







最近在学习《集体编程智慧》的第三章节,里面在对数据的提取中使用了正则表达式,网上的解说有很多,但是感觉不具体,有些术语,给人一种不明觉厉的感觉,而且文章的例子太少,多是文字和表格解说型的,不好理解 ,于是在自己学习了相关内容后,用自己的话语来写一篇关于正则表达式的文章,多多指教:
什么是正则表达式:
正则表达式(或者RE)是一种小型的、高度专业化的编程语言,它内嵌于python 中,并能过re模块来实现对它的操作。在以下几种情况下会使用到正则表达式:
*1.字符串匹配
2.指定字符串替换
3.指定字符串查找,例如寻找英文语句,e-mail地址、命令等
4.字符串分割*
先上几道凉菜,不过,没耐心或者有基础的也可以直接进入正餐~
1.re的简介
使用python的re模块,尽管不能满足所有复杂的匹配情况,但足够在绝大多数情况下能够有效地实现对复杂字符串的分析并提取出相关信息。
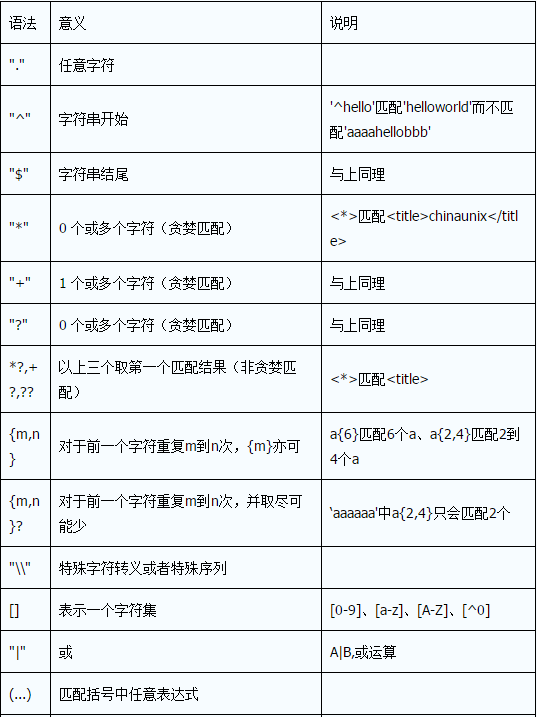
2.re的正则表达式语法
正则表达式语法表如下:
文章读到此处,你可能就有点没耐心了,好菜才开始上桌,客官你请慢慢品尝。
在python中使用正则表达式,我们需要先自己定义一个正则式,然后把你的正则式与你需要的字符串进行匹配,实现你想要的功能,那怎样去定义这个正则式呢,我们先看一个例子
import re
s = r'abc' #正则式
print re.findall(s, "aaaa") #在目标字符串 "aaaa"匹配正则式
print re.findall(s, "abcaaaaaaa")output
[]
[‘abc’]
看到这里,你是不是想问,为什么正则式中会出现个’r’,原因是有各种各样的字符,当它们在正则表达式中使用,将有特殊的意义。为了避免在处理正则表达式的任何困惑,将使用原始字符串作为r’expression(expression为原始数据,作为匹配项)“,即,无论里面有没有像’\’, ‘+’这种特殊字符,都按原始数据来匹配,不用考虑其特殊含义。
正则表达式中的常用的元字符有下几种,它们使得匹配规则更加灵活
. ^ $ * + ? {} [] \ | ()- []
表示一个字符集,[0-9]、[a-z]、[A-Z]分别表示0-9中的一个数字,任意一个小写字母,任意一个大写字母
input
import re
st = "top tip tqp twp tep"
res = r't[io]p' #查找top,tip,即匹配 []里面的一个字符
print re.findall(res, st)output:
[‘top’, ‘tip’]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









