







spark-sumit脚本
假如Spark提交的命令如下:
bin/spark-submit --jar lib/spark-examples-1.3.1-hadoop2.6.0.jar --class cn.spark.WordCount --master spark://master:7077 --executor-memory 2g --total-executor-cores 4 其shell脚本的核心执行语句:
exec "$SPARK_HOME"/bin/spark-class org.apache.spark.deploy.SparkSubmit "${ORIG_ARGS[@]}"
exec "$RUNNER" -cp "$CLASSPATH" $JAVA_OPTS "$@"org.apache.spark.deploy.SparkSubmit
先看下其伴生对象的main方法
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
printStream.println(appArgs)
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sysProps: Map[String, String],
childMainClass: String,
verbose: Boolean): Unit = {
/* only keep the core codes */
//childMainClass就是前面spark-sumit中的--class cn.spark.WordCount
mainClass = Class.forName(childMainClass, true, loader);
//获得WordCount类中的main方法
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
//触发了WordCount.main方法
mainMethod.invoke(null, childArgs.toArray)
}上面的代码运行后,通过反射机制,我们定义的代码被执行了,比如我的写的WordCount如下:
object WordCount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
val sc=new SparkContext(conf)
val rdd=sc.textFile("/tmp/word.txt");
val rdd1=rdd.flatMap(_.split("\\s")).map((_,1)).reduceByKey(_+_)
rdd.collect()
sc.stop()
}
}SparkContext
SparkContext是进入Spark的唯一入口,在SparkContext被初始化的时候主要做了如下的事情
private[spark] val env = createSparkEnv(conf, isLocal, listenerBus)
private[spark] var (schedulerBackend, taskScheduler) =SparkContext.createTaskScheduler(this, master)
@volatile private[spark] var dagScheduler: DAGScheduler = _
dagScheduler = new DAGScheduler(this)
taskScheduler.start()1.创建了SparkEnv(ActorSystem),负责driver和excutor的通信
2.创建了DagScheduler
3.创建了TaskScheduler,并启动了taskScheduler
SparkEnv
sparkEnv主要负责Spark之间的通信,Spark1.3使用的是Akka,Spark1.6之后变成了Netty(其实akka的底层就是netty)
private[spark] def createSparkEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus): SparkEnv = {
SparkEnv.createDriverEnv(conf, isLocal, listenerBus)
}private def create(
conf: SparkConf,
executorId: String,
hostname: String,
port: Int,
isDriver: Boolean,
isLocal: Boolean,
listenerBus: LiveListenerBus = null,
numUsableCores: Int = 0,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
// Listener bus is only used on the driver
if (isDriver) {
assert(listenerBus != null, "Attempted to create driver SparkEnv with null listener bus!")
}
val securityManager = new SecurityManager(conf)
// Create the ActorSystem for Akka and get the port it binds to.
val (actorSystem, boundPort) = {
val actorSystemName = if (isDriver) driverActorSystemName else executorActorSystemName
AkkaUtils.createActorSystem(actorSystemName, hostname, port, conf, securityManager)
}
//......
}
如下贴出Spark提交时的工作图,里面的有些内容在之后的章节中提及到
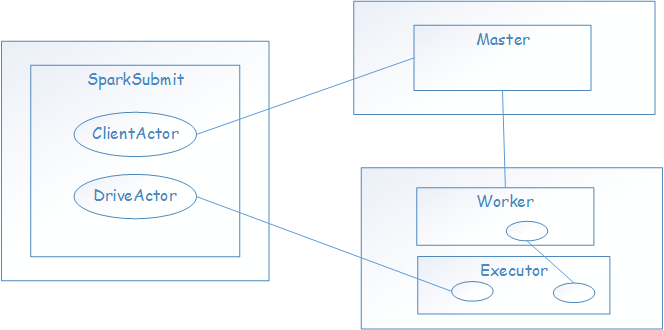
啰嗦下:最近忙着开题都没有时间玩Spark了,加上最近有点感冒,博客也没时间写了..















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









