







最后的内容
在开头跟大家分享的时候我就说,面试我是没有做好准备的,全靠平时的积累,确实有点临时抱佛脚了,以至于我自己还是挺懊恼的。(准备好了或许可以拿个40k,没做准备只有30k+,你们懂那种感觉吗)
如何准备面试?
1、前期铺垫(技术沉积)
程序员面试其实是对于技术的一次摸底考试,你的技术牛逼,那你就是大爷。大厂对于技术的要求主要体现在:基础,原理,深入研究源码,广度,实战五个方面,也只有将原理理论结合实战才能把技术点吃透。
下面是我会看的一些资料笔记,希望能帮助大家由浅入深,由点到面的学习Java,应对大厂面试官的灵魂追问
这部分内容过多,小编只贴出部分内容展示给大家了,见谅见谅!
- Java程序员必看《Java开发核心笔记(华山版)》

- Redis学习笔记

- Java并发编程学习笔记
四部分,详细拆分并发编程——并发编程+模式篇+应用篇+原理篇

- Java程序员必看书籍《深入理解 ava虚拟机第3版》(pdf版)

- 大厂面试必问——数据结构与算法汇集笔记

其他像Spring,SpringBoot,SpringCloud,SpringCloudAlibaba,Dubbo,Zookeeper,Kafka,RocketMQ,RabbitMQ,Netty,MySQL,Docker,K8s等等我都整理好,这里就不一一展示了。

2、狂刷面试题
技术主要是体现在平时的积累实用,面试前准备两个月的时间再好好复习一遍,紧接着就可以刷面试题了,下面这些面试题都是小编精心整理的,贴给大家看看。
①大厂高频45道笔试题(智商题)

②BAT大厂面试总结(部分内容截图)


③面试总结


3、结合实际,修改简历
程序员的简历一定要多下一些功夫,尤其是对一些字眼要再三斟酌,如“精通、熟悉、了解”这三者的区别一定要区分清楚,否则就是在给自己挖坑了。当然不会包装,我可以将我的简历给你参考参考,如果还不够,那下面这些简历模板任你挑选:

以上分享,希望大家可以在金三银四跳槽季找到一份好工作,但千万也记住,技术一定是平时工作种累计或者自学(或报班跟着老师学)通过实战累计的,千万不要临时抱佛脚。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
CREATE TABLE dept (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(50) DEFAULT NULL,
mobile varchar(50) DEFAULT NULL,
manager int(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

更改springboot配置文件

代码模板:
将连接信息改为自己的
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/dept
username: root
password: root
#开启日志
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
实体类

必须继承 Model,Model 定义了表的 CRUD 方法,Dept 属性名和列名是一样的。
mapper
创建DeptMapper接口,继承BaseMapper

不使用 mapper,也需要定义这个类,Mybatis-Plus通过 mapper 获取到表的结构;
不定义时,Mybatis-Plus报错无法获取表的结构信息。
接下来测试AR的CRUD

返回值是 boolean,true 添加成功。没有添加记录是 false。
日志:

数据库:


创建实体对象,对要更新的属性赋值,null 的属性不更新,根据主键更新记录。
返回值是 boolean,true 更新成功。没有更新记录是 false。
日志:

数据库:


使用主键作为删除条件,deleteById()参数是主键值,sql 语句条件是 where id=1。
返回值始终是 true。通过源码查看:

可以看到deleteById内部调用了delBool
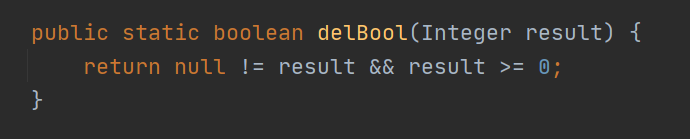
删除返回值判断条件是 result >=0 ,只有 sql 语法是正确的,返回就是 true。和删除记录的数量无关。
日志:

此时数据库已经为空!
为了方便演示后面的查询操作,将 AR 之 Insert的操作多运行几次,保证数据库有数据
这里我就运行3次
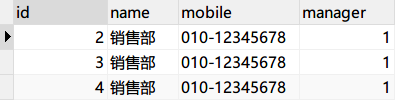
对象调用 selectById()

对象提供主键值,调用 selectById()无参数,使用 id=2 作为查询条件,返回值是查询的结果对象:

没有查询到对象不会报错,返回是 null:

不需要依赖对象提供主键值,直接selectById(主键值)

创建对象,不设值 id 主键值, selectById 的参数是查询条件,和对象的属性值
无关。返回值是结果对象,id 不存在返回 null。
不提供主键 id 值会报错:

报错如下:
com.baomidou.mybatisplus.core.exceptions.MybatisPlusException: selectById primaryKey is null.
如图:

查询所有数据,返回值是List集合

日志:

查询操作是最多的,其它方法的使用在介绍 Wrapper 对象后讲解

主键 ,TableName, TableId
主键类型
IdType 枚举类,主键定义如下:

-
0.none 没有主键
-
1.auto 自动增长(mysql, sql server)
-
2.input 手工输入
-
3.id_worker: 实体类用 Long id , 表的列用 bigint ,int 类型大小不够
-
4.id_worker_str 实体类使用 String id, 表的列使用 varchar 50
-
5.uuid 实体类使用 String id, 列使用 varchar 50
-
id_worker: Twitter 雪花算法-分布式 ID
定义实体类,默认的表名和实体类同名;如果不一致,在实体类定义上面使用@TableName 说明表名称。
例如:@TableName(value=”数据库表名”)
步骤:
表
CREATE TABLE user_address (
id int(11) NOT NULL AUTO_INCREMENT,
city varchar(50) DEFAULT NULL,
street varchar(255) DEFAULT NULL,
zipcode varchar(255) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci

实体类
创建实体类UserAddress
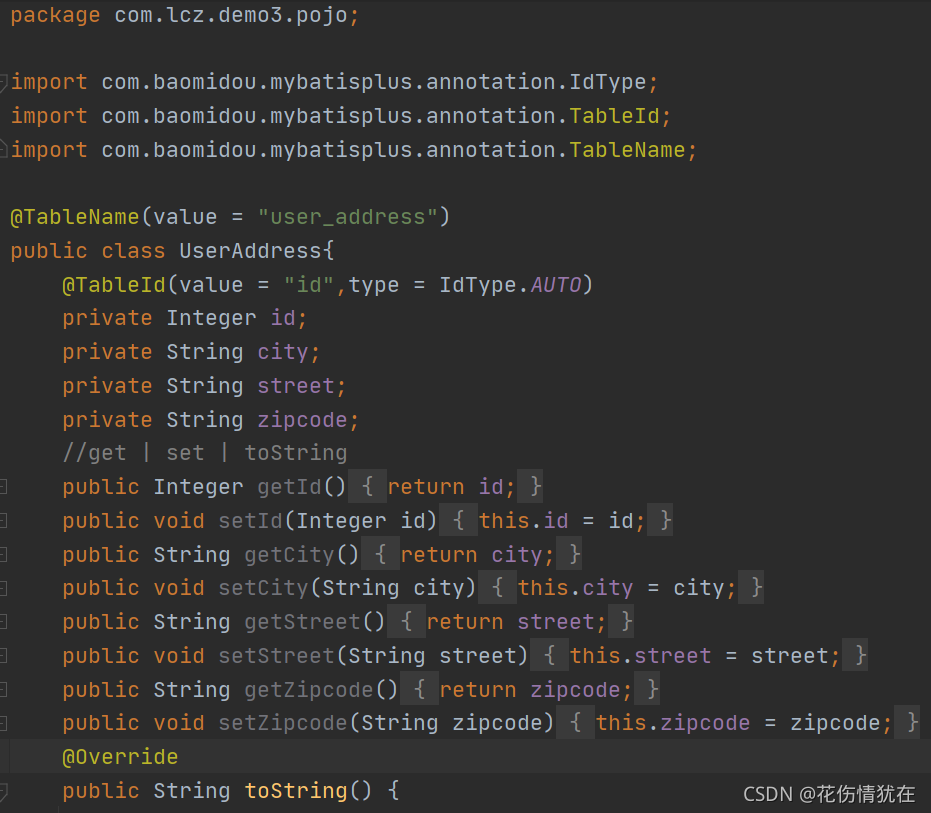
mapper
创建UserAddressMapper接口
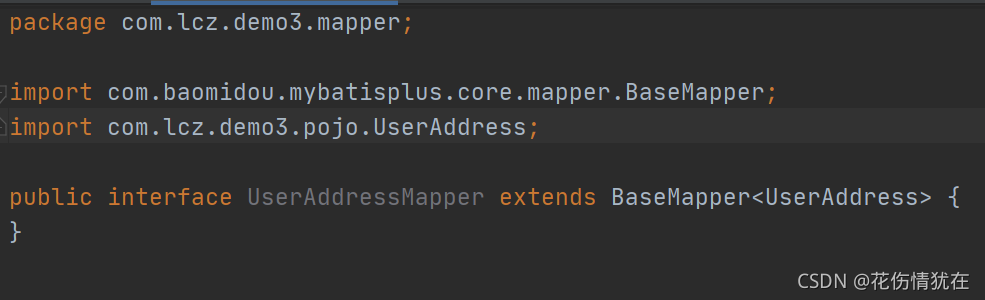
测试
注入mapper对象
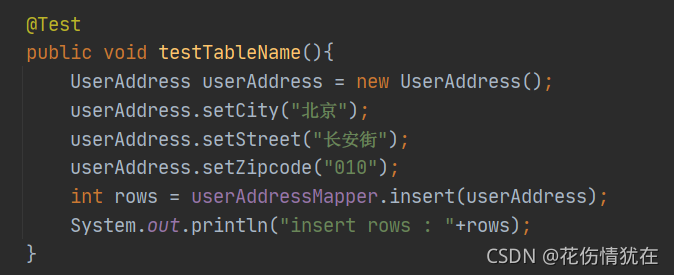
insert 记录:
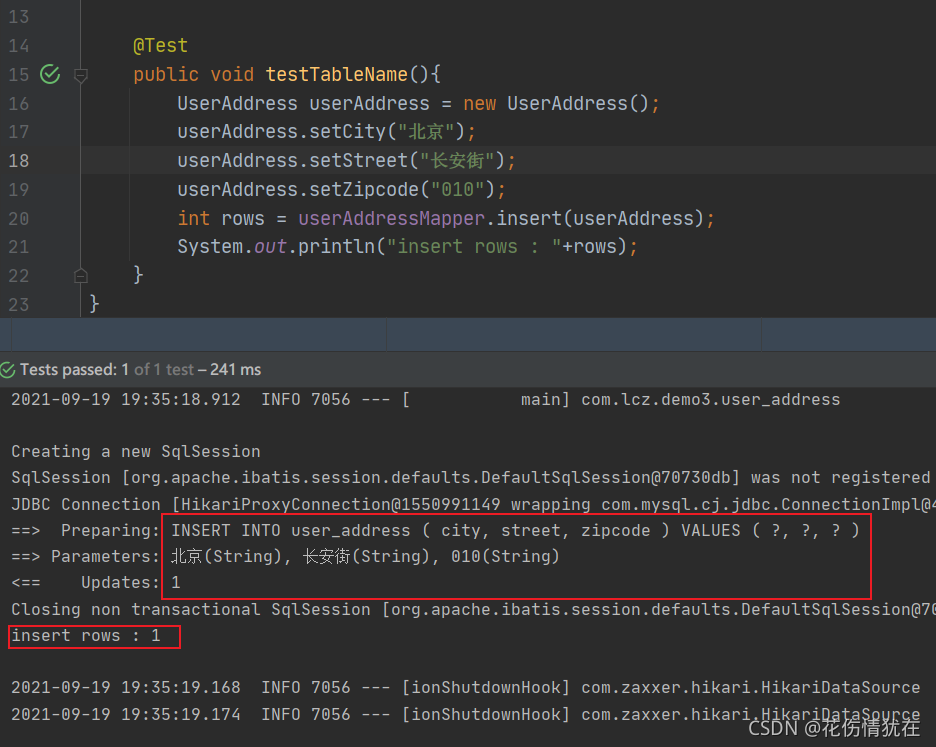
日志:
表
CREATE TABLE salary (
id int(11) NOT NULL AUTO_INCREMENT,
empid int(11) NOT NULL,
empsal float(10,2) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci

实体类
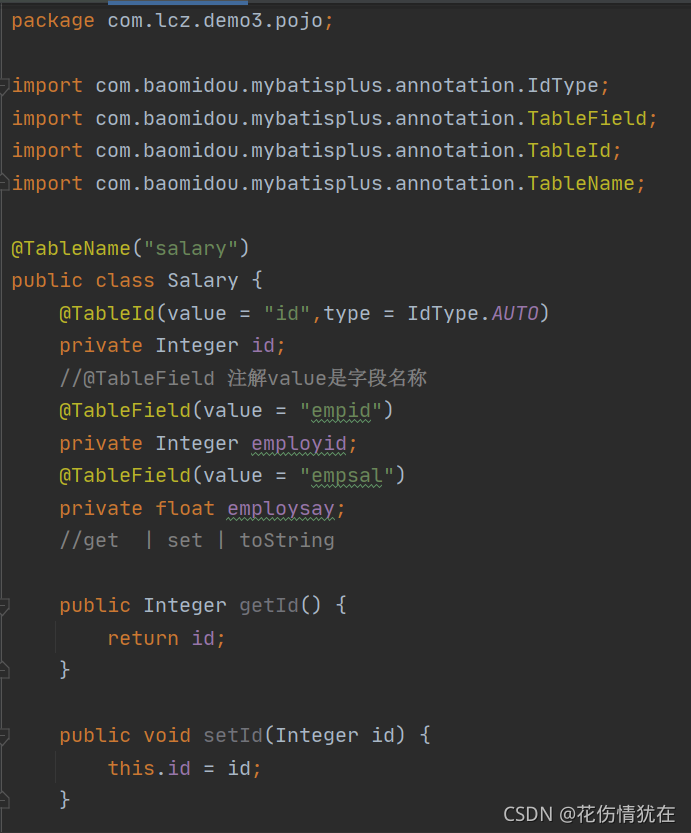
mapper
测试
注入mapper对象
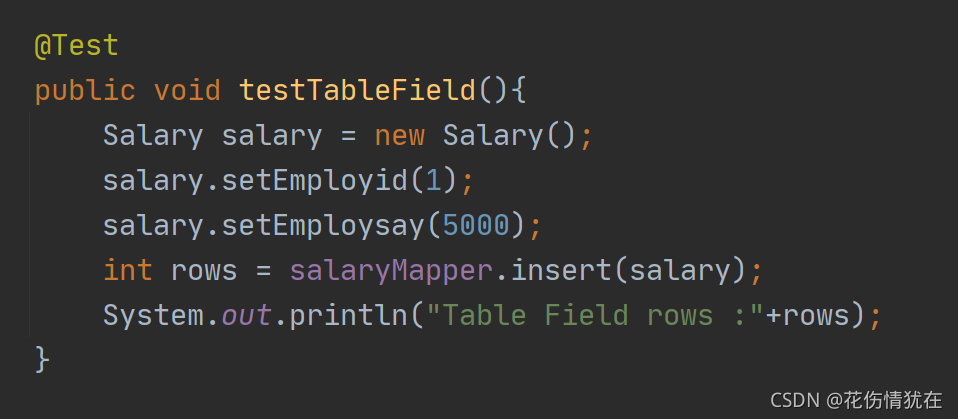
添加
日志
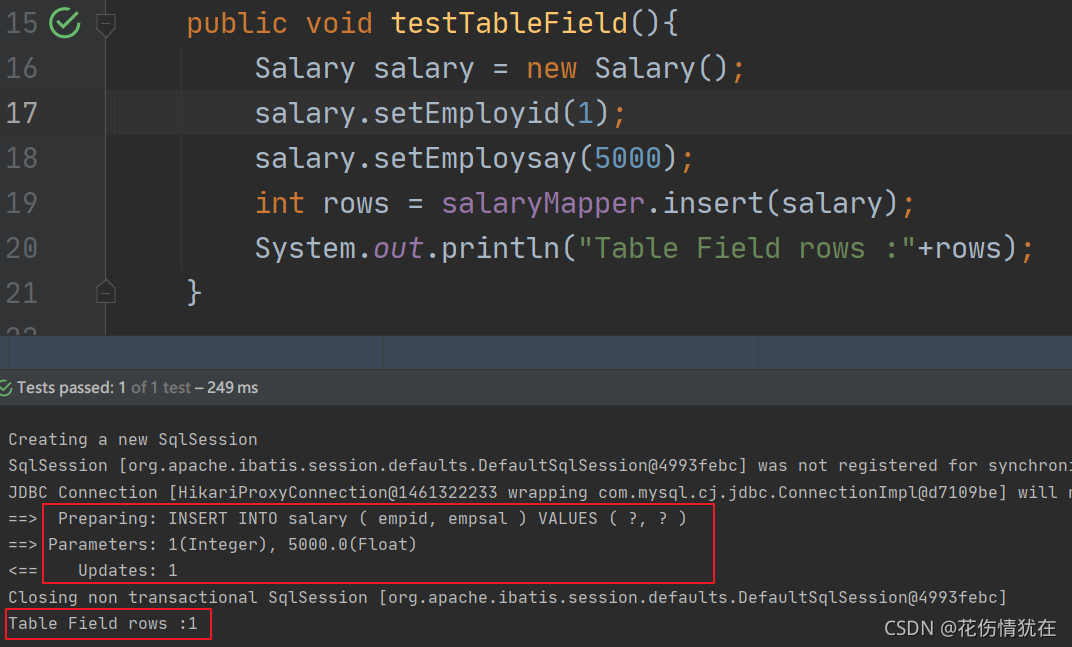
列名使用下划线,属性名是驼峰命名方式。MyBatis 默认支持这种规则。
表定义
CREATE TABLE customer (
id int(11) NOT NULL AUTO_INCREMENT,
cust_name varchar(50) DEFAULT NULL,
cust_age int(11) DEFAULT NULL,
cust_email varchar(100) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci

实体类
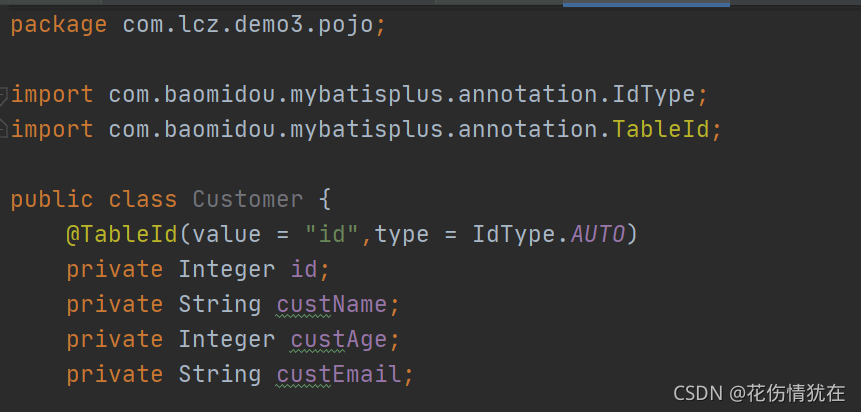
mapper
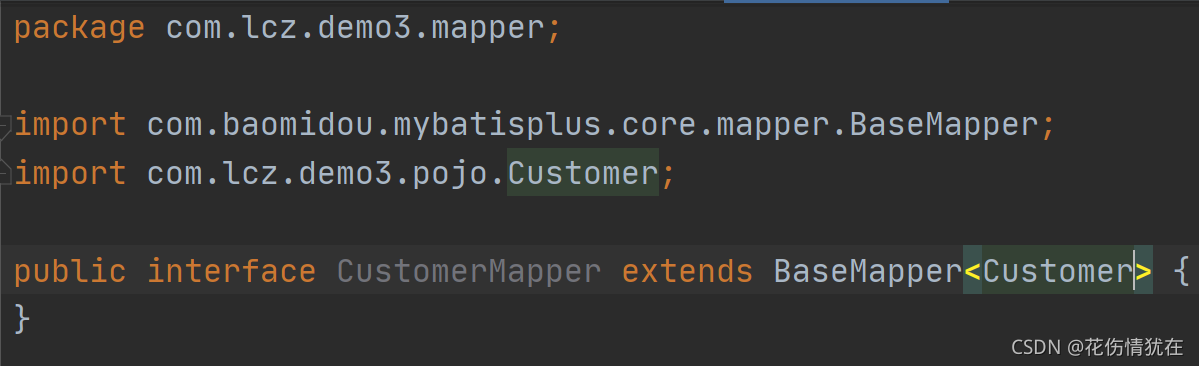
测试
注入mapper对象
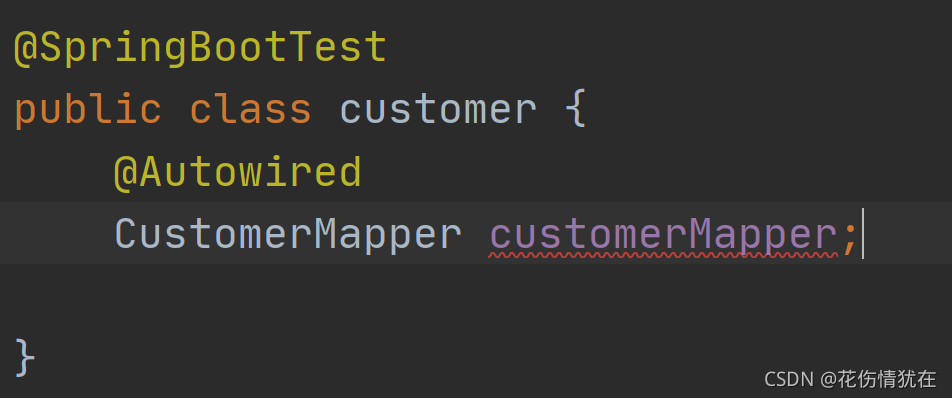
添加
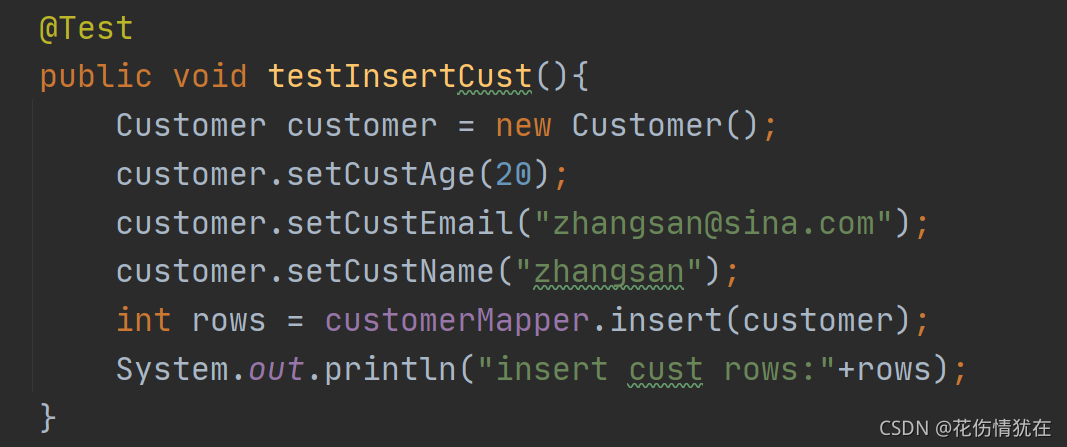
日志
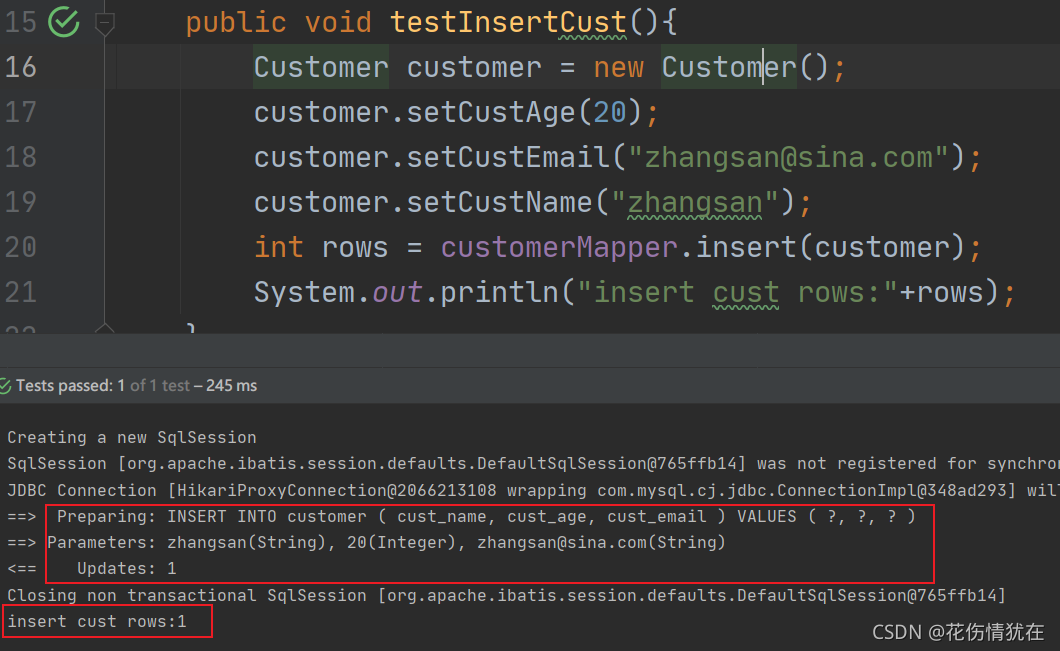
数据库

定义表
CREATE TABLE student (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(80) DEFAULT NULL,
age int(11) DEFAULT NULL,
email varchar(80) DEFAULT NULL,
status int(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
insert into student values(null,‘张三’,22,‘zs@sina.com’,1);

实体
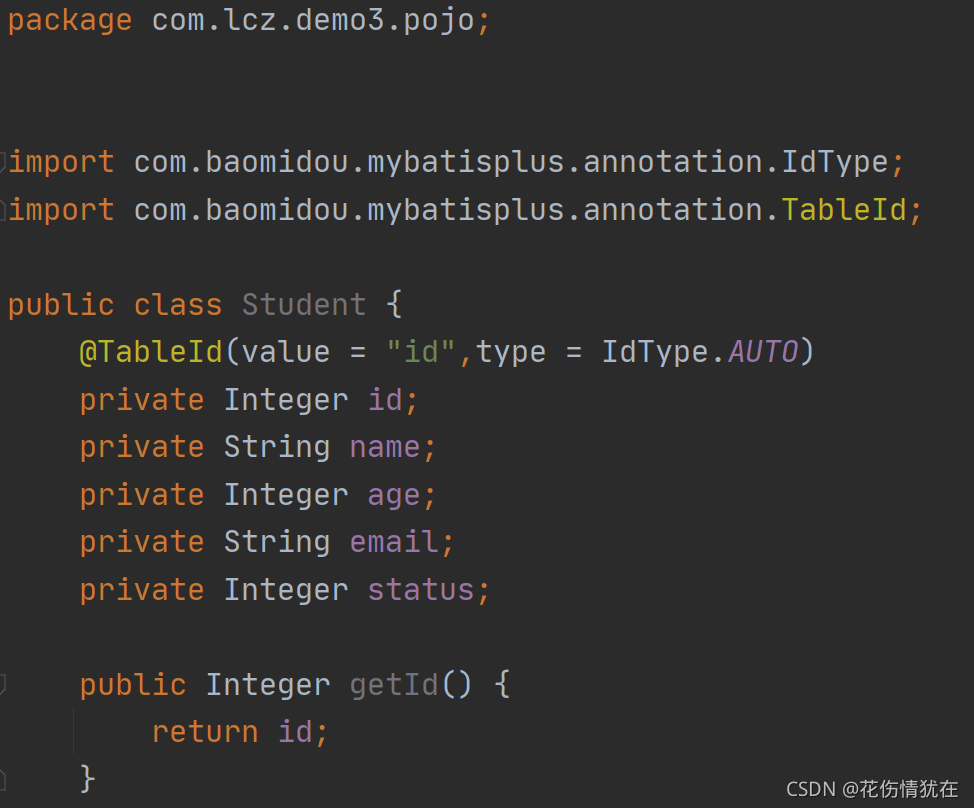
创建 Mapper
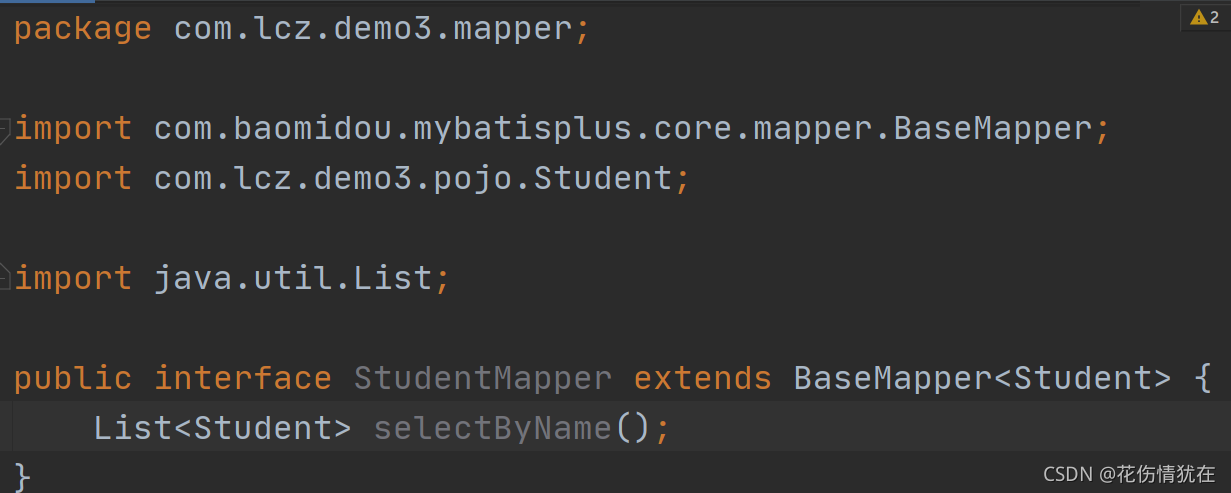
新建 sql 映射 xml 文件
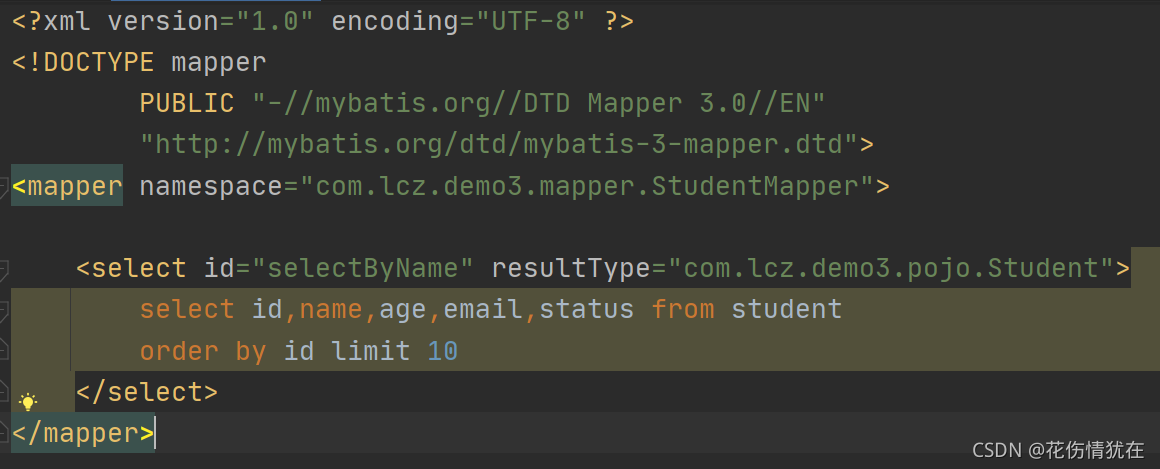
配置 xml 文件位置
application.yml
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
mapper-locations: classpath*:xml/*Mapper.xml

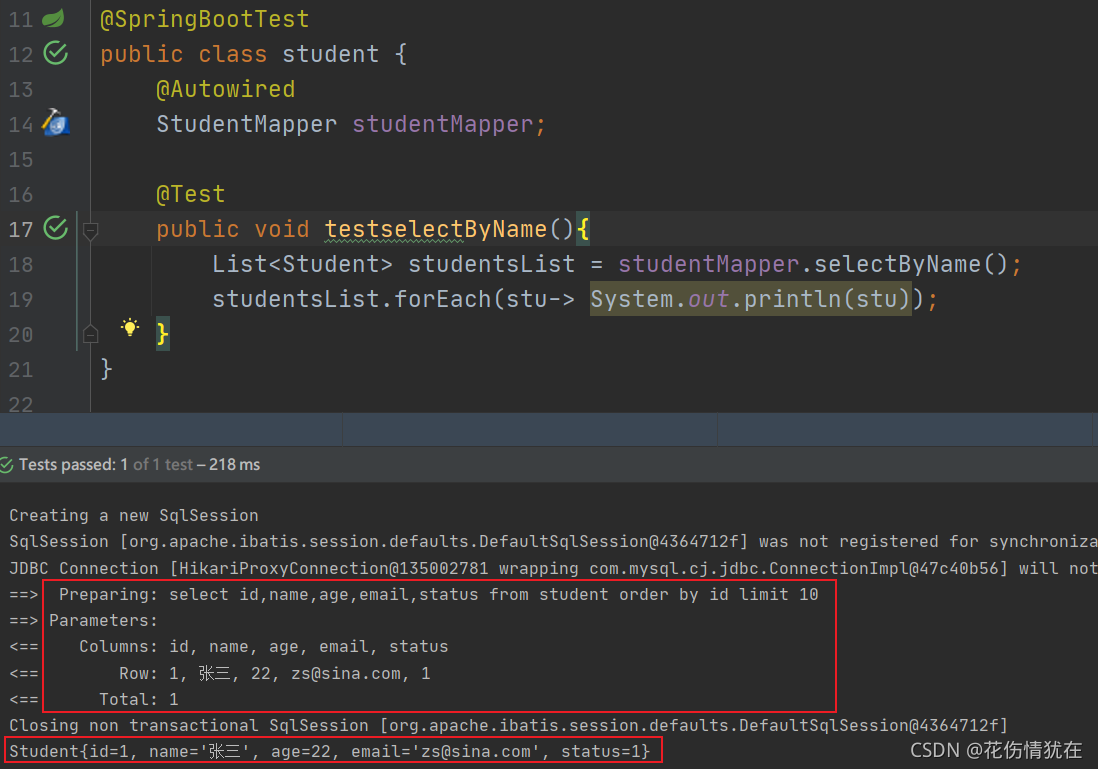
测试
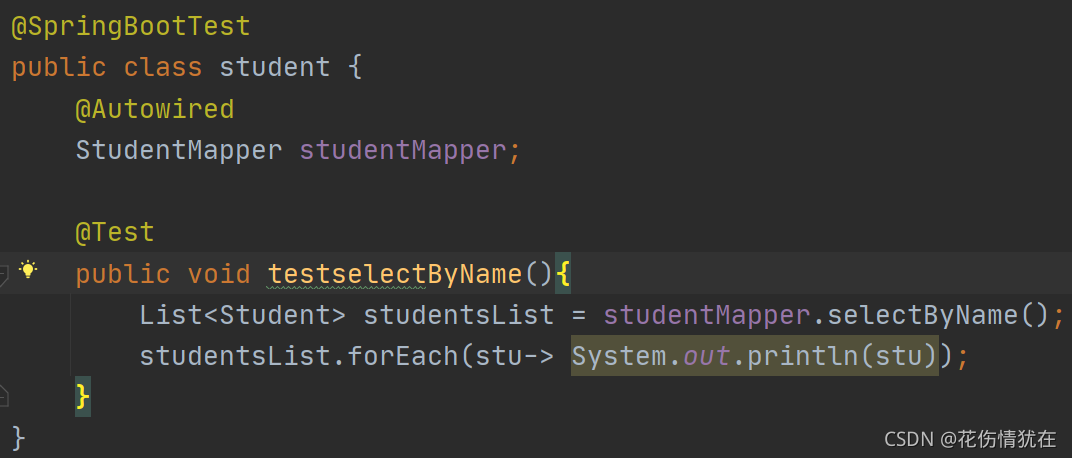
日志:
查询构造器:Wrapper
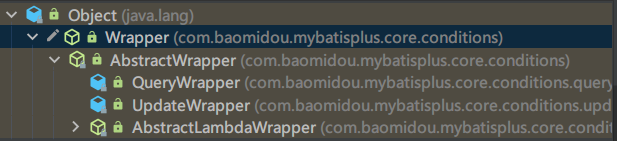
QueryWrapper(LambdaQueryWrapper) 和UpdateWrapper(LambdaUpdateWrapper)的父类用于生成 sql 的 where 条件, entity 属性也用于生成 sql 的 where 条件. MP3.x开始支持lambda表达式,LambdaQueryWrapper,LambdaUpdateWrapper支持 lambda表达式的构造查询条件。
条件:
| 条件 | 说明 |
| — | — |
| allEq | 基于 map 的相等 |
| eq | 等于 = |
| ne | 不等于 <> |
| gt | 大于 > |
| ge | 大于等于 >= |
| lt | 小于 < |
| le | 小于等于 <= |
| between | BETWEEN 值1 AND 值2 |
| norBetween | NOT BETWEEN 值1 AND 值2 |
| like | LIKE ‘%值%’ |
| notLike | NOT LIKE ‘%值%’ |
| likeLeft | LIKE ‘%值’ |
| likeRight | LIKE ‘值%’ |
| isNull | 字段 IS NULL |
| isNotNull | 字段 IS NOT NULL |
| in | 字段 IN (value1, value2, …) |
| notIn | 字段 NOT IN (value1, value2, …) |
| inSql | 字段 IN ( sql 语句 ) |
| notInSql | 字段 NOT IN ( sql 语句 ) |
| groupBy | GROUP BY 字段 |
| orderByAsc | 升序 ORDER BY 字段, … ASC |
| orderByDesc | 降序 ORDER BY 字段, … DESC |
| orderBy | 自定义字段排序 |
| having | 条件分组 |
| or | OR 语句,拼接 + OR 字段=值 |
| and | AND 语句,拼接 + AND 字段=值 |
| apply | 拼接 sql |
| last | 在 sql 语句后拼接自定义条件 |
| exists | 拼接 EXISTS ( sql 语句 ) |
| notExists | 拼接 NOT EXISTS ( sql 语句 ) |
| nested | 正常嵌套 不带 AND 或者 OR |
QueryWrapper:查询条件封装类
| 方法 | 说明 |
| — | — |
| select | 设置查询字段 select 后面的内容 |
面试资料整理汇总


这些面试题是我朋友进阿里前狂刷七遍以上的面试资料,由于面试文档很多,内容更多,没有办法一一为大家展示出来,所以只好为大家节选出来了一部分供大家参考。
面试的本质不是考试,而是告诉面试官你会做什么,所以,这些面试资料中提到的技术也是要学会的,不然稍微改动一下你就凉凉了
在这里祝大家能够拿到心仪的offer!
and | AND 语句,拼接 + AND 字段=值 |
| apply | 拼接 sql |
| last | 在 sql 语句后拼接自定义条件 |
| exists | 拼接 EXISTS ( sql 语句 ) |
| notExists | 拼接 NOT EXISTS ( sql 语句 ) |
| nested | 正常嵌套 不带 AND 或者 OR |
QueryWrapper:查询条件封装类
| 方法 | 说明 |
| — | — |
| select | 设置查询字段 select 后面的内容 |
面试资料整理汇总
[外链图片转存中…(img-oOsgz9wl-1715644120096)]
[外链图片转存中…(img-sZm8w6c1-1715644120096)]
这些面试题是我朋友进阿里前狂刷七遍以上的面试资料,由于面试文档很多,内容更多,没有办法一一为大家展示出来,所以只好为大家节选出来了一部分供大家参考。
面试的本质不是考试,而是告诉面试官你会做什么,所以,这些面试资料中提到的技术也是要学会的,不然稍微改动一下你就凉凉了
在这里祝大家能够拿到心仪的offer!















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









