






授课教师:胡玥 曹亚男
文档由中国科学院大学-网络空间安全学院-网安2006班:杨桂淼、林彤、乔宇轩、刘熙宸
整理完成
来嘞您呐!没错,就是为的这点醋包的这顿饺子~
《自然语言处理基础》最新真题复盘
文档整理不易,如果对你有帮助,烦请点个赞吧^_^
我们总结的飞书复习文档:https://ncnjbpvneffw.feishu.cn/wiki/U7OswO7OViqMgFkmTjlcYVxtn4e?from=from_copylink
课程架构总览
最好的复习方法就是任务导向,这学期学完了这门课,要知道NLP领域内基本的任务类型是什么、核心技术有哪些、解决不同任务所对应的模型方法是什么。
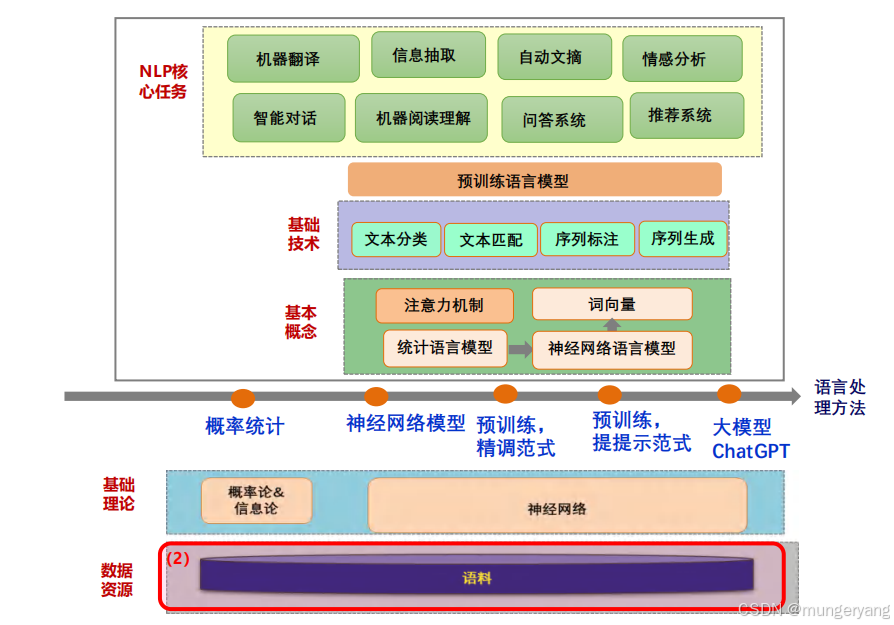
复习指南

NLP各范式概念
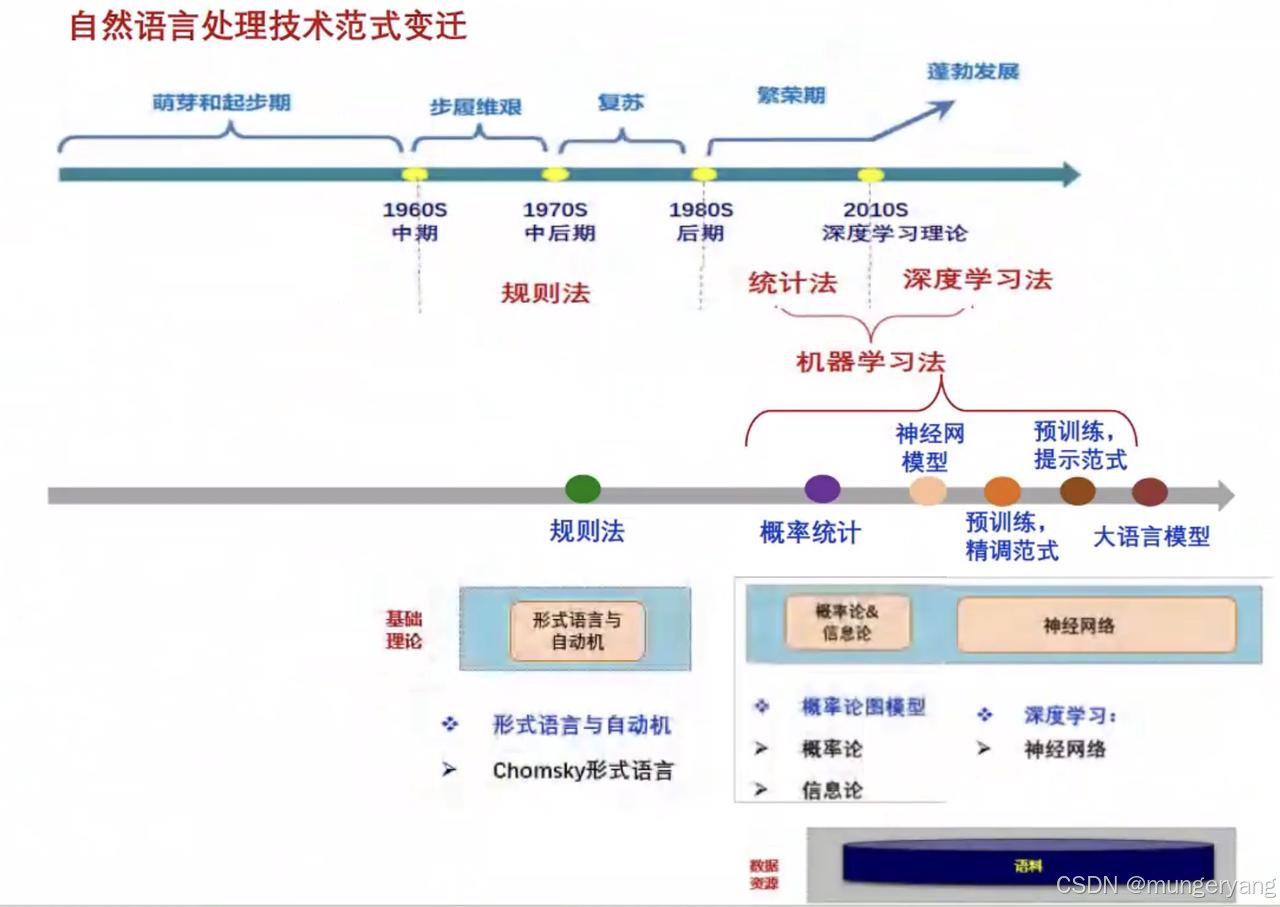
NLP机器学习任务经历了五次范式变迁:
第一范式 - 概率统计时代:特征工程+算法
第二范式 - 深度学习时代:自动获取特征(表示学习)端到端分类
第三范式 - 预训练 + 精调范式:大量预训练数据 + 少量任务数据
第四范式 - 预训练 + 提示范式:少量/无任务数据
第五范式 - 大模型AGI
2024年秋学期-期末考试真题回忆
家人们,能记住多少算多少哈哈哈哈~
考试时间:2025年1月6日
选择题 10 * 1
1. CBOW训练的是什么
2. skip_gram训练的是什么
3. 激活函数有什么作用:增强网络表达能力
4. 指针网络的作用:不仅可以用于机器翻译任务,还可以用于其他任务
5. 词向量之间相似的原因解释
6. Attention的输入
7. top-k采样、贪心解码相关
8. Chatgpt相关的问题不正确的是:每次使用都是先微调
还有两个记不起来了~
填空题 10*2
1.机器学习三要素
2. 池化层作用是什么
3. 什么是硬注意力
4. BART中为什么要使用位置嵌入
5. Seq2Seq序列生成模型的三种类型
6. CRF的作用是什么
7. 生成任务中常用的评价指标是什么
8. RNN训练方法是什么
9. 文本匹配常用的建模方法
10. 什么是曝光偏差
简答题 5*6
1. 什么是BPE算法?简要概述其工作原理
2. Transformer实现并行处理所用到的技术有哪些?
3. 神经网络语言语言模型存在的问题?使用RNN+词向量的方式是如何解决这些问题的
4. 简述第二、三、四、五范式特点和应用场景
5. 简述传统的事件抽取任务,并给出传统的事件抽取的建模任务有哪些?具体实现步骤
计算题 10*1
维特比算法
设计题1 12*1
题干记得是:“这是一家正宗的俄式西餐,味道浓厚,环境很好”
(1) 写出属性情感输出
(2) 设计一个情感属性关联模型,解释其原理,画出模型图
设计题2 18*1
(1) 检索式问答系统包含哪几个部分?作用是什么?
(2) 设计一个检索式问答系统,并解释其原理
2024前考过的简答题
Attention是什么?其在NLP领域有什么应用?优势是什么?
Attention 是一种注意力机制,用于让模型在处理输入序列时,动态地关注输入中的某些部分,而忽略其他部分。它通过计算输入序列中每个元素与目标输出的相关性分数(注意力权重),来决定哪些输入部分对当前任务最重要。
应用领域:
-
机器翻译:如 Transformer 中的自注意力机制(Self-Attention)。
-
文本摘要:提取文本中最重要的信息。
-
阅读理解与问答系统:关注问题相关的文本片段。
-
图像字幕生成:结合图像与语言,关注特定的图像区域生成描述。
优势:
-
捕获长距离依赖关系:相比 RNN,Attention 可以更有效地捕获输入序列中远距离的依赖。
-
并行化计算:特别是 Transformer 中的 Attention,计算可以高效并行化。
-
增强模型解释性:Attention 提供了直观的可视化权重,方便观察模型重点关注的输入部分。
指针网络与指针生成网络的异同
相同点:都使用注意力机制,能够在输入中选择重要的部分。
不同点:
-
指针网络用于输出索引(如位置),而指针生成网络既可选择输入的词,也可从词汇表生成新词。
-
指针生成网络更复杂,结合了生成机制与复制机制
预训练第三范式和预训练第四范式异同
预训练第三范式为预训练+精调范式,预训练第四范式为预训练+提示+预测范式
参数调整方面:第三范式需要对下游任务的模型参数进行精调,第四范式不调整模型参数,通过提示控制输入实现任务适配。
训练成本方面:第三范式每个任务需要精调,训练成本较高;第四范式不需要任务精调,直接用预训练模型推断,成本低。
性能表现方面:第三范式对于任务数据充足的场景,精调性能通常优于提示方法;第四范式在数据不足场景下,提示方法可以更快部署、实现更高的效果。
灵活性方面:第三范式每次训练生成专属任务模型,适合特定任务优化;第四范式模型泛化性强,可以快速适配多种任务。
RNN语言模型与DNN语言模型相比有什么优势
RNN语言模型的优势:
-
适合处理序列数据:RNN 天然能够处理变长输入序列,捕获上下文信息。
-
记忆历史信息:通过隐藏状态 hth_tht 能够记忆之前的输入,建模长短依赖关系。
-
动态序列建模:在生成任务中,RNN 能逐步生成序列,不需要固定输入长度。
GPT与BERT异同
相同点:两者都是用了Transformer架构,都使用自注意力机制(Self-Attention)来捕获序列的上下文依赖。
不同点:
-
GPT 只使用解码器部分,而 BERT 只使用编码器部分
-
GPT使用自回归语言模型预测下一个词,BERT使用遮掩语言模型预测遮掩的词语
-
GPT为单项输入,BERT为双向输入
词向量的特点是什么?在NLP领域有什么价值?
词向量的特点:
-
稠密性:词向量是低维稠密向量,相较于传统的独热编码(One-Hot Encoding),更高效。
-
语义相似性:相似词的向量在嵌入空间中距离更近。
-
可训练性:词向量是通过模型(如 Word2Vec、GloVe、FastText)从大规模语料中学习得到的。
在 NLP 领域的价值:
-
降低维度:将高维的离散词表转化为低维稠密向量,减少计算复杂度。
-
捕获语义关系:词向量能够反映词的语义相似性和上下文关系。
-
迁移学习:预训练的词向量可以作为多种 NLP 任务(如分类、命名实体识别)的基础,提升下游任务性能。
-
丰富上下文信息:通过上下文训练的动态词向量(如 ELMo、BERT)进一步捕获词的多义性和上下文依赖性。
浓缩版总结内容欢迎访问博客:自然语言处理基础总结复习 - munger写字的地方
参考资料与致谢
胡玥 曹亚男.中国科学院大学网络空间安全学院课程-《自然语言处理基础》
李宏毅.机器学习教程
邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.
B站-风骨散人Chiam学长的复习资料:2021 年国科大NLP自然语言处理(胡玥老师)考试及部分答案 - 哔哩哔哩



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











