







一、全文检索
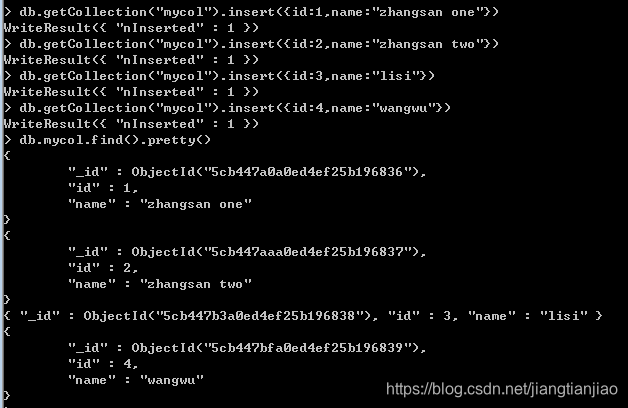
准备查询数据
对name字段建立全文索引,如果字段选择了$**,即表示全部字段。
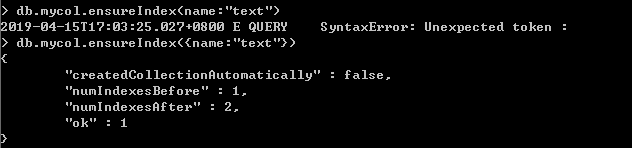
1.查询name为zhangsan的数据

2.查询name为zhangsan或lisi的数据,空格表示或关系
db.getCollection("mycol").find({$text:{$search:"zhangsan lisi"}})
3.查询name为zhangsan,排除lisi的数据,横杠表示非关系
db.getCollection("mycol").find({$text:{$search:"zhangsan -lisi"}})
4.查询name为zhangsan且name为one的数据,转义字符表示引号,如果字符加了引号即表示且关系
db.getCollection("mycol").find({$text:{$search:"\"zhangsan\" \"one\""}})
二、存在的问题及注意点?
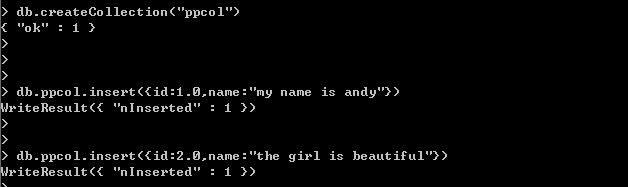
同样为name创建全文检索。
查询db.getCollection("ppcol").find({$text:{$search:"is"}})返回结果为空。
原因:is是停止词,在英语里面会遇到很多a,the,or等使用频率很高的字或词,常为冠词、介词、副词或连词等。如果搜索引擎要将这些词都索引的话,那么几乎每个网站都会被索引,也就是说工作量巨大。可以毫不夸张的说句,只要是个英文网站都会用到a或者是the。那么这些英文的词跟我们中文有什么关系呢? 在中文网站里面其实也存在大量的stopword,我们称它为停止词。比如我们前面这句话,“在”、“里面”、“也”、“的”、“它”、“为”这些词都是停止词。这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉。如果我们的网站上存在大量这样的词语,那么相当于浪费了很多资源。
对于中文的全文检索不是很友好
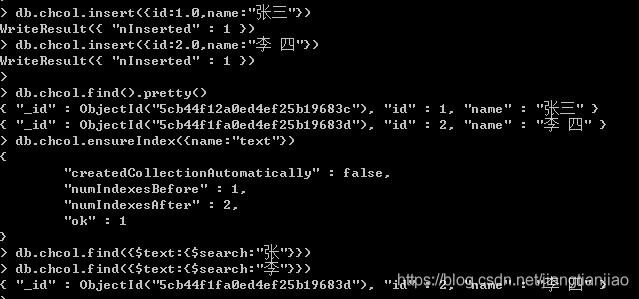
上述运行结果:检索张返回空,搜索李返回数据。
说明MongoDB中文全文索引建立方式与英文几乎相同,都是根据词(英文单词)的方式建立的。
如果一个值里面有多个值,则需要按空格方式隔开,"李 四"系统则认为是两个词。
MongodB的中文全文索引沒有想象中的强大。















 1598
1598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









