value.append(chArr[i+j]+” ");
i++;//移动值
}
if(tag.equals(objTag)){
System.out.println(value);
break;
}
if(i<=(chArr.length-1))i++;// 移动tag
}
}
}
### 15.字符串筛选排序
**题目描述**
>
> 输入一个由N个大小写字母组成的字符串
> 按照ASCII码值从小到大进行排序
> 查找字符串中第K个最小ASCII码值的字母(k>=1)
> 输出该字母所在字符串中的位置索引(字符串的第一个位置索引为0)
> k如果大于字符串长度则输出最大ASCII码值的字母所在字符串的位置索引
> 如果有重复字母则输出字母的最小位置索引
>
>
>
**输入描述**
>
> 第一行输入一个由大小写字母组成的字符串
> 第二行输入k ,k必须大于0 ,k可以大于输入字符串的长度
>
>
>
**输出描述**
>
> 输出字符串中第k个最小ASCII码值的字母所在字符串的位置索引
> k如果大于字符串长度则输出最大ASCII码值的字母所在字符串的位置索引
> 如果第k个最小ASCII码值的字母存在重复 则输出该字母的最小位置索引
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| AbCdeFG 3 | 5 | 1.根据ASCII码排序 得到ACFGbde 第三位是F F在原字符串 AbCdeFG中索引为5 |
**源码和解析**
解析:
>
> 注意这里面涉及到原字符串和排序后的子串。还有就是两个位置(输入的第二个字符为位置,转换为索引是该数-1,例如第3个对应的位置值F 其索引为3-1=2 。还有一个输出值为目标字符F在字符串中第一次出现的索引。注意区分)
>
>
>
import java.util.Arrays;
public class T15 {
public static void main(String[] args) {
String input = “AbCdeFG”;
int position = 3; // 排序后子串中的第n个
char[] chArr = input.toCharArray();
char obj = ’ ';
char[] newArr = chArr.clone();
Arrays.sort(chArr);
if (position > chArr.length) {
obj = chArr[chArr.length - 1];// 取ASCC最大的字符
} else {
obj = chArr[position - 1];
}
for (int i = 0; i < newArr.length; i++) {
if (obj == newArr[i]) {
System.out.println(i);
break;
}
}
}
}
### 16.连续字母长度
**题目描述**
>
> 给定一个字符串,只包含大写字母,求在包含同一字母的子串中,长度第 k 长的子串的长度,相同字母只取最长的那个子串。
>
>
>
**输入描述**
>
> 第一行有一个子串(1<长度<=100),只包含大写字母。
> 第二行为 k的值
>
>
>
**输出描述**
>
> 输出连续出现次数第k多的字母的次数。
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| AAAAHHHBBCDHHHH3 | 2 | 同一字母连续出现的最多的是A和H,四次;第二多的是H,3次,但是H已经存在4个连续的,故不考虑;下个最长子串是BB,所以最终答案应该输出2 |
| AABAAA 2 | 1 | 同一字母连续出现的最多的是A,三次;第二多的还是A,两次,但A已经存在最大连续次数三次,故不考虑;下个最长子串是B,所以输出1。 |
**源码与解析**
解析:
>
> 可以考虑将字符例如A与其出现的次数写入Map对象 ,A下次出现的次数如果比上次多,就替换,否则就不管 例如 AABAAA=》 {A:2}=>{A:2,B:1}=>{A:3,B:1}
> 将集合还原为字符串转换到List中 [AAA,B]
> List按字符的长度来排序(大到小) 输出顺序对应的位置的字符即可
>
>
>
示例代码:
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class T16 {
public static void main(String[] args) {
String input = “AAAAHHHBBCDHHHH”;
int index = 1;
String temStr = getSameCharacter(input);
Map<Character, Integer> map = new HashMap<Character, Integer>();
map.put(temStr.charAt(0), temStr.length());
while (input.replaceFirst(temStr, “”).length() > 0) {
input = input.replaceFirst(temStr, “”);
temStr = getSameCharacter(input);
if (map.get(temStr.charAt(0)) == null) {
map.put(temStr.charAt(0), temStr.length());
continue;
}
// 原来的小于当前 否则不换
if (map.get(temStr.charAt(0)) < temStr.length()) {
map.put(temStr.charAt(0), temStr.length());
}
}
ArrayList strList = new ArrayList<>();
Set keySet = map.keySet();
Iterator it = keySet.iterator();
while (it.hasNext()) {
Character character = it.next();
Integer len = map.get(character);
StringBuilder str = new StringBuilder();
for (int i = 0; i < len; i++) {
str.append(character);
}
strList.add(str.toString());
}
strList.sort(new Comparator() {
@Override
public int compare(String o1, String o2) {
if (o1.length() > o2.length())
return -1;
if (o1.length() < o2.length())
return 1;
return 0;
}
});
System.out.println(strList);
System.out.println(strList.get(index - 1).length());
// System.out.println(map);
}
// 取某个字符串中首字母连续出现字符
public static String getSameCharacter(String str) {
StringBuilder result = new StringBuilder();
if (str.trim().length() == 0)
return null;
String firstCharacter = str.charAt(0) + "";
while (str.startsWith(firstCharacter)) {
result.append(firstCharacter);
str = str.replaceFirst(firstCharacter, "");
}
return result.toString();
}
}
### 17.拼接URL
**题目描述**
>
> 给定一个url前缀和url后缀,通过","分割 需要将其连接为一个完整的url
> 如果前缀结尾和后缀开头都没有/,需要自动补上/连接符
> 如果前缀结尾和后缀开头都为/,需要自动去重
> 约束:不用考虑前后缀URL不合法情况
>
>
>
**输入描述**
>
> url前缀(一个长度小于100的字符串) url后缀(一个长度小于100的字符串)
>
>
>
**输出描述**
>
> 拼接后的url
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| /acm,/bb | /acm/bb | 无 |
| /abc,/bcd | /abc/bcd | 无 |
| /acd,bef | /acd/bef | 无 |
| , | / | 无 |
**源码和解析**
解析:
>
> 1.可以很轻松获得url的前缀和后缀
> 2.无论前缀后缀是否有/,都可以去掉
> 3.直接拼接即可
> 示例代码:
>
>
>
public class T17 {
public static void main(String[] args) {
String input = “/acd,bef”;
String wordArr[] = input.split(“,”);
if (wordArr.length == 0) {
System.out.println(“/”);
return;
}
if (wordArr.length == 1) {
System.out.println(“/” + wordArr[0]);
return;
}
String prefix = wordArr[0];
if (prefix.startsWith(“/”))
prefix = prefix.replaceFirst(“/”, “”);
String suffix = wordArr[1];
if (suffix.startsWith(“/”))
suffix = suffix.replaceFirst(“/”, “”);
System.out.println(“/” + prefix + “/” + suffix);
}
}
### 18.非严格递增连续数字序列
**题目描述**
>
> 输入一个字符串仅包含大小写字母和数字,求字符串中包含的最长的非严格递增连续数字序列的长度,(比如12234属于非严格递增连续数字序列)。
>
>
>
**输入描述**
>
> 输入一个字符串仅包含大小写字母和数字,输入的字符串最大不超过255个字符。
>
>
>
**输出描述**
>
> 最长的非严格递增连续数字序列的长度
>
>
>
| 输入 | 输出 | 说明 |
| --- | --- | --- |
| abc2234019A334bc | 4 | 2234为最长的非严格递增连续数字序列,所以长度为4。 |
**源码和解析**
解析:
>
> 可以用双指针来做 根据自己需求来 如果对指针使用不是很擅长的。可以考虑不用指针
>
>
>
### 那么如何才能正确的掌握Redis呢?
为了让大家能够在Redis上能够加深,所以这次给大家准备了一些Redis的学习资料,还有一些大厂的面试题,包括以下这些面试题
* 并发编程面试题汇总
* JVM面试题汇总
* Netty常被问到的那些面试题汇总
* Tomcat面试题整理汇总
* Mysql面试题汇总
* Spring源码深度解析
* Mybatis常见面试题汇总
* Nginx那些面试题汇总
* Zookeeper面试题汇总
* RabbitMQ常见面试题汇总
JVM常频面试:

Mysql面试题汇总(一)

Mysql面试题汇总(二)

Redis常见面试题汇总(300+题)

> **本文已被[CODING开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码】](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)收录**
**[需要这份系统化的资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
System.out.println("/" + wordArr[0]);
return;
}
String prefix = wordArr[0];
if (prefix.startsWith("/"))
prefix = prefix.replaceFirst("/", "");
String suffix = wordArr[1];
if (suffix.startsWith("/"))
suffix = suffix.replaceFirst("/", "");
System.out.println("/" + prefix + "/" + suffix);
}
}
18.非严格递增连续数字序列
题目描述
输入一个字符串仅包含大小写字母和数字,求字符串中包含的最长的非严格递增连续数字序列的长度,(比如12234属于非严格递增连续数字序列)。
输入描述
输入一个字符串仅包含大小写字母和数字,输入的字符串最大不超过255个字符。
输出描述
最长的非严格递增连续数字序列的长度
| 输入 | 输出 | 说明 |
|---|---|---|
| abc2234019A334bc | 4 | 2234为最长的非严格递增连续数字序列,所以长度为4。 |
源码和解析
解析:
可以用双指针来做 根据自己需求来 如果对指针使用不是很擅长的。可以考虑不用指针
那么如何才能正确的掌握Redis呢?
为了让大家能够在Redis上能够加深,所以这次给大家准备了一些Redis的学习资料,还有一些大厂的面试题,包括以下这些面试题
-
并发编程面试题汇总
-
JVM面试题汇总
-
Netty常被问到的那些面试题汇总
-
Tomcat面试题整理汇总
-
Mysql面试题汇总
-
Spring源码深度解析
-
Mybatis常见面试题汇总
-
Nginx那些面试题汇总
-
Zookeeper面试题汇总
-
RabbitMQ常见面试题汇总
JVM常频面试:
[外链图片转存中…(img-hmz0idJr-1715506844323)]
Mysql面试题汇总(一)
[外链图片转存中…(img-VGwtJTpn-1715506844323)]
Mysql面试题汇总(二)
[外链图片转存中…(img-SlaLZcxr-1715506844324)]
Redis常见面试题汇总(300+题)
[外链图片转存中…(img-vSwQyJgO-1715506844324)]
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









