







插曲
在上篇文章《推荐升级四部曲之 CDH 升级重头戏,收藏了!》中,一些人因为善良而容易相信初次看到的事情,觉得升级过程那么那么那么地顺风顺水,正准备养精蓄锐,大干一场,升级换代,大数据平台再续10年。
不过,笔者可能要泼冷水了。在本篇文章开头,笔者需要澄清一下,测试环境经过两次升级操作都没有自动升级一路到头的情况,最后都是需要通过手动升级捡回一条命。
简而言之,大部分升级过程中总会出现各种意外的情况,自动升级失败后,没关系,我们接着手动升级。
说明一二
阅读本篇文章的过程中,请参考自动升级失败后的手动升级指导文档:
https://docs.cloudera.com/documentation/enterprise/upgrade/topics/ug_cm_wizard_actions.html
笔者是在自动升级到 HDFS 过程中失败的,则本篇文章重点会从 HDFS 升级步骤(步骤 3)开始进行手动升级,升级前的准备工作请参考上篇文章《推荐升级四部曲之 CDH 升级重头戏,收藏了!》。
手动升级 CDH 集群
步骤 1: 启动 ZooKeeper
查看 Zookeeper 是否启动,如果未启动,则执行如下操作:
进入 Zookeeper 服务
选择 Actions > Start
步骤 2: 启动 Kudu
查看 Kudu 是否启动,如果未启动,则执行如下操作:
进入 Kudu 服务
选择 Actions > Start
前面两步骤,正常情况下都不会出错。
步骤 3: 升级 HDFS Metadata
回顾 NameNode 自动升级失败的情况
首先回顾一下,笔者在自动升级中遇到的问题是:
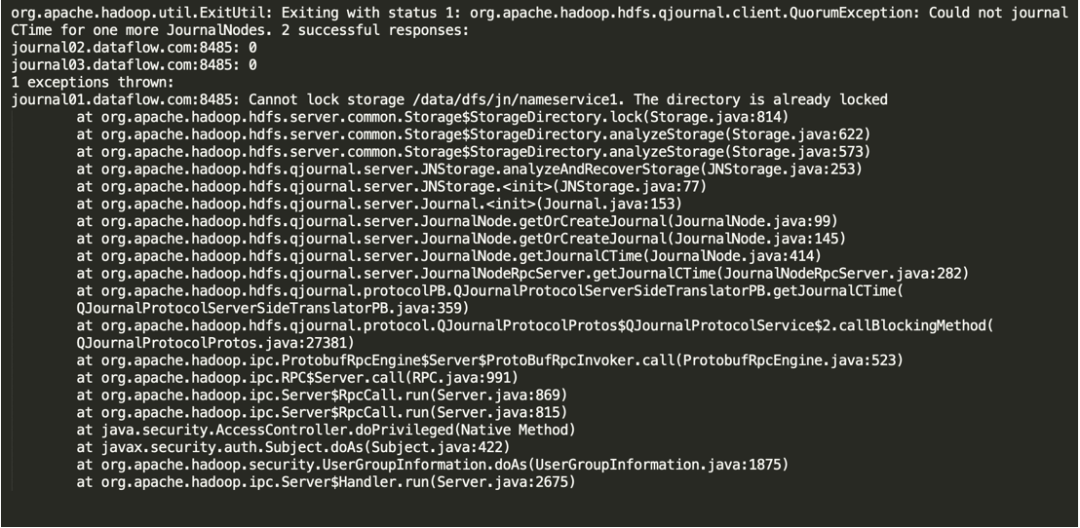
INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: org.apache.hadoop.hdfs.qjournal.client.QuorumException: Could not journal CTime for one more JournalNodes. 2 successful responses:
journal02.dataflow.com:8485: 0
journal03.dataflow.com:8485: 0
1 exceptions thrown:
journal01.dataflow.com:8485: Cannot lock storage /data/dfs/jn/nameservice1. The directory is already locked
...
经过查看 NameNode 的日志进行定位分析,发现 JournalNode 其中一个节点(journal01.dataflow.com)VERSION 丢失,但是升级前所有节点的服务正常。
因为 HDFS 各角色都提供了高可用,所以接下来就需要对损坏的 JournalNode 节点 journal01.dataflow.com 进行修复。
删除 JournalNode 损坏节点数据存储目录 /data/dfs/jn/nameservice1/current/ 下的所有数据
rm -rf /data/dfs/jn/nameservice1/current/*
从其他正常的 JournalNode 节点拷贝 VERSION 文件到 /data/dfs/jn/nameservice1/current/ 目录下,并修改权限
# 2.1 拷贝 VERSION 文件
# 2.2 修改权限
chown -R hdfs:hdfs /data/dfs/jn/nameservice1/current
然后重启 JournalNode 节点,服务启动正常。
上面是自动升级发生的问题以及解决思路,接下来,笔者开始通过手动方式来继续升级 HDFS。
进入 HDFS 服务
选择 Actions > Upgrade HDFS Metadata 执行
执行该操作之前,确保 HDFS 所有服务已经正常停止。
首次执行 Upgrade HDFS Metadata 失败
在执行 Upgrade HDFS Metadata 过程中,NameNode 启动失败,错误日志如下:
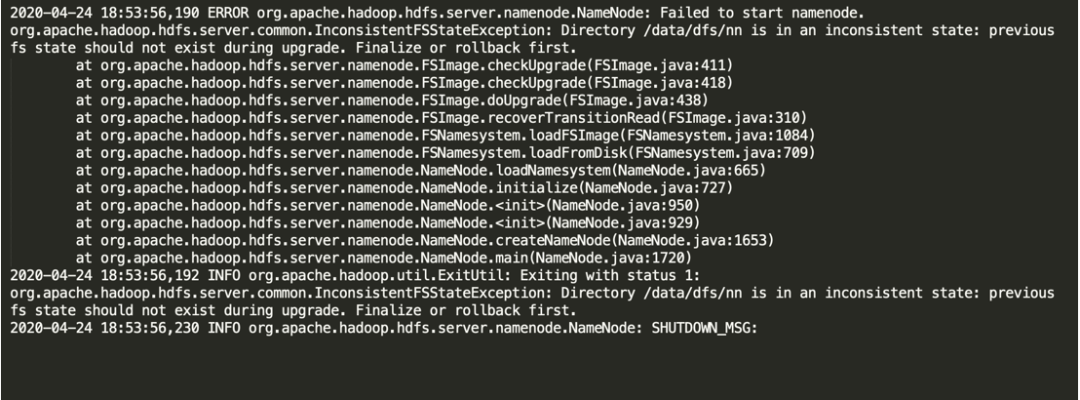
ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /data/dfs/nn is in an inconsistent state: previous fs state should not exist during upgrade. Finalize or rollback first.
这个错误产生的原因是,在之前自动升级过程中,JournalNode 和 NameNode 产生的 previous 目录,其实到此时,NameNode 还未进行元数据升级操作。解决这个问题比较简单,进行如下操作:
三个 JournalNode 节点
mv /data/dfs/jn/nameservice1/previous /data/dfs/jn/nameservice1/previous_bak
两个 NameNode 节点
其实只有执行升级的一个 NameNode 节点存在该目录
mv /data/dfs/nn/previous /data/dfs/nn/previous_bak
第二次执行 Upgrade HDFS Metadata 失败
首先停止第一次执行 Upgrade HDFS Metadata 时启动的全部服务,然后再次执行 Upgrade HDFS Metadata。
本次执行 HDFS Metadata 升级时,发现第一个执行升级的 NameNode(Active) 已经启动成功,但是第二个 NameNode(Standby) 节点失败,错误日志如下:
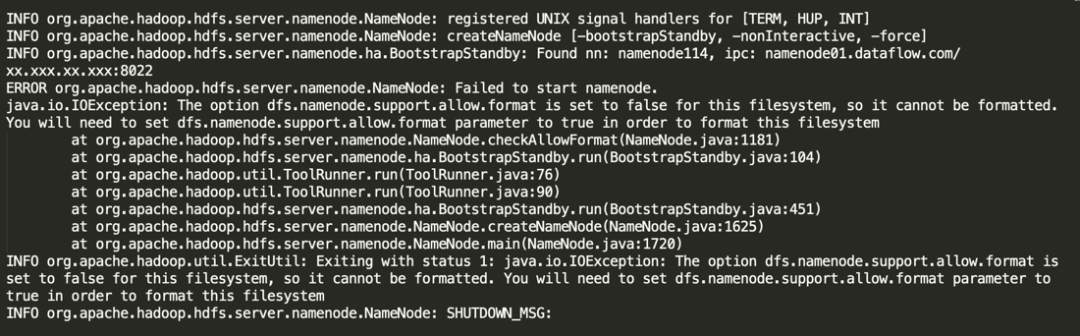
ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
java.io.IOException: The option dfs.namenode.support.allow.format is set to false for this filesystem, so it cannot be formatted. You will need to set dfs.namenode.support.allow.format parameter to true in order to format this filesystem
一般在生产环境中,为了保证 HDFS 数据的安全,会禁用 namenode format 操作,所以将 dfs.namenode.support.allow.format 设置为 false。
针对 HDFS 升级操作,需要在 CM 上将 dfs.namenode.support.allow.format 参数值设置为 true,升级完成后再设置 false,切记不要忘记。
然后我们再次清理一下环境:
停止 HDFS 所有服务
对 JournalNode 和 NameNode 节点的 previous 目录再重命名操作
第三次执行 Upgrade HDFS Metadata 失败
第三次执行 Actions > Upgrade HDFS Metadata 操作,成功完成 HDFS Metadata 升级,并启动 HDFS 所有服务。
其实设置 dfs.namenode.support.allow.format 后,直接重启 HDFS 服务就可以了,不需要再次执行 Actions > Upgrade HDFS Metadata 操作,因为 NameNode(Active) 已经完成了升级操作。
步骤 4: 启动 HBase
HDFS 启动成功后,开始启动 HBase,但是继续报错:
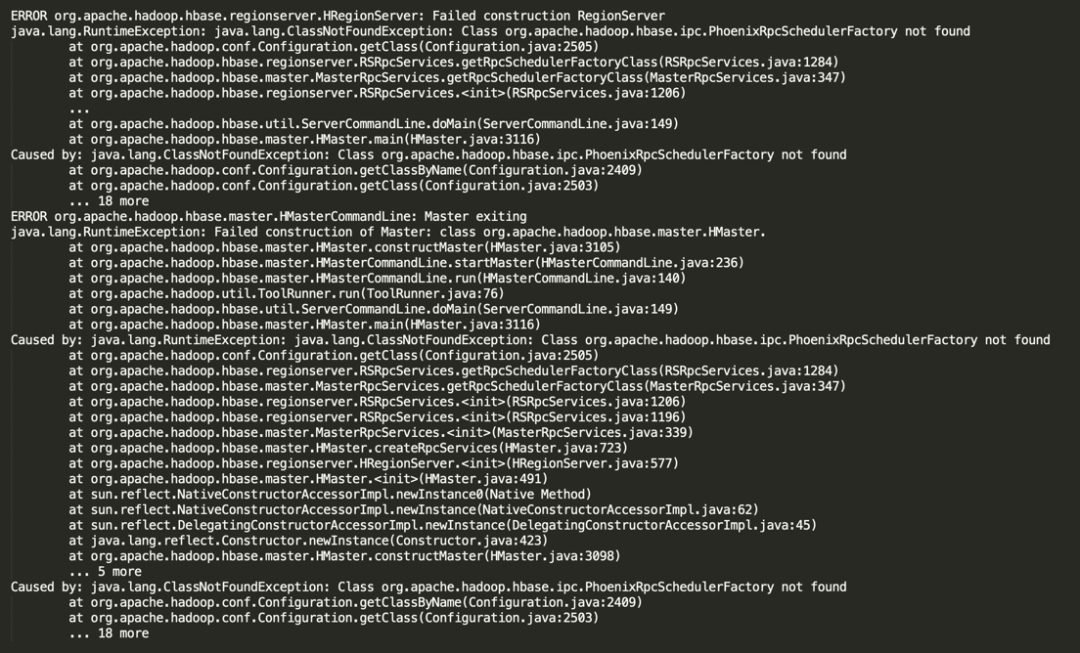
ERROR org.apache.hadoop.hbase.regionserver.HRegionServer: Failed construction RegionServer
java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory not found
...
ERROR org.apache.hadoop.hbase.master.HMasterCommandLine: Master exiting
java.lang.RuntimeException: Failed construction of Master: class org.apache.hadoop.hbase.master.HMaster.
...
这里的错误其实很清晰,因为 CDH 5.16.2 环境中部署了 Phoenix 组件,HBase 参数配置了 Phoenix 的一些类,启动时依赖这些 Jar 包。如果想在 CDH 6.3.3 版本中继续使用,需要把 Phoenix Jar 包拷贝到 CDH 6.3.3 对应的环境中,但是 CDH 升级到 6.3.3 版本后,HBase 版本从 1.2 升级到了 2.1 版本,因此 Phoenix 也需要升级。
为了先把 HBase 服务正常启动起来,临时把 Phoenix 有关的配置从 HBase 中删除,以后升级 Phoenix 后再重新配置。
步骤 5: 升级 Sentry 数据库
根据官网文档说明,需要满足如下升级条件:
CDH 5.x to 5.8.x
CDH 5.x to 5.9.x
CDH 5.x to 5.10.x
CDH 5.x to 5.13.x
CDH 5.x to 6.0.0 或以上版本
升级 Sentry 数据库操作如下:
进入 Sentry 服务
如果 Sentry 服务启动,则需要停止
选择 Actions > Upgrade Sentry Database Tables 执行升级操作
如果使用 Oracle 数据库,需要参考官网创建索引
步骤 6: 启动 Sentry
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
启动 Sentry 服务:
进入 Sentry 服务
选择 Actions > Start,启动 Sentry 服务
步骤 7: 启动 Kafka
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
启动 Kafka 服务:
进入 KAFKA 服务
选择 Actions > Start,启动 Kafka 服务
步骤 8: 升级 Solr
未部署,忽略。
步骤 9: 启动 Flume
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
启动 Kafka 服务:
进入 Flume 服务
选择 Actions > Start
步骤 10: 升级 KeyStore Indexer
未部署,忽略。
步骤 11: 启动 Key-Value Store Indexer
未部署,忽略。
步骤 12: 升级 Yarn
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
升级 Yarn 过程如下:
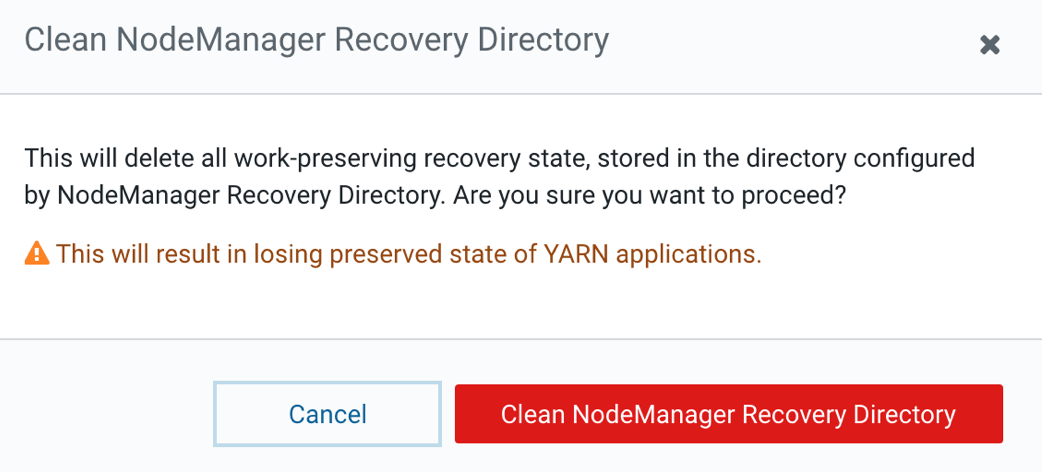
确保 Zookeeper 和 HDFS 服务正常运行
确保 Yarn 服务停止状态
进入 Yarn 服务
选择 Actions > Clean NodeManager Recovery Directory 执行操作
步骤 13: 安装 MR Framework Jars
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
如果使用 OpenJDK 11,任何升级到 CDH 6.3.0 以及以上版本都需要执行。
如果满足如上任一条件,执行:
进入 Yarn 服务
选择 Actions > Install YARN MapReduce Framework JARs 执行操作
如果忘记执行该操作,通过 beeline 访问 Hive,并提交 SQL 查询时,报如下错误:
ERROR : Job Submission failed with exception 'java.io.FileNotFoundException(File does not exist: hdfs://nameservice1/user/yarn/mapreduce/mr-framework/3.0.0-cdh6.3.3-mr-framework.tar.gz)'
java.io.FileNotFoundException: File does not exist: hdfs://nameservice1/user/yarn/mapreduce/mr-framework/3.0.0-cdh6.3.3-mr-framework.tar.gz
该步骤其实就是创建 HDFS 目录 /user/yarn/mapreduce/mr-framework,并上传 3.0.0-cdh6.3.3-mr-framework.tar.gz。
步骤 14: 启动 Yarn
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
启动 Yarn 服务:
进入 YARN 服务
选择 Actions > Start
步骤 15: 部署 Client 配置文件
登录 Cloudera Manager,执行 Deploy Client Configuration,分发 Client 配置。
步骤 16: 升级 Spark Standalone
未部署,忽略。
步骤 17: 启动 Spark 服务
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
升级到 CDH 6.3.3 版本后,所有 SPARK 和 SPARK2 不再区分,统一为 SPARK。
启动 Spark 服务:
进入 Spark 服务
选择 Actions > Start
步骤 18: 升级 Hive Metastore Database
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
升级 Hive Metastore 数据库步骤如下:
进入 Hive 服务
如果 Hive 服务处于启动状态,请停止。
选择 Actions > Upgrade Hive Metastore Database Schema 执行操作
如果有多个 Hive 实例,在每个 metastore database 执行升级
选择 Actions > Validate Hive Metastore Schema 执行,检查 schema 是否正确
步骤 19: 启动 Hive 服务
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
启动 Hive 服务:
进入 Hive 服务
选择 Actions > Start
步骤 20: 验证 Hive Metastore Database Schema
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
验证 Hive Metastore Database Schema 过程如下:
选择 Actions > Validate Hive Metastore Schema 执行
如果有多个 Hive 实例,请在每个 Metastore 数据库上执行验证。
选择 Actions > Validate Hive Metastore Schema 执行,检查 schema 是否正确
步骤 21: 启动 Impala 服务
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
启动 Impala 服务:
进入 Impala 服务
选择 Actions > Start
步骤 22: 升级 Oozie
根据官网文档说明,需要满足如下升级条件:
CDH 5.x 升级到 6.0.0 或以上版本。
升级 Oozie 步骤如下:
进入 Impala 服务
选择 Actions > Stop
选择 Actions > Upgrade Oozie Database Schema 执行
步骤 23: 升级 Oozie SharedLib
升级 Oozie SharedLib 步骤如下:
进入 Oozie 服务
如果 Oozie 服务处于停止状态,则启动 Oozie 服务
选择 Actions > Install Oozie SharedLib 执行
步骤 24: 启动剩余的集群服务
使用滚动重启或完全重启 CDH 所有服务。
确保已启动或重新启动所有服务。
可以使用 Cloudera Manager 启动集群,也可以单独重新启动服务。Cloudera Manager 主页会显示哪些服务具有过时的配置并需要重新启动。
步骤 25: 测试升级后的集群以及 Finalize HDFS Metadata
CDH 集群升级完成后,一定要进行大规模的测试验证,涉及到每个组件,尤其日常使用的功能。在确定 Finalize HDFS Metadata 之前,一定要做足功课,而不是,一激动手抖执行了 Finalize Metadata Upgrade,如果真的有问题后,反正自己想办法吧。
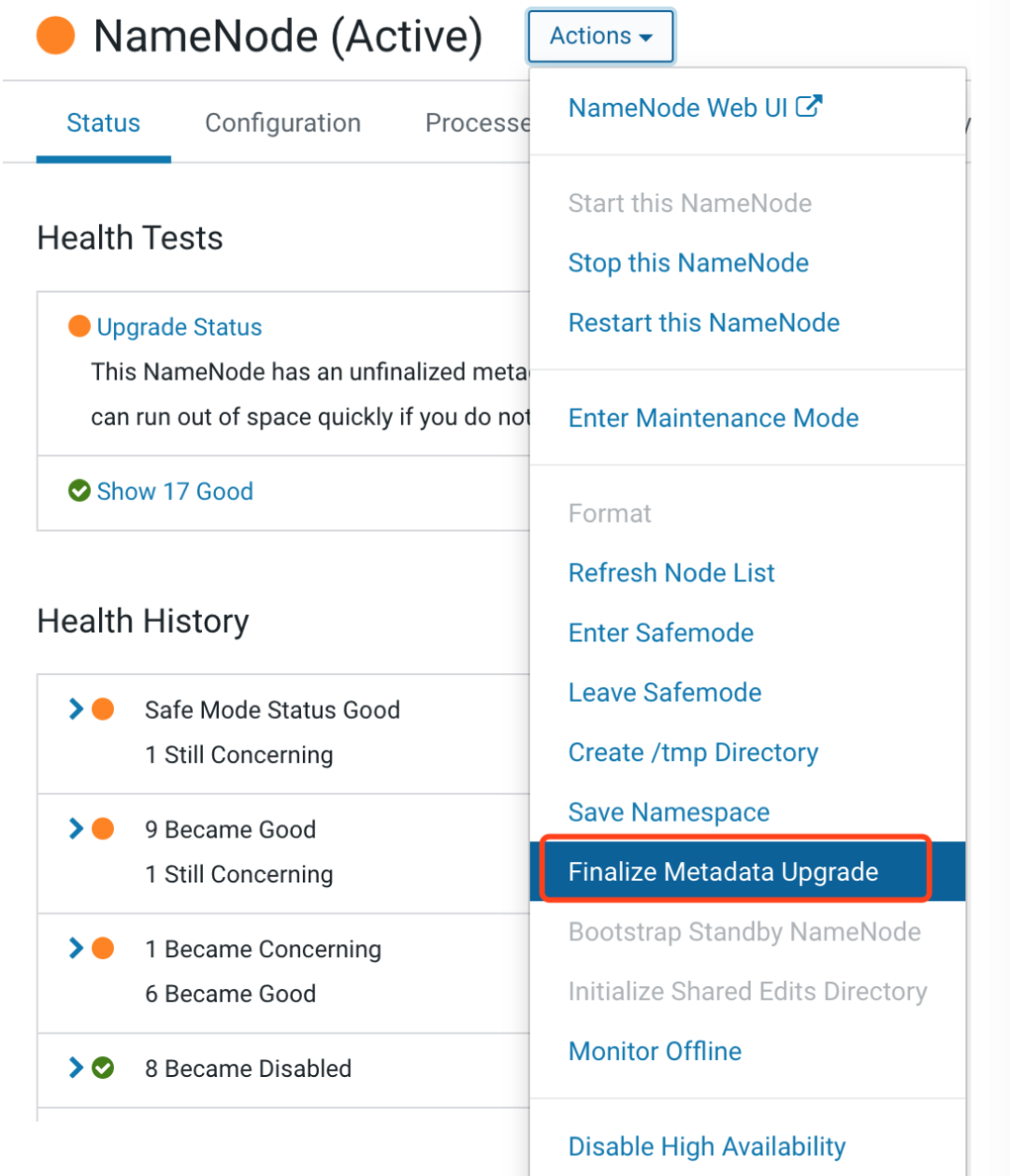
在准备好一切后,确定要 Finalize Metadata Upgrade,请执行以下操作:
进入 HDFS 服务
点击 Instances
单击 NameNode 实例的链接。如果 HDFS 启用了高可用性,请单击标记为 NameNode(Active) 的链接。
选择 Finalize Metadata Upgrade,确认执行
Troubleshooting
官方也提供了一些故障排除的方法,但是笔者升级过程并没有遇到这些问题。
https://docs.cloudera.com/documentation/enterprise/upgrade/topics/ug_cdh_upgrade_troubleshooting.html
总结
笔者在自动升级失败的前提下,采用了手动升级的方式,完成了将 CDH 集群从 5.16.2 升级到 6.3.3 版本,并解决 HDFS、HBase 和 Hive 等遇到的一些问题。另外,为了保证文章整体的阅读性,笔者并没有将升级过程后遇到的问题都记录在本篇文章中,比如 Phoenix 版本不兼容迁移,Hive 集成 Atlas 等。
奋斗吧,前浪;奔涌吧,后浪。
参考
https://docs.cloudera.com/documentation/enterprise/upgrade/topics/ug_cm_wizard_actions.html
你若喜欢,点个在看哦















 2079
2079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









