






摘要: 通过前面一节的介绍,你是否已经可以感受到Marklogic的强大,前端UI 工程师设计好页面,我们只需要一个XQuery文件就可以做到保存到数据库操作,本节继续通过实例来讲解Marklogic 8.
编码
后台管理员一般需要知道现存书籍的概况,因此还需要一个查询接口用于得到所有的图书信息,还需要一个界面展示这些信息。
首先需要一个service 来从数据库中获取书籍信息 findbook.xqy
xquery version "1.0-ml";
declare namespace html = "http://www.w3.org/1999/xhtml";
let $dir := "/book/"
let $query := cts:and-query(cts:directory-query($dir,"infinity"))
let $results := cts:search(fn:doc(),$query)
let $books := element books {for $book in $results/book return
element book {
attribute id {$book/@id},
element title {$book/title/string()},
element author {$book/author/string()},
element page {$book/pages/string()}
}
}
return $books
此时,我们已经得到了所有书籍的数据,但是为了页面方便使用这些数据, 我们可以将这个XML输出转换为JSON格式。
使用json:transform-to-json函数可以方便地做json转换,选择custom做自定义转化,还需要将输出结果中的array告诉转换方法,不然在转换数组元素时,只能得到第一组数据。
let $config := json:config("custom") ,
$_ := map:put( $config, "array-element-names", "book")
return
json:transform-to-json( $books, $config )为了方便以后使用,还可以将转化功能封装成函数,最终修改后的 findbook.xqy
xquery version "1.0-ml";
declare namespace html = "http://www.w3.org/1999/xhtml";
import module namespace json="http://marklogic.com/xdmp/json"
at "/MarkLogic/json/json.xqy";
declare function local:xml-to-json($node as node(),$array-name as xs:string*){
let $config := json:config("custom") ,
$_ := map:put( $config, "array-element-names", $array-name)
return
json:transform-to-json( $node , $config )
};
let $dir := "/book/"
let $query := cts:and-query(cts:directory-query($dir,"infinity"))
let $results := cts:search(fn:doc(),$query)
let $books := element books {for $book in $results/book return
element book {
attribute id {$book/@id},
element title {$book/title/string()},
element author {$book/author/string()},
element page {$book/pages/string()}
}
}
return local:xml-to-json($books,("book"))需要注意的是,json并不是Marklogic build-in 命名空间,使用时需要手动引入。定义$array-name 为 xs:string*类型,因为这一参数有可能传人多个。
展示书籍信息的界面很简单,只需要列出刚查询到的数据即可:
首先有一个展示基础界面:showbooks.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Books Information</title>
</head>
<body>
<h2 align="center">books Information</h2>
<table align="center" id="details">
<tr>
<th>I D</th>
<th>标题</th>
<th>作者</th>
<th>页数</th>
</tr>
</table>
</body>
<script type="text/javascript" src="jquery-1.7.2.js"></script>
<script type="text/javascript" src="showbook.js"></script>
</html>我把展示信息的逻辑代码放到了js文件中 : showbook.js
$("document").ready(function (){
$.ajax({
url:"findbook.xqy",
type:"get",
dataType:"json",
success:function(data){
$.each(data.books.book, function(commentIndex, comment){
$("#details").append(
"<tr>" +
"<td> <input type='text' value="+comment.id+"></td>" +
"<td> <input type='text' value="+comment.title+"></td>" +
"<td> <input type='text' value="+comment.author+"></td>" +
"<td> <input type='text' value="+comment.page+"></td>" +
"</td>"
);
});
}
});
})这里使用jquery简化代码,使用ajax请求来获取数据,使用的url就是之前xquery方法。
执行
将findbook.xqy文件放到之前创建的workML目录下。
将showbook.html文件拷贝到workML目录下。
将showbook.js文件拷贝到workML目录下。
将jquery文件拷贝到workML目录下。
要确保这些文件在同一目录下。
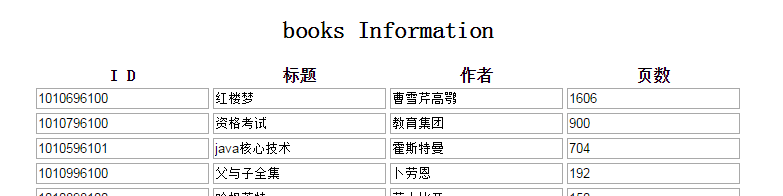
载浏览中访问http://localhost:8866/showbook.html,可以看到已经展示出了书籍信息。
总结
通过两个例子的介绍,已经可以讲述清楚Marklogic在项目开发过程中,如果施展其能力。常用的方法莫过于增查改删,其中,最常使用的就是查询方法了,而Marklogic在这方面有着独特的优势。上面的例子中,查询方法并不复杂,结果类型可以方便转换。只要约定好数据结构,前后台开发可以完全分离。可以方便地定义函数,并调用。当然,这里我们没有考虑数据容量大小,如果有很多数据时,可以考虑分段查询,没有加入过滤条件,我们可以查询出只符合某些条件的数据,这些功能实现起来都很简单,在之后涉及到优化代码的时候,再举例说明。


















 3037
3037




 到【灌水乐园】发言
到【灌水乐园】发言









