







1.安装datax
(1)下载datax安装包
可在Datax官网下载,或者私信我,文件太大,无法上传
(2)解压datax压缩包
sudo tar -zxvf datax.tar.gz -C /usr/local(解压到的目录,可自己设置)(3)修改文件夹名称
mv datax.tar datax(4)给hadoop用户datax权限
sudo chown -R hadoop:hadoop /usr/local/datax2.Hive阶段
(1)启动hadoop集群
start-all.sh(2)启动hive
hive --service metastore &(3)建表
创建目录用来存储表数据
hdfs dfs -mkdir /smart_tourism_end_hive/spark_1建表语句
create external table spark_1_hive_1(
Sdate string,
overnight int,
MonthonMonth double)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION '/smart_tourism_end_hive/spark_1';//可根据自己所需数据做出相应调整2.MySQL阶段(以下以我自己的数据库和文件为例,可根据需求自己做出相应修改)
(1)
进入MySQL
mysql -u root -p(2)
创建一个新的数据库用来接收从Hive中传输过来的数据
create database smart_tourism;使用该数据库
use smart_tourism;(3)创建表
create table spark_1_hive_1(Sdate varchar(255),overnight int,MonthMonth double);3. 配置datax配置文件(下面文件和目录均以我自己的为例,可根据自己的需求自行修改)
(1)
创建一个目录用来存放datax配置文件
mkdir smart_tourism(2)
在该目录下创建spark_1_hive_1.json文件
touch spark_1_hive_1.json(3)
使用vim spark_1_hive_.json打开文件并写入下列内容
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"defaultFS": "hdfs://master:9000",
"path": "/smart_tourism_end_hive/spark_1/*",//这里的路径是hive中要迁移表的数据存储路径
"column": [
{
"index": "0",
"type": "string"
},
{
"index": "1",
"type": "string"
},
{
"index": "2",
"type": "string"
}
],//上述一个index代表表中的一个字段,要迁移的表中有几个字段就写几个index,type是字段类型,要与迁移表中字段类型相匹配
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","//这是字段分隔符,要与hive建外部表时的分隔符一致
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"password": "123456",//MySQL用户密码
"username": "root",//MySQL用户名
"connection": [
{
"jdbcUrl":"jdbc:mysql://master:3306/smart_tourism?useUnicode=true&characterEncoding=utf8",//smart_tourism是MySQL中用于接收数据的数据库名称
"table": [
"spark_1_hive_1"//MySQL用于接收数据的表名
]
}
],
"column": [
"Sdate","overnight","MonthMonth"//MySQL表中的字段,与Hive表中字段名一致即可
],
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
},
"errorLimit": {
"record": 0
}
}
}
}(4)
切换到datax目录
cd ..
运行脚本
python bin/datax.py smart_tourism/spark_1_hive_1.json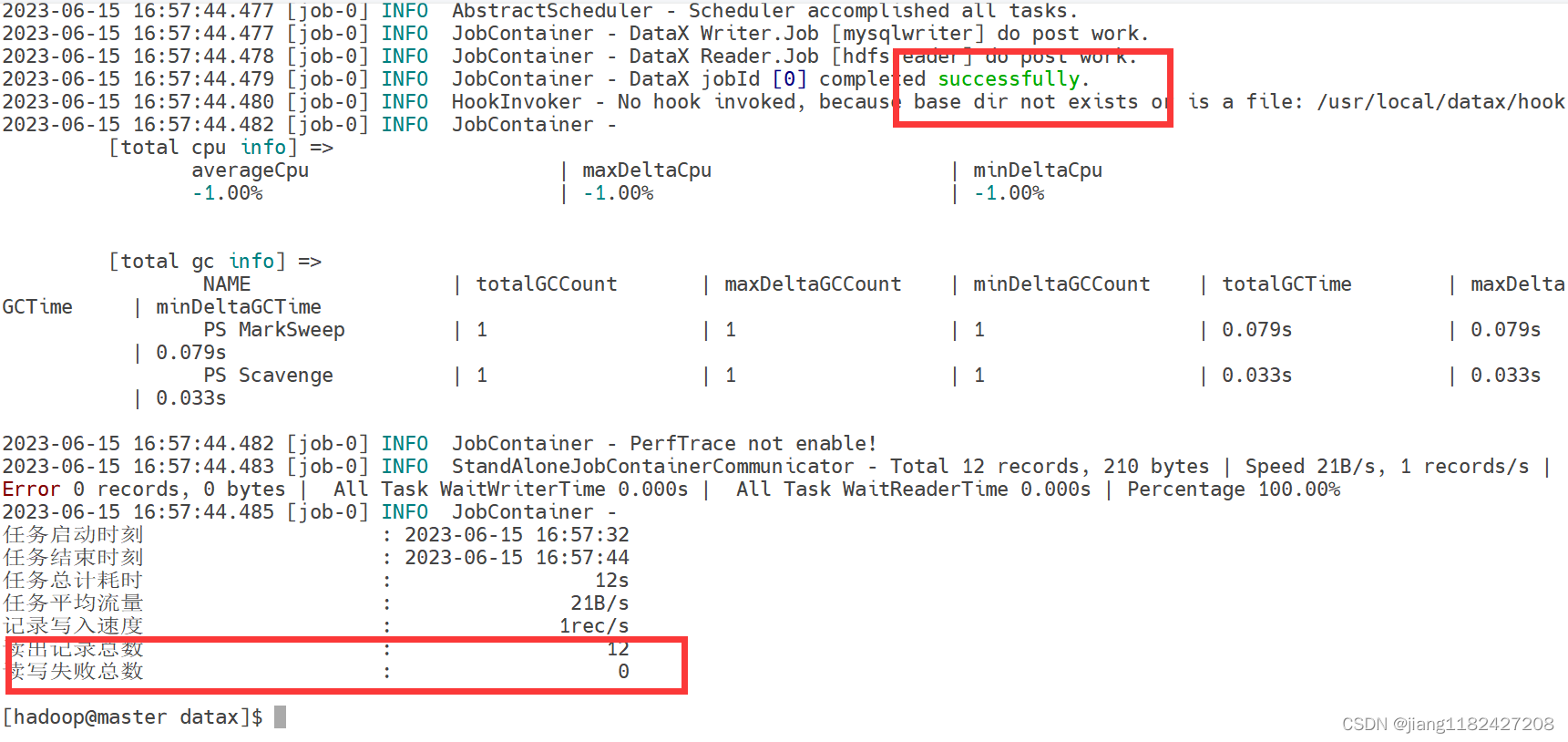
出现这两个标志就代表数据迁移成功
(5)去MySQL查询表中是否有数据
select * from spark_1_hive_1;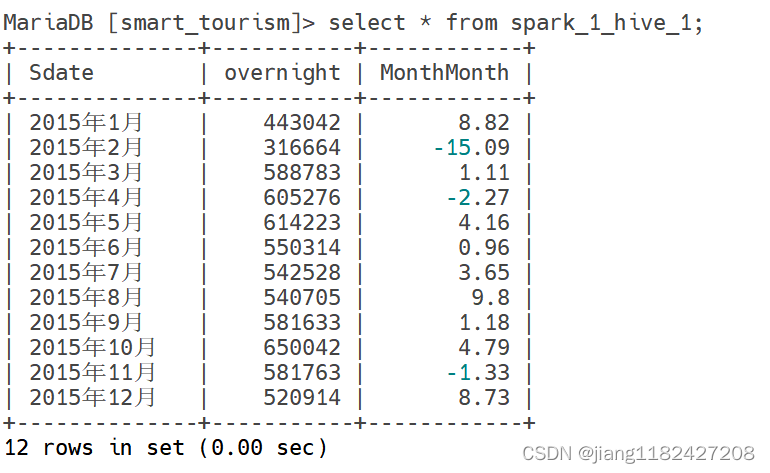
数据存在,迁移成功!















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









