







 本文介绍了如何利用MapReduce进行矩阵相乘操作,重点讨论了矩阵的稀疏存储和MapReduce计算模型。通过测试数据和程序代码展示了具体实现过程,并给出了运行结果。
本文介绍了如何利用MapReduce进行矩阵相乘操作,重点讨论了矩阵的稀疏存储和MapReduce计算模型。通过测试数据和程序代码展示了具体实现过程,并给出了运行结果。
前言
MapReduce打开了并行计算的大门,让我们个人开发者有了处理大数据的能力。但想用好MapReduce,把原来单机算法并行化,也不是一件容易事情。很多的时候,我们需要从单机算法能否矩阵化去思考,所以矩阵操作就变成了算法并行化的基础。
矩阵介绍
为了方便说明,举两个矩阵作为示例:
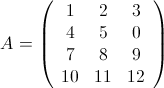 ,
,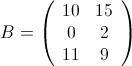
容易看出,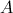 是一个
是一个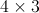 矩阵,
矩阵,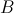 是一个
是一个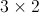 矩阵,我们能够算出:
矩阵,我们能够算出:
是一个矩阵,是一个矩阵,我们能够算出:
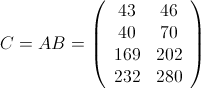
这三个矩阵当然不大,但作为示例,它们将暂时享受大矩阵的待遇。
矩阵稀疏存储
理论上,在一个文件中存储4000万*4000万的矩阵当然是可以的,但非常失之优雅,因为这意味着在一条记录中挤下4000万个变量的值。
我们注意到,根据海量数据构造的矩阵,往往是极其稀疏的。比如4000万*4000万的相似度矩阵,一般来说,如果平均每个用户和1万个用户具有大于零的相似度,常识告诉我们,这样的关系网络已经非常密集了(实际网络不会这样密集,看看自己的微博,被你关注的、评论过的、转发过的对象,会达到1万个吗?);但对于4000万维度的矩阵,它却依然是极度稀疏的。
因此,我们可以采用稀疏矩阵的存储方式,只存储那些非零的数值。具体而言,存储矩阵的文件每一条记录的结构如下:
其中,第一个字段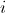 为行标签,第二个字段
为行标签,第二个字段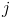 为列标签,第三个字段值为
为列标签,第三个字段值为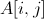 。
。
为行标签,第二个字段为列标签,第三个字段值为。
比如矩阵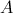 在HDFS中存储为
在HDFS中存储为
在HDFS中存储为
1 1 1
1 2 2
1 3 3
2 1 4
2 2 5
3 1 7
3 2 8
3 3 9
4 1 10
4 2 11
4 3 12
矩阵 存储为
存储为
存储为
1 1 10
1 2 15
2 2 2
3 1 11
3 2 9
注意到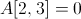 ,
,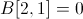 ,这样的值不会在文件中存储。
,这样的值不会在文件中存储。
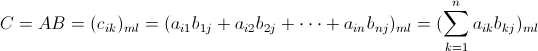
,,这样的值不会在文件中存储。MapReduce计算模型
回顾一下矩阵乘法。
设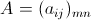 ,
,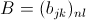 ,那么
,那么
,,那么
矩阵乘法要求左矩阵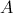 的列数与右矩阵
的列数与右矩阵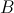 的行数相等,
的行数相等,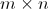 的矩阵
的矩阵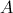 ,与
,与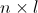 的矩阵
的矩阵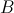 相乘,结果为
相乘,结果为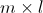
的列数与右矩阵的行数相等,的矩阵,与的矩阵相乘,结果为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









